







Attention注意力模型的强大应用
起初,我们用encoder,decoder来encode语句到语义上, 再decode语义到下游任务中。
比如:
- 输入是中文,输出是英文,这就是翻译系统。
- 输入是文章,输出时摘要,这就是摘要系统。
- 输入是问题,输出是答案,这就是QA问答系统,对话机器人。
- 输入是图片,输出是文字,这就是图片自动描述系统。
- 输入是语音,输出是文字,这就是ASR系统。
Encoder-decoder的缺陷:所有的输入词的权重都是一样的,没有区别。
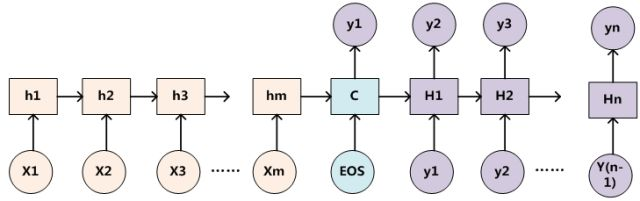
无attention:
encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state向量,再由state向量来循环输出序列每个字符。
Soft Attention机制:
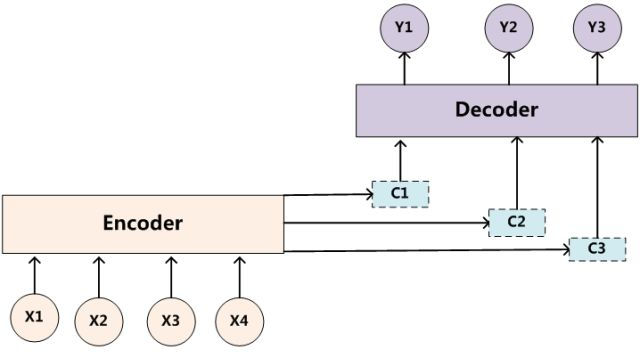
将整个序列的信息压缩在一维向量里造成信息丢失,并且考虑到输出的某个字符只与输入序列的某个或某几个相关,与其他输入字符不相关或相关性较弱,由此提出了attention机制。在encoder层将输入序列的每个字符output向量以不同权重进行组合再decode输出字符,每需要输出一个字符,encoder层权重序列都会变,这就可以理解为需要输出的字符是由哪些或那个字符影响最大,这就是注意力机制。
以自动翻译为例,在翻译到目标文本的每个词时,encoder出来的语义Ci都会跟着变化,因为source里的每个单词对当前要翻译的词的贡献度不同
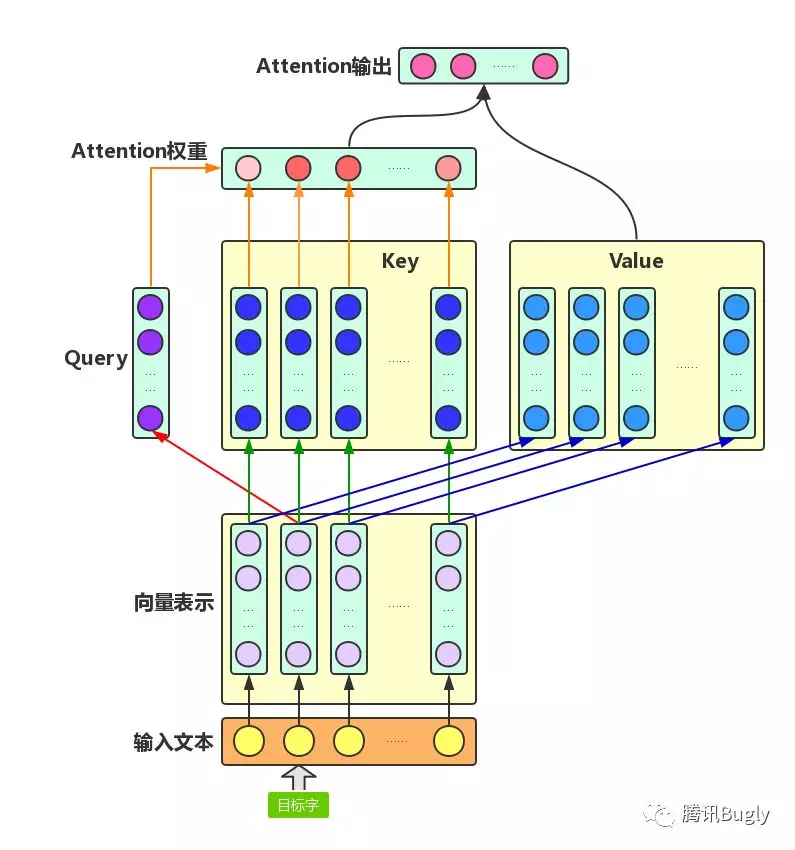
