







常用协议
IP协议:是一个分组交换,不保证可靠传输。
TCP协议:传输控制协议,面向连接、可靠传输、双向通信。
TCP协议是建立在IP协议之上的,(对应TCP/IP模型)IP协议只负责发数据包,不保证顺序和正确性,而TCP协议负责控制数据包传输,它在传输数据之前需要先建立连接,建立连接后才能传输数据,传输完后还需要断开连接。TCP协议之所以能保证数据的可靠传输,是通过通信双方接收确认、超时重传这些机制实现的。并且,TCP协议允许双向通信,即通信双方可以同时发送和接收数据。
TCP协议也是应用最广泛的协议,许多高级协议都是建立在TCP协议之上的,例如HTTP、SMTP等。
UDP协议(User Datagram Protocol):一种数据报文协议,它是无连接协议,不保证可靠传输(因为UDP协议在通信前不需要建立连接,所以没有接收确认等机制,发送方只管发,不需要等待接收方返回的确认消息,所以它的传输效率比TCP高,但不保证传输的可靠,数据可能丢失),另外UDP协议比TCP协议要简单得多。
选择UDP协议时,传输的数据通常是能容忍丢失的,例如,一些语音视频通信,比如QQ。
HTTP协议是属于应用层的一个协议,我们每天都在经常接触,但当我们在浏览器中输出网址时,数据究竟是怎样在客户端和服务器端传输的呢?这需要我们了解http协议是怎样工作的。
超文本传送协议HTTP
协议就是规则,HTTP协议规定了怎样向万维网服务器请求文档,及服务器怎样把文档返回给浏览器。实际就是客户端和服务器端交互的一种通讯的格式。
- 大致工作流程如下:
- 每个万维网网点都有一个服务器进程,不断监听TCP的80端口,看是否有浏览器向他发出连接请求。
- 浏览器发起请求连接, 服务器监听到连接请求后,接受该请求并建立TCP连接。(TCP三次握手)
- 浏览器向服务器发送某个资源的请求
- 服务器返回所请求的资源对象作为响应
- 释放TCP连接(TCP四次挥手)
到现在为⽌,HTTP协议已经有四个版本了:
HTTP1.0
HTTP1.1
HTTP/2
HTTP/3
这种发送一次请求,返回响应后就断开TCP连接的叫做非持续连接,也叫短链接,即发送一次HTTP请求,就要建立一次TCP连接,这种是发出耗时的,会加重服务器负担。(因为建立一次TCP连接需要三次握手,释放需要四次挥手)。HTTP/1.0就是这种短链接的。
可以打开开发者工具,选中某一条请求,在消息头中查看HTTP版本。
HTTP/1.1使用了持续连接,就是在服务器发送响应后会在一段时间内保持该连接,使得浏览器和服务器可以继续在该连接上通信。当然该连接不会一直持续下去,会设置一个定时器,如果超过了时间浏览器还没有发送请求,就会断开连接。
HTTP/1.1的持续连接有非流水线方式(客户在收到前一个请求返回的响应后才能发送下一个请求)和流水线方式(pipelining)。
非流水线: 客户在收到响应报文之前可以接着发送请求, 这样就可以就减少TCP空闲,提高通信效率。
HTTP 1.1中还引⼊了 Chunked transfer-coding ,范围请求,实现断点续传(实际上就是利⽤HTTP消息头使⽤分块传输编码 ,将实体主体,即数据分块传输)。
至于HTTP/2,又新增了很多东西,HTTP/2 is the future of the Web.
