







文本处理流程
- 原始文本(raw data)
- 分词(segmentation)、spell correction
- 清洗(cleaning)无用标签、特殊符号、停用词、大小写
- 标准化(normalization)stemming、lemmatization
- 特征提取(feature extraction)tf-idf、word2vec
- 建模(modeling)相似度算法、分类算法
1、分词
1、Segmentation method1:Max Matching(最大匹配)
forward-Max Matching(前向最大匹配)
例子:我们经常有意见分歧
词典:[“我们”,“经常”,“有”,“有意见”,“意见”,“分歧”]
取max_len = 5
我们经常有(×)
我们经常(×)
我们经(×)
我们(√)
经常有意见(×)
经常有意(×)
经常有(×)
经常(√)
有意见分歧(×)
有意见分(×)
有意见(√)
分歧(√)backward-Max Matching(后向最大匹配)
取max_len = 5
有意见分歧(×)
意见分歧(×)
见分歧(×)
分歧(√)
经常有意见(×)
常有意见(×)
有意见(√)
我们经常(×)
们经常(×)
经常(√)
我们(√)2、Segmentation method2:Incorporate Semantic(考虑语义)
思路:输入 ——> 生成所有可能的分割 ——> 选择其中最好的(概率值最大的,或找到 min -log() )
工具:language model(unigram language model)
在概率的计算过程中,会出现-inf、Now,这都是表示underflow溢出
可以加一个log:logp(x1)+logp(x2)+...
viterbi algorithm(维特比)

3、Word Segmentation
Summary
基于匹配规则的方法
基于概率统计方法(LM,HMM,CRF...)
2、Spell Correction(拼写错误纠正)
1、编辑距离(edit distance)
Find the words with smallest edit distance between input and candidates:
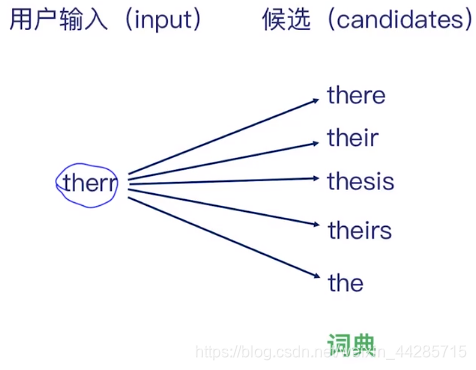
r-->e(1个成本)
r-->i(1个成本)
r-->s r-->i 加s(3个成本,2 replace and 1 add)
r-->i 加s(2个成本)
去掉2个(2个成本)
时间复杂度:O(v)*Edit()
改进方法:
生成编辑距离为1、2的字符串 ——> 过滤 ——> 返回
假设用户输入appl
Replace:bppl,cppl......aapl,abpl......
Add:aappl,bappl......abppl,acppl......
Delete:ppl,apl,app
给定一个字符串s,要找出最有可能的正确字符串c
c' = arg max p(c|s),其中c∈candidates
p(c|s) = [p(c)*p(s|c)] / p(s),p(s)可看做常数项。
c' = arg max p(c)*p(s|c)
- p(s|c):对于一个正确的字符串,有多少人写成了s的形式
- p(c):unigram probability
3、Filtering Words
1、Removing Stop Words
low frequency words,可以利用nltk
2、stemming:one way to normalize(标准化)词干提取
went, go, going——>go
fly, flies——>fly
fast, faster, fastest——>fast
also have another :lemmatization(词性还原)
walking——>walk
plastered——>plaster
operator——>operate

















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









