






👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【Python】Python人民的名义-词云-关系图可视化(源码+报告)【独一无二】
一、设计要求
功能点及设计需求
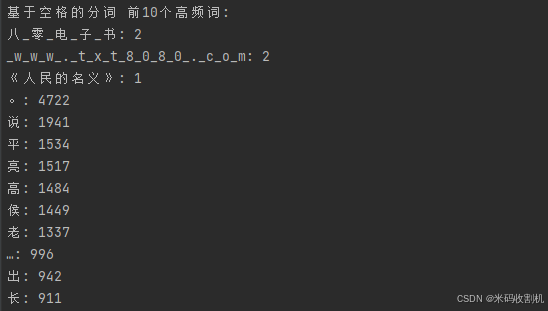
该项目的设计旨在生成《人民的名义》文本的词云和人物关系图,通过分析文本和可视化结果,展示主要人物的关联和词频情况。具体功能点和设计需求如下:
-
文本读取与处理:
- 读取文本文件:从指定路径读取《人民的名义》文本内容,确保文件编码为
gbk。 - 读取停用词文件:从指定路径读取停用词列表,文件编码为
utf-8。
- 读取文本文件:从指定路径读取《人民的名义》文本内容,确保文件编码为
-
中文分词:
- 分词处理:使用
jieba对读取的文本进行分词,处理中文字符以生成单词列表。 - 去除停用词:过滤掉单词列表中的停用词,确保词云中只包含有效信息。
- 分词处理:使用
-
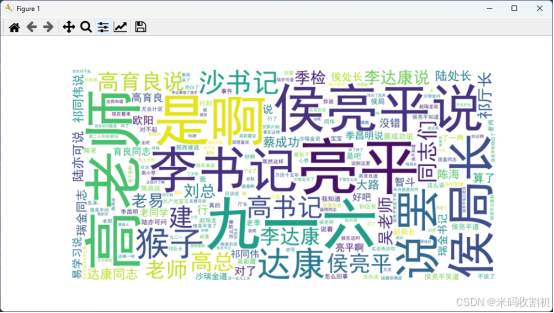
词云生成:
- 生成词云:利用
WordCloud库生成词云图,设置词云图的字体、尺寸和背景颜色,确保中文字符显示正确。 - 词云显示:使用
matplotlib显示生成的词云图,图像清晰,标签正确。
- 生成词云:利用
-
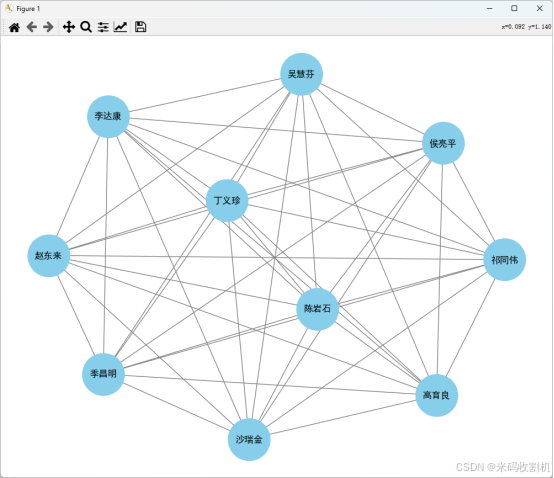
人物关系图绘制:
- 创建无向图:使用
networkx创建人物关系的无向图,定义主要人物为节点。 - 添加关系边:假设每个人物之间都有直接关系,添加边连接所有节点。
- 图形绘制:使用
matplotlib绘制人物关系图,设置节点位置、颜色、大小和标签,确保图形美观且易于理解。
- 创建无向图:使用
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 人民 ” 获取,拿来即用。👈👈👈
二、设计思路
设计目的是生成一部电视剧《人民的名义》的词云和人物关系图。代码主要分为三个部分:生成词云、绘制人物关系图和主程序调用。以下是详细的设计思路分析:
1. 导入必要的库
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
import networkx as nx
matplotlib.pyplot:用于绘制词云和人物关系图。WordCloud:用于生成词云。jieba:用于中文分词。networkx:用于创建和绘制人物关系图。
2. 配置 Matplotlib 以正常显示中文和负号
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 人民 ” 获取,拿来即用。👈👈👈
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
font.sans-serif设置为SimHei(黑体),确保能够显示中文字符。axes.unicode_minus设置为False,确保负号可以正常显示。
3. 生成词云的函数
功能描述:读取文本文件并生成词云。
def generate_wordcloud(text_file, stopwords_file):
# 读取文本文件
with open(text_file, 'r', encoding='gbk') as f:
text = f.read()
# 代码略(至少十行)...
# 代码略(至少十行)...
# 去除停用词
words = [word for word in words if word not in stopwords]
# 代码略(至少十行)...
# 代码略(至少十行)...
# 显示词云
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 人民 ” 获取,拿来即用。👈👈👈
- 读取文本文件:使用
open函数读取指定编码的文本文件内容。 - 读取停用词文件:读取停用词文件并将其转换为集合。
- 分词:使用
jieba.lcut对文本进行分词。 - 去除停用词:过滤掉停用词。
- 生成词云:使用
WordCloud类生成词云,并设置中文字体文件路径、宽度、高度和背景颜色。 - 显示词云:使用
matplotlib显示词云。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 人民 ” 获取,拿来即用。👈👈👈
4. 绘制人物关系图的函数
功能描述:绘制电视剧人物之间的关系图。
def plot_character_graph(characters):
# 创建无向图
G = nx.Graph()
# 代码略(至少十行)...
# 代码略(至少十行)...
# 绘制图形
plt.figure(figsize=(10, 8))
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_color='skyblue', node_size=3000, font_size=12, font_weight='bold', edge_color='gray')
plt.show()
- 创建无向图:使用
networkx创建无向图G。 - 添加节点:将每个人物作为节点添加到图中。
- 添加边:假设每个人物之间都有直接关系,添加边。
- 绘制图形:使用
matplotlib绘制图形,设置节点位置、标签、颜色、大小、字体和边颜色。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 人民 ” 获取,拿来即用。👈👈👈
5. 主程序调用
功能描述:读取文件路径和人物列表,生成词云和人物关系图。
# 文件路径
text_file = '人民的名义.txt'
stopwords_file = 'stop_words.txt'
# 人物列表
characters = [
"李达康",
"侯亮平",
"高育良",
"陈岩石",
"祁同伟",
"赵东来",
"沙瑞金",
"丁义珍",
"季昌明",
"吴慧芬"
]
# 代码略(至少十行)...
# 代码略(至少十行)...
- 文件路径:定义文本文件和停用词文件的路径。
- 人物列表:定义电视剧中的人物列表。
- 生成词云:调用
generate_wordcloud函数,生成并显示词云。 - 绘制人物关系图:调用
plot_character_graph函数,绘制并显示人物关系图。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 人民 ” 获取,拿来即用。👈👈👈
总结
- 导入必要的库:引入词云生成、中文分词和图形绘制所需的库。
- 配置 Matplotlib:确保能够正确显示中文字符和负号。
- 生成词云:读取文本和停用词文件,进行中文分词,生成并显示词云。
- 绘制人物关系图:创建无向图,添加节点和边,绘制并显示人物关系图。
- 主程序调用:定义文件路径和人物列表,生成词云和人物关系图。
该设计实现了一个简单的文本分析和可视化工具,可以对《人民的名义》文本进行词频分析,并展示主要人物之间的关系。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 人民 ” 获取,拿来即用。👈👈👈


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