- HTTP使用了TCP作为传输层协议,TCP是面向连接,安全可靠的。但HTTP本身是无连接的,及在交换HTTP报文之前,通信双方是不需要建立HTTP连接的。
- HTTP协议是无状态的。意思就是没有记忆力,当用户发送⼀次HTTP请求后,再发送⼀次HTTP请求,HTTP并不知道当前客户端是⼀个”⽼⽤户“。这样做的优点是:简化了服务器的设计,使服务器可以接收大量并发的HTTP请求,提高了效率。
但是互联网怎么可能没有“记忆”,如果没有记忆,不知道该请求是哪一个用户操作的会很可怕。所以使用Cookie来跟踪用户。
Cookie
Cookie就相当于⼀个通⾏证,当用户第一次浏览某个使用Cookie的网站时,服务器就会给用户A参数一个唯一的”识别码“,并将该识别码放到响应报文中,即添加一个首部行:
Set-cookie:识别码
当用户A再次浏览时,就会从他的Cookie文件中取出这个识别码,放到HTTP请求报文中,即添加首部行:
Cookie:识别码
那么服务器就知道这个是”⽼⽤户“。如果用户A在几天后继续使用同一个电脑访问该网站,那么浏览器会在HTTP请求报文中继续使用该Cookie,并且服务器还可以根据A以前的访问记录向用户A推荐商品。
这也是我们在生活经常遇见的。比如,我第一次登陆了某个网站,就比如优快云吧,这时需要填写登录信息,账号,密码。但几天后我再次在浏览器输入该网站时,直接跳转到该登陆后的界面,就不需要再次登录了,这就是因为HTTP请求报文中携带了同样的Cookie首部行,所以服务器可以验证出我们是”老用户“。
万维网文档
1、超文本标记语言HTML
说到html大家都很熟悉了,不就是网页嘛。其实准确来说,html是制作万维网页面(网页)的标准语言。HTML并不是应用层的协议,它只是浏览器使用的一种语言。
2、XML可扩展标记语言
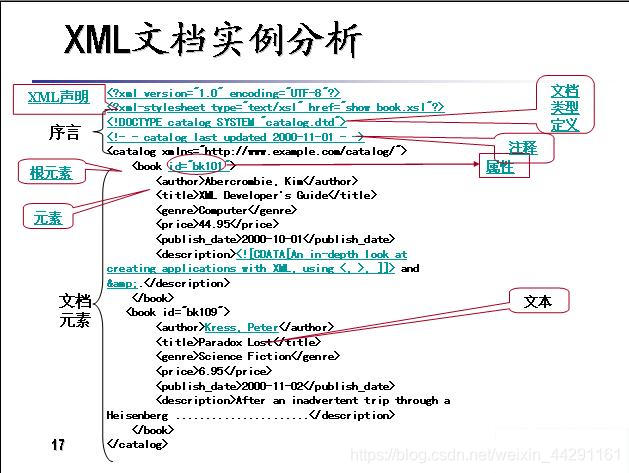 看上面的图片是不是觉得XML和HTML很相似,
看上面的图片是不是觉得XML和HTML很相似,
是的,XML和HTML结构很像,但也很大的不同。XML是为了传输数据,描述数据,而不是显示数据。
就像下面的XML图片就很好的描述了一组数据。
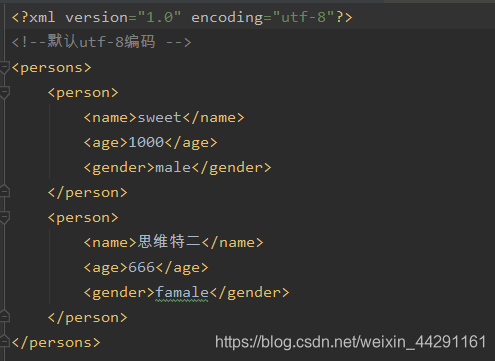
- 用户可以无限制地自定义XML标记,如上面图片种的可以根据用户需要自定义,而在html种必须使用指定的标签和格式,比如等等。因此XML可以集成各种不同来源和类型的数据,使其呈现结构化,更好的在万维网上传输和交换。
XML的简单使其易于在任何应用程序中读写数据,这使XML很快成为数据交换的唯一公共语言,虽然不同的应用软件也支持其它的数据交换格式,比如JSON,但不久之后他们都将支持XML,程序可以更容易加载XML数据到程序中并进行分析操作,然后以XML格式输出结果。
至于这样自定义标记的语言怎么被程序识别,就需要用到XML解析了。
-
XML是平台无关的,并且将用户界面和数据分离了,所以是不依赖浏览器的。
-
XML也常用来描述数据,存储的软件参数,我们看见的配置文件常以.xml作为文件名。
-
作为存储数据,XML不同于Acess,SQLSever等数据库除了存储数据还可以进行增删改查等操作,XML只是以文本的形式显示存储数据,没有其他复杂的功能。
-
可以通过浏览器验证XML文件的正确性。如下图,格式准确
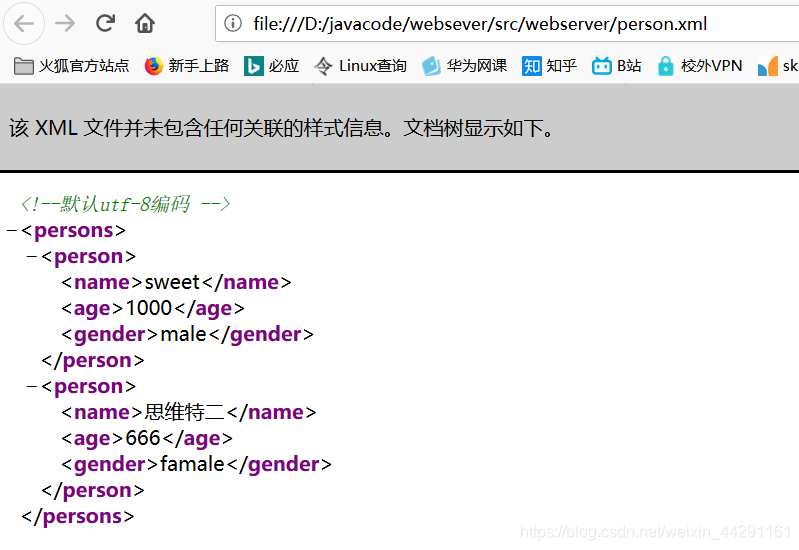
如果格式错误,浏览器会报错。
XML解析
XML有两种解析方式:DOM和 SAX。
- DOM :这个在HTML中就应该熟悉了, 文档的树形结构。DOM解析是一次将整个文档树加载到内存中,然后从根节点开始依次遍历进行解析,可想而知这样占用内存,但是解析方便。
- SAX :流解析。从文档头到文档尾,以流的方式,边读边解析。因此无论XML有多大,占用的内存都很小。
package webserver;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.IOException;