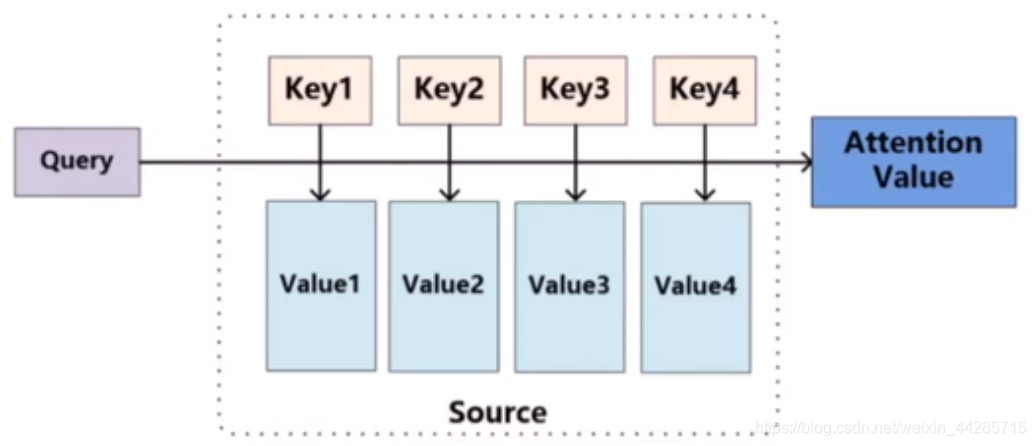
Attention机制主要涉及到三个概念:Query、Key和Value。
在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重,加权融合目标字的Value向量和各个上下文字的Value向量,作为Attention的输出,即:目标字的增强语义向量表示。
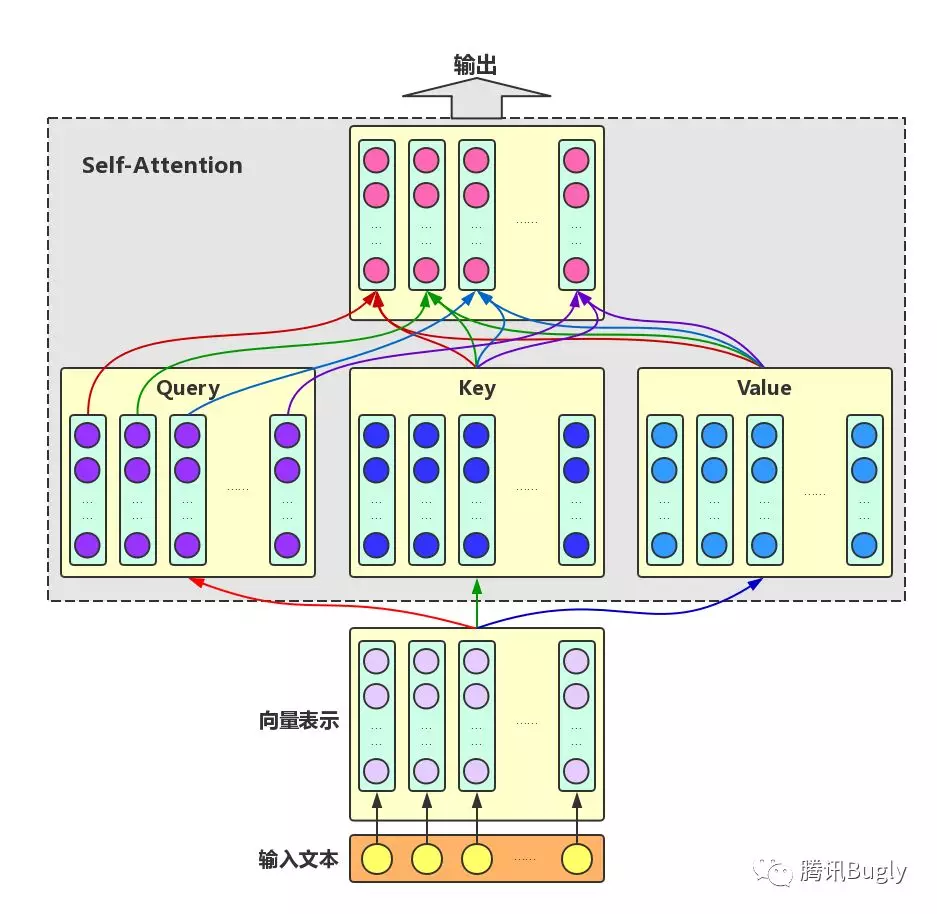
self-attention
self-attention来自于google文章《attention is all you need》。 一个序列每个字符对其上下文字符的影响作用都不同,每个字对序列的语义信息贡献也不同,可以通过一种机制将原输入序列中字符向量通过加权融合序列中所有字符的语义向量信息来产生新的向量,即增强了原语义信息。
