









写在前面
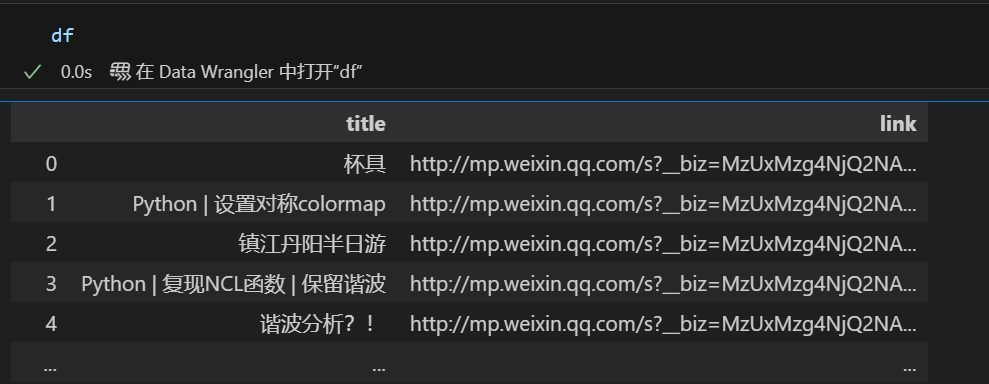
之前一直想偷懒写个脚本,方便后续整理推文,昨天测试了半天,后续因为太频繁结果被封了ip。今天重新修改了代码,终于算是可以了。以下是抓取的结果:
非常简单,只有两部分内容, 标题和link
准备
安装包:
import requests
import time
import pandas as pd
import math
import random