import java.util.Objects;
/**
* 利用Sax进行解析XML文档------->流解析,从文档上到下
* 1、获取解析工厂
* 2、从工厂获取解析器
* 3、加载文档Docunment注册处理器
* 4、编写处理器----->核心
* 5、解析
* */
public class Sax {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1、获取解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2、从工厂获取解析器
SAXParser parse = factory.newSAXParser();
//3、编写处理器----->核心,这里写了一个类
//4、加载文档Docunment注册处理器
MyHander handler = new MyHander();
//5、解析
parse.parse(Main.class
.getResourceAsStream("webserver/person.xml")),handler);
}
}
//处理器
class MyHander extends DefaultHandler{
@Override
public void startDocument() throws SAXException {
System.out.println("解析开始");
}
@Override
//解析每一个标签
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println(qName+"标签开始解析"); //qname为内容
}
@Override
//Receive notification of character data inside an element.解析内容
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.println("内容为: "+new String(ch,start,length));
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println(qName+"标签解析完成");
}
@Override
public void endDocument() throws SAXException {
System.out.println("解析完成");
}
}
3、JSON
(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写,也易于机器解析和生成。
JSON也可以存储其他类型的数据,比如对象,数组啊,但总的来说,扩展性不如XML。从名字可以看出来,json和javaScript经常打交道,JSON 是 JS 对象的字符串表示法,它使用文本表示一个 JS 对象的信息,本质是一个字符串。常用来存储JS对象。
相比XML的重量级,JSON语法格式更简单,层次结构更清晰,所以明显要比 XML 容易阅读,并且在数据交换时JSON 使用更少的字符,可以节约传输数据所占用的带宽。xml的解析也更复杂。但总的来说,XML有更广阔的适用领域。
下面是XML和JSON的示例

4、动态文档
上面所说的html页面,xml,json都是静态文档。静态文档在生成后存放到服务器中,其内容是不会改变的。
但我们日常接触的网页都是实时刷新的,并且有的内容是根据用户生成的唯一的页面,比如,常见 的网页中的个人中心,这些文档都是在用户登陆后才由应用程序动态生成的,不是一开始就存在服务器里面的。
动态文档的开发很复杂,不只是写写html文档就行,还涉及到应用程序的编写。
从浏览器看,静态文档和动态稳文档,在呈现的页面上没有差别,都遵循HTML格式。两者的差异主要体现在服务器端上生成文档内容的方式不同。
动态文档由服务器中的应用程序(CGI程序)创建。该程序遵循CGI标准。流程如下:服务器将浏览器发来的数据传送给CGI应用程序,CGI根据这些数据来创建动态文档,服务器将应用程序的输出进行解释,向浏览器返回HTML文档。