Self-Attention:对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。
- transformer已经基本取代RNN
- self-attention机制用来进行并行计算,
1、self-attention如何计算?
三个需要训练的矩阵Wq,Wk,Wv
- Q: query要去查询的
- K:key等着被查的
- V:value实际的特征信息
q与k的内积表示有多匹配(相关性越大,内积越大)
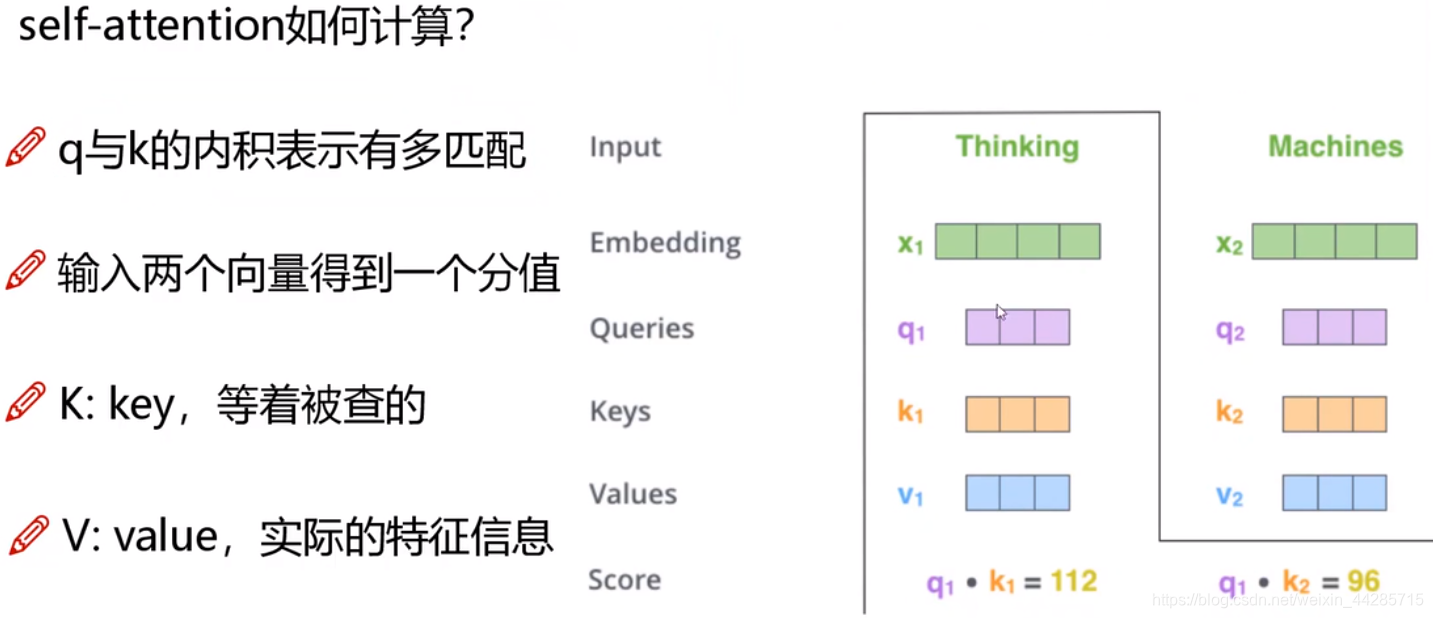
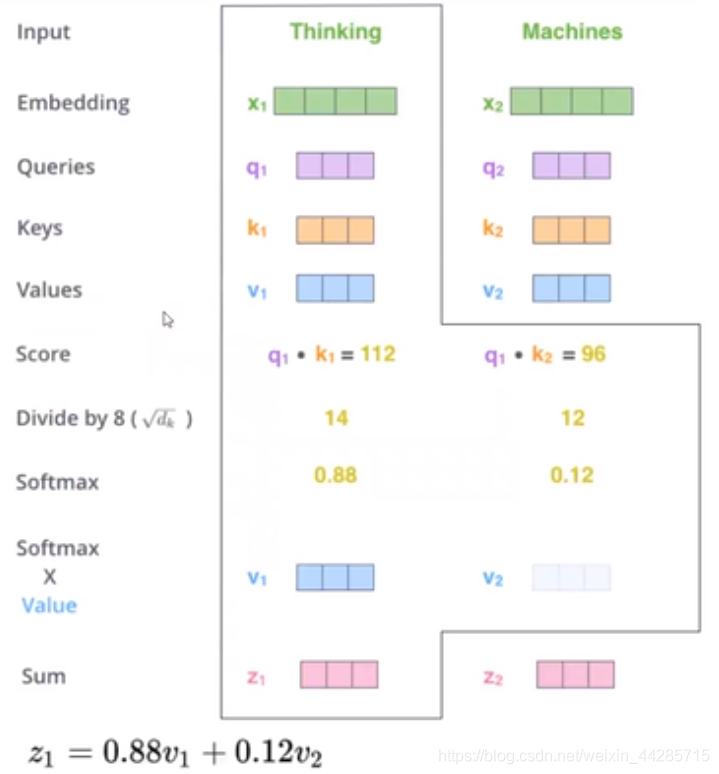
q1·k1=score1
