







一 模型背景知识
今天继续在mindspore平台上进行学习,主要内容为GPT2.0结构和微调进行学习,GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的语言模型,通过在大量的文本数据上进行预训练,旨在学习语言的一般模式和特征,从而通过微调就可以用于生成文本、完成自然语言处理任务等。
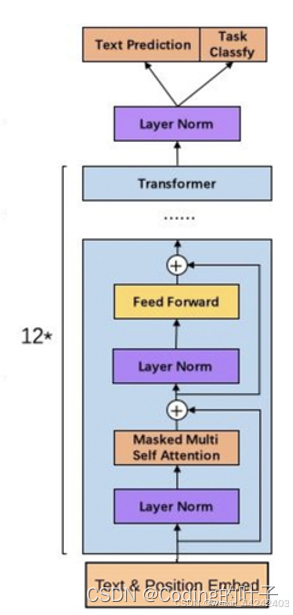
上文介绍的GPT 1.0是最早的版本,是于2018年发布,其基于12层的Transformer 编码结构堆叠而成的架构,拥有1.5亿个参数。GPT 1.0在训练时使用了逐词预测(word-by-word)的方式,即在训练过程中对下一个词进行预测。但由于模型规模的限制,1.0的生成结果缺乏准确性和一致性,并且对于复杂的句子结构和语义理解的能力有所不足。
GPT 2.0是在2019年发布的更新版本,使用了更大的模型规模和更多的训练数据。GPT 2.0采用了24层的Transformer架构,规模比GPT 1.0大10倍或更多。GPT 2.0在预训练任务过程中也进行了改进,引入了掩码语言建模(masked language modeling)的方式,即通过预测部分输入文本中被掩盖的词语来训练模型。
知识点区分:
①条件任务:以往的语言模型,是依据输入决定输出,在2.0训练中,期望加入条件,进行训练,使得模型能够针对不同的条件做出对应的回答,诸如下文翻译任务和摘要生成任务通过<任务标识>来标注
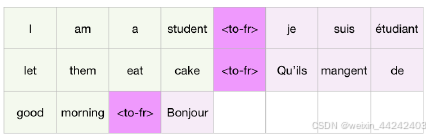

②zero shot learn and zero shot learn transfer
Zero-shot learning(零样本学习)是指在没有任何已标注样本的情况下,通过学习和推理能够对新的未见过的类别进行分类的能力。这种学习方法通过利用已知的属性或特征来进行分类,并将这些属性应用到未见过的类别中,也就是泛化能力。
Zero-shot learning transfer(零样本学习迁移)是指将已学习的知识或模型应用于新的任务或问题的过程。在零样本学习迁移中,我们通过使用从一个任务或领域学习到的知识,来帮助解决另一个任务或领域的问题,而无需额外的标记样本,也就是在前期预训练时使用无监督学习,并让模型去理解问题条件,而不是直接标注出来。
二 实验数据
本次实验使用的是nlpcc2017摘要数据,内容为新闻正文及其摘要,总计50000个样本。
'https://download.mindspore.cn/toolkits/mindnlp/dataset/text_generation/nlpcc2017/train_with_summ.txt'
数据处理为目标格式:
原始数据格式:
article: [CLS] article_context [SEP]
summary: [CLS] summary_context [SEP]
预处理后的数据格式:
[CLS] article_context [SEP] summary_context [SEP]
import json
import numpy as np
# preprocess dataset
def process_dataset(dataset, tokenizer, batch_size=4, max_seq_len=1024, shuffle=False) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