5、活动万维网文档
动态文档一旦创建后,其内容也是固定了的,并且无法提供动画之类刷新屏幕的效果。所以需要新的技术来实现浏览器屏幕的持续更新。
- 一是服务器推送(push) 。这种是将工作交给服务器,服务器端不断运行与动态文档相关的应用持续,定期更新。但是这样会加大服务器负担
- 二是活动文档,把所有工作交给浏览器。当浏览器请求一个活动文档时,服务器会发回一个程序副本,让该副本在浏览器端运行,并且可以直接实现和用户的交互。
活动文档不需要和服务器持续地传送更新的文档,也节约了带宽。
JAVA语言是一项用于创建和运行活动文档的技术。Java网络编程中,通过TomCat服务器作为一个Servlet和JSP容器运行在后端,执行某些操作来生成动态文档返回给浏览器的。这里插播一个图,可以更好的理解。
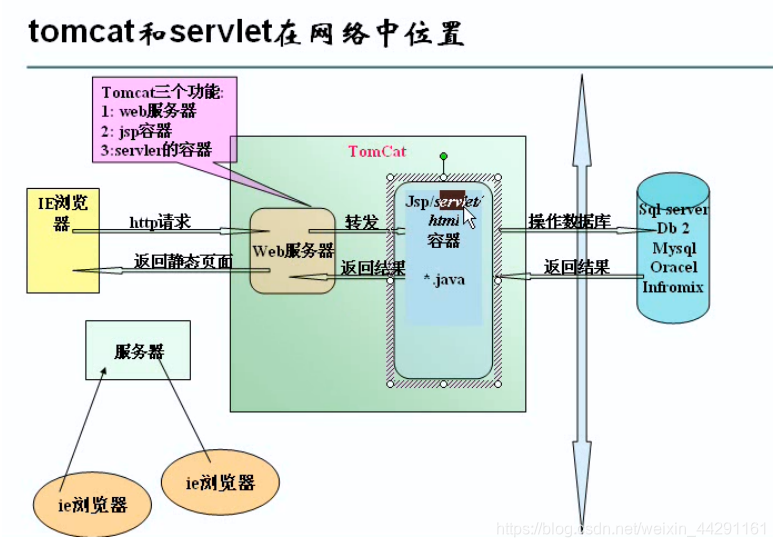
- Socket套接字
套接字是传输层为应用层开的一个小口,应用程序通过这个小口,向远程发送数据,接收远程传来的数据。
Socket编程由两种,一种是居于UDP协议,一种基于TCP协议。下面代码展示的是基于TCP的连接。
主要流程:
1.服务器端创建ServerSocket,在指定端口监听客户端的连接请求
2.客户端创建Socket,向服务器端发送请求
3.服务器accept请求,建立连接
4.客户端发送服务请求,传送数据
5.服务器端接收请求并处理,返回结果给客户端
6 关闭流和Socket对象
下面代码展示了JAVA中如何利用TCP编程进行简单的用户登录。
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
public class Server {
public Server() {
}
public static void main(String[] args) throws IOException {
ServerSocket server = new ServerSocket(8888); //指定端口接收请求
Socket client = server.accept(); //接收连接请求,客户端和服务器端的连接就建立起来了
DataInputStream dis = new DataInputStream(client.getInputStream()); //接收客户端发来的请求,读数据
String username = dis.readUTF(); //读取用户名
String password = dis.readUTF(); //读取密码
DataOutputStream dos = new DataOutputStream(client.getOutputStream()); //向客户端发送响应,写数据
if (username.equals("思维特儿") && password.equals("12345678")) {
dos.writeUTF("登录成功,欢迎回来");
} else {
dos.writeUTF("用户名或密码错误");
}
dos.close(); //关闭流
dis.close();
}
}
下面是客户端
//导入相关类
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.Socket;
//客户端
public class Client {
public Client() { //无参构造器,JDK9之后要求加上
}
public static void main(String[] args) throws IOException {
Socket client = new Socket("localhost", 8888); //绑定服务器的IP地址和指定端口
DataOutputStream dos = new DataOutputStream(client.getOutputStream()); //向服务器端发送请求,写数据