q1·k2=score2
q2·k1=score3
q2·k2=score4
得到的分值(score)经过softmax得到最终上下文结果(是一个比例)
softmax流程:exp -> normalize ->
例:m1 = e^(score1) -> m1/(m1+m2+...) ->得到一个比例
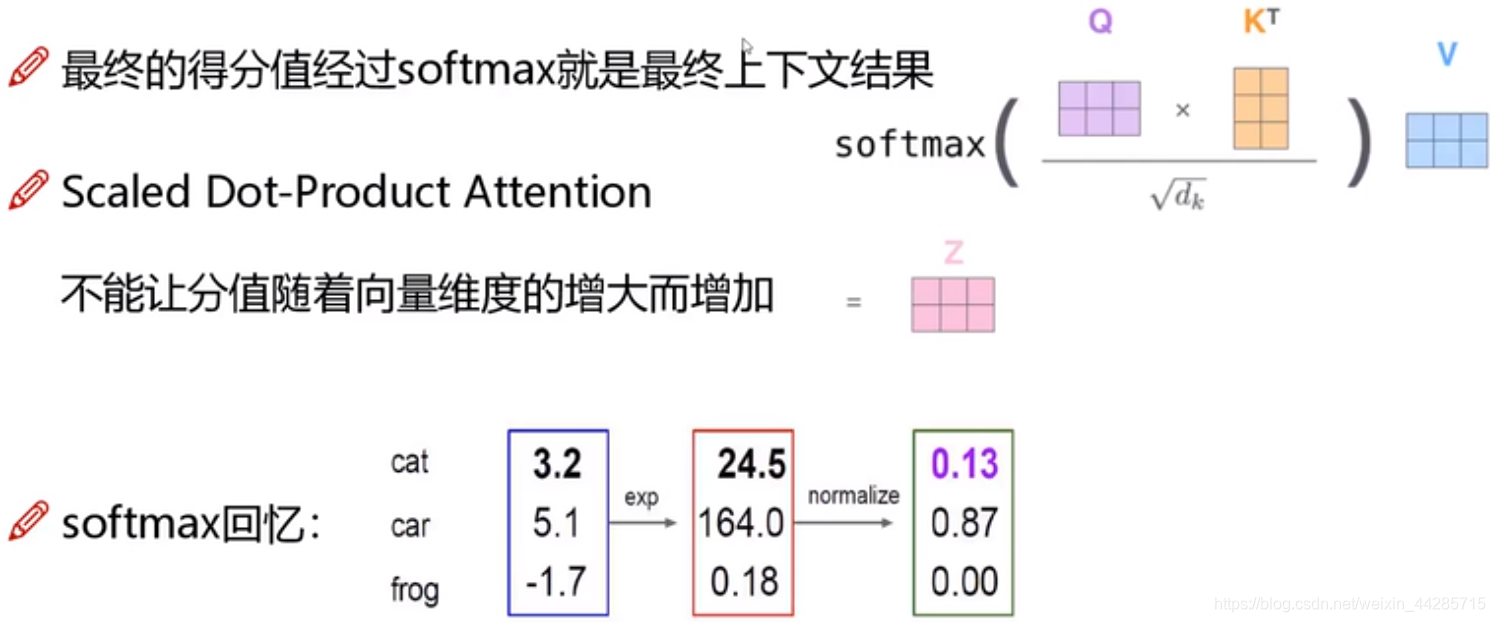
softmax*value
即:
z1 = 0.88v1 + 0.12v2
2、计算过程可以并行计算(加速训练)。
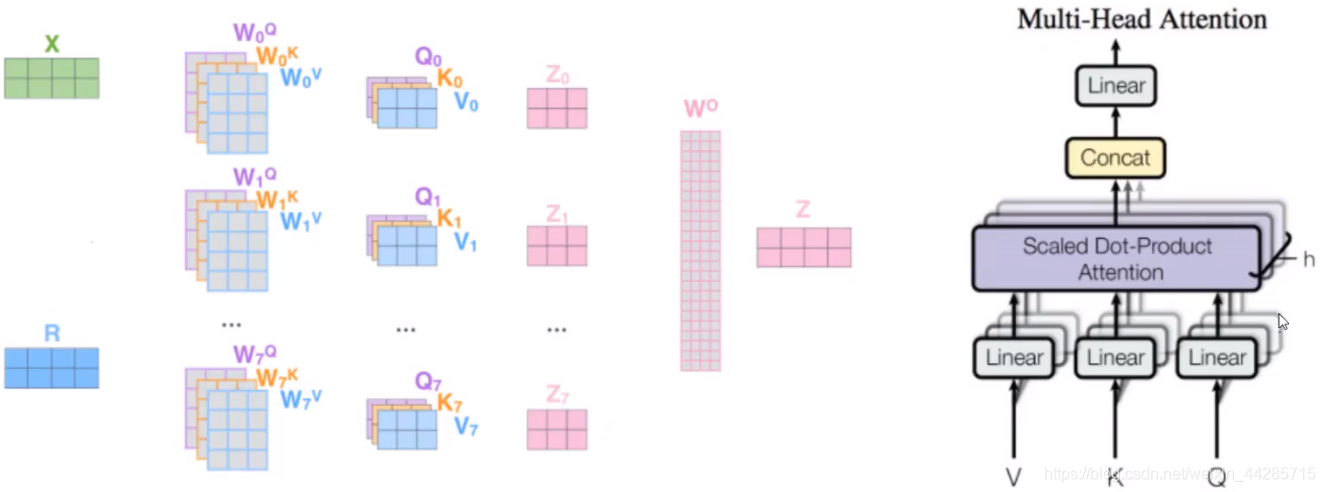
3、multi-head self-attention
一组q,k,v得到了一组当前词的特征表达。
类似卷积神经网络中的filter,能不能提取多组特征?