BufferedReader info = new BufferedReader(new InputStreamReader(System.in)); //读取用户的输入
System.out.println("请输入用户名:");
String username = info.readLine();
System.out.println("密码:");
String password = info.readLine();
dos.writeUTF(username);
dos.writeUTF(password);
info.close();
dos.flush();
DataInputStream dis = new DataInputStream(client.getInputStream()); //读取服务器端返回的响应,读数据
String result = dis.readUTF();
System.out.println(result);
dis.close();
dos.close(); //关闭流
}
}
注意:要先运行服务器端,程序才能跑起来。另外在关闭流时,最后在IO流要读写操作都完成后再一起关闭,不然关闭IO流时,Socket流也会关闭,就会报Socket is closed 错误。亲测是这样。。。
下面代码展示了JAVA中如何实现HTTP请求
//ava标准库提供了基于HTTP的包
import java.net.URI;
import java.net.URISyntaxException;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.nio.charset.StandardCharsets;
import java.time.Duration;
import java.util.List;
import java.util.Map;
import java.io.IOException;
/**
* 早期的JDK版本是通过HttpURLConnection访问HTTP,
* 新版使用HttpClient,链式调用并通过内置的BodyPublishers和BodyHandlers来更方便地发送和处理数据。
//---------以下是Get请求方式-------
public class httpClient {
//全局HttpClient实例
static HttpClient client = HttpClient.newBuilder().build(); //实例化
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
String url = "https://www.baidu.com";
HttpRequest request = HttpRequest.newBuilder(new URI(url))
.header("User-Agent","java httpclient") //客户端自身标识信息,服务器依靠User-Agent判断// 客户端类型;
//接收什么类型的内容
.headers("Accept","*/*")
//设置超时,5秒
.timeout(Duration.ofSeconds(5))
//设置HTTP版本
.version(HttpClient.Version.HTTP_2).build();
HttpResponse<String> response = client.send(request,
HttpResponse.BodyHandlers.ofString()); //获取字符串
//如果是二进制内容,如图片,换成HttpResponse.BodyHandlers.ofByteArray(),获得一个HttpResponse<byte[]>对象。
Map<String, List<String>> headers = response.headers().map();
for(String header : headers.keySet()){
System.out.println(header+headers.get(header).get(0)); //只输出每个header的第一个值
}
//GET请求,只有HTTP Header,没有HTTP Body。
// POST请求,带有HTTP Header 和 Body,以一个空行分隔
//响应都有body
System.out.println(response.body().substring(0,1024)+"....."); //输出响应体的前一个字节欸等内容
}
}
结果如下:
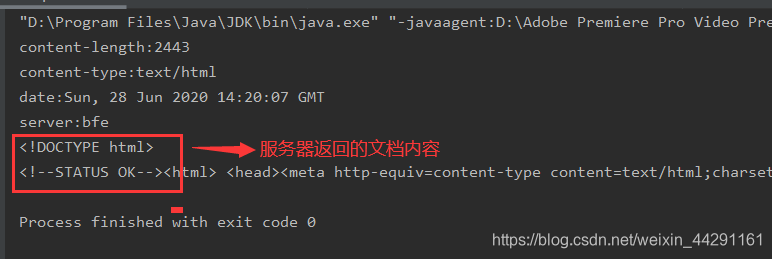
下面是POST请求方式
public class httpClient {
//全局HttpClient实例
static HttpClient client = HttpClient.newBuilder().build(); //实例化
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
//要发送POST请求,就要准备请求的HTTP Body 并正确设置Content-Type
String url = "http://eol.sicau.edu.cn/Login"; //课程平台
String body = "username=201803&password=123456";
HttpRequest request = HttpRequest.newBuilder(new URI(url))
.header("User-Agent","java httpclient") //客户端自身标识信息,服务器依靠User-Agent判断客户端类型;
//接收什么类型的内容,"*/*"表示任意格式
.headers("Accept","*/*")
.header("Content-Type","application/x-www-form-urlencoded")
//设置超时,5秒
.timeout(Duration.ofSeconds(5))
//设置HTTP版本
.version(HttpClient.Version.HTTP_2)
//使用POST 设置Body
.POST(HttpRequest.BodyPublishers.ofString(body, StandardCharsets.UTF_8))
.build();
HttpResponse<String> response = client.send(request,
HttpResponse.BodyHandlers.ofString()); //获取字符串
//如果是二进制内容,如图片,就要换成HttpResponse.BodyHandlers.ofByteArray(),获得一个HttpResponse<byte[]>对象。
Map<String, List<String>> headers = response.headers().map();
for(String header : headers.keySet()){
System.out.println(header+":"+headers.get(header).get(0)); //只输出每个header的第一个值
}
//GET请求,只有HTTP Header,没有HTTP Body。
// POST请求,带有HTTP Header 和 Body,以一个空行分隔
//响应都有body
System.out.println(response.body().substring(0,1024)+"....."); //输出响应体的前一个字节的内容
}
}
运行效果截图
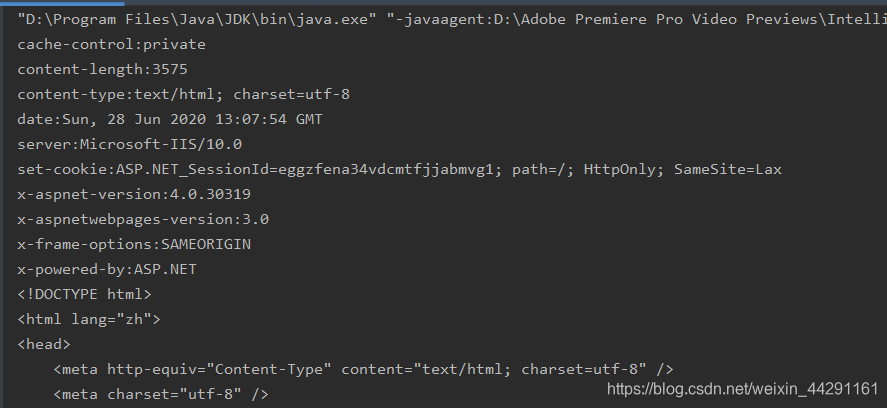
关于JavaWeb 这一块儿还有很多知识要学习,比如Tomcat,Servlet,Spring等等其中更复杂,所以需要打好HTTP还有关于网络这一块儿的基础知识。

















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