multi-head机制:(一般8个)
通过不同的head得到多个特征表达,将所有特征拼接在一起。通过再一层 全连接(concat) 来降维(得到是向量)。
结果:不同的注意力结果,得到的特征向量表达也不同。
4、堆叠多层,位置编码
mask机制(不能提前透露待预测的)
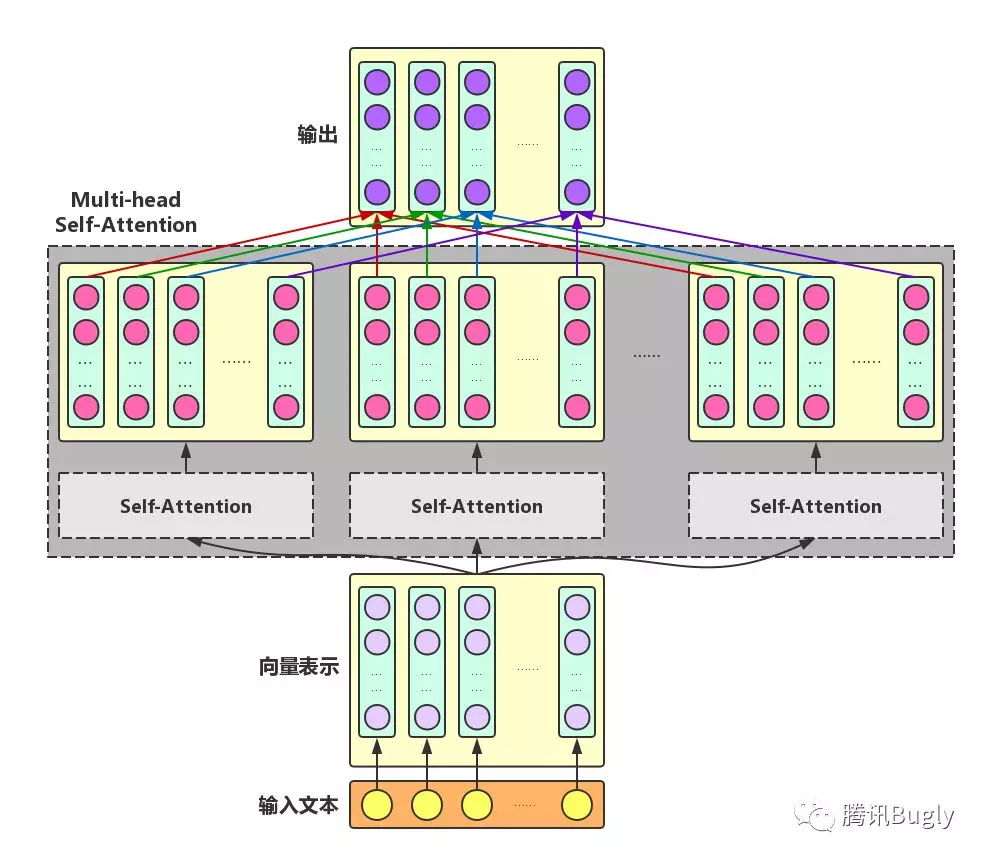
Multi-head Self-Attention
为了增强Attention的多样性,文章作者进一步利用不同的Self-Attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量,如下图所示。

















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