import numpy as np
确定使用设备
这里通过代码来访问网页,需要构建请求头,以模拟真实用户的请求,包含两部分内容:
- Cookie
- User-Agent
分别用于模拟不同的浏览器和操作系统,以避免被服务器识别为爬虫;以及用于模拟已登录的用户会话,以便访问需要登录才能查看的内容。
如何查找这两个参数呢?
获取方法也很简单,打开任意网页-按F12-点击Network-刷新网页-选择任意跳出的内容-点击Headers-查看Cookie和User-Agent即可
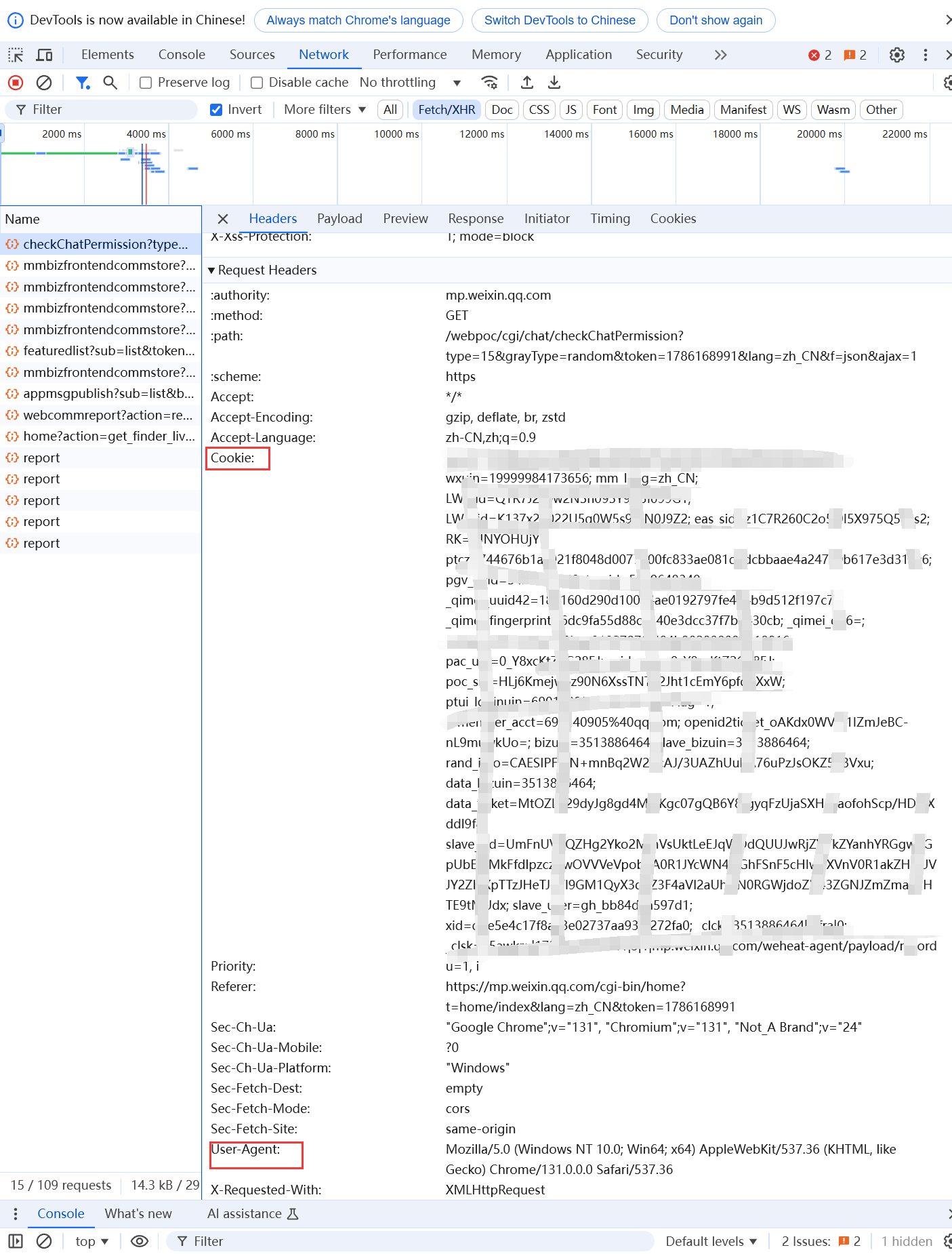
获取微信公众号推文的参数
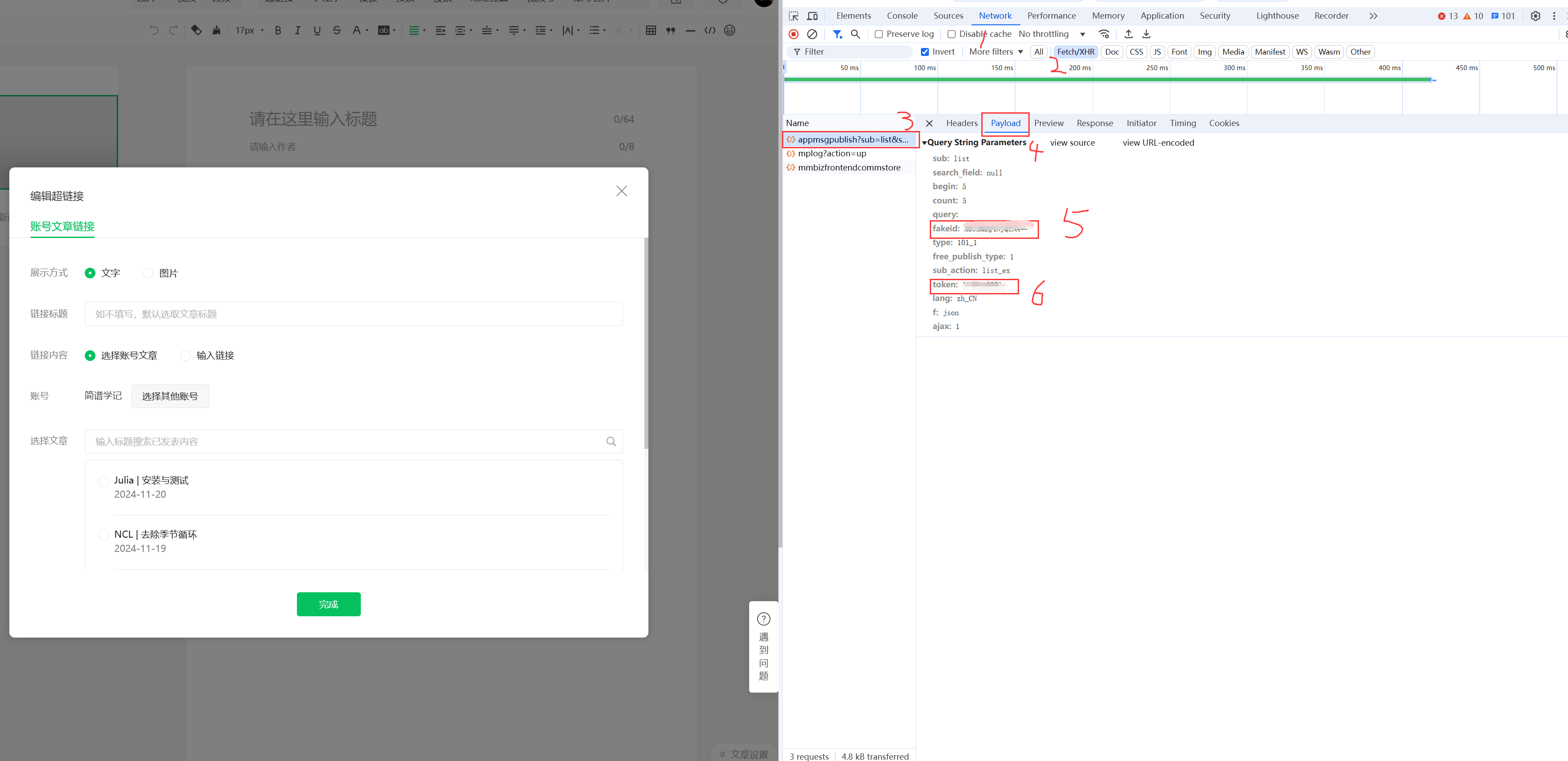
这里需要你有自己的微信公众号,登录进入后-文章-新建图文-超链接
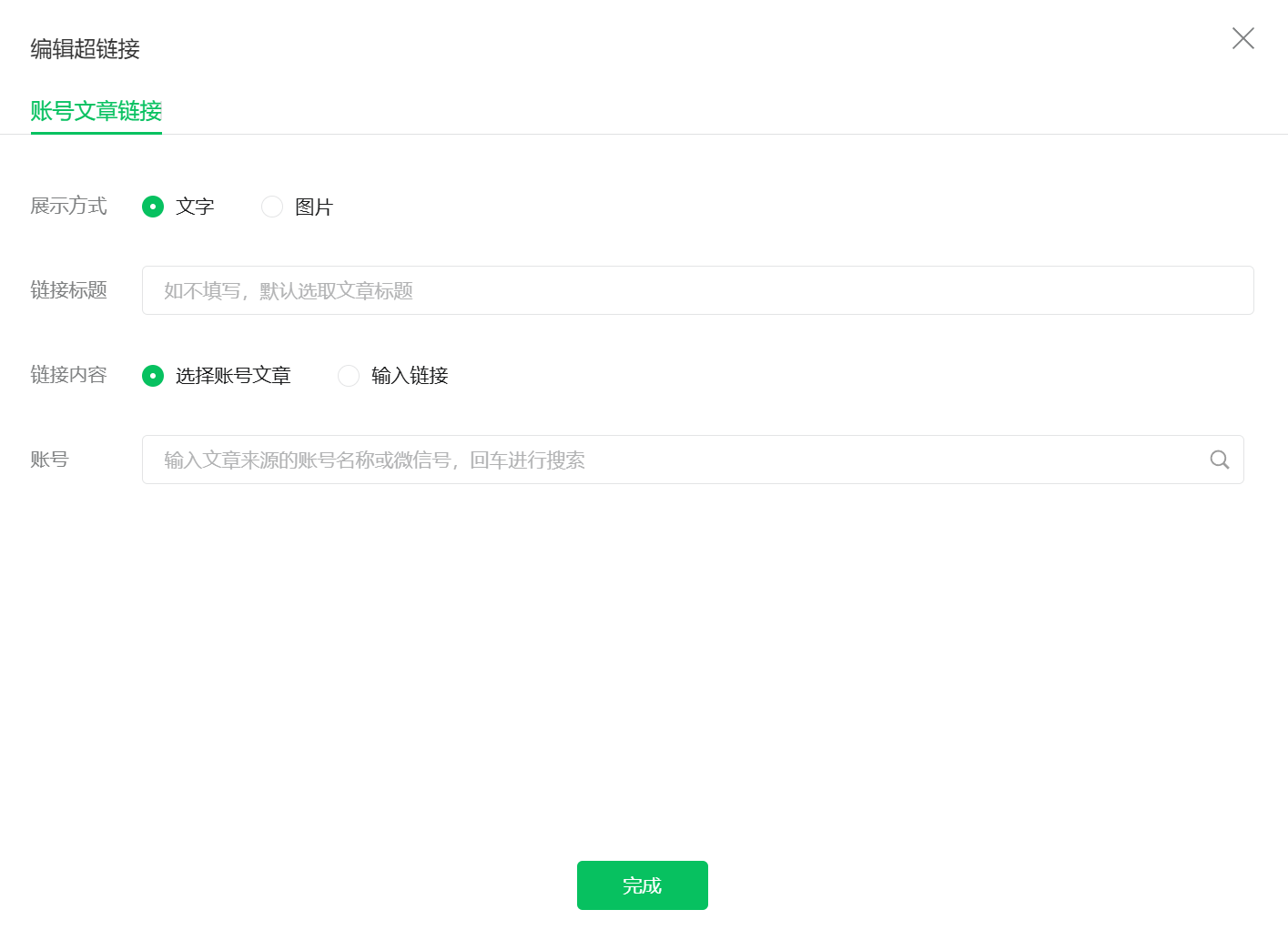
输入你要查询的账户,例如:-简谱学记-回车-按F12-Network,如下所示,在Name下面暂时没有任何信息,
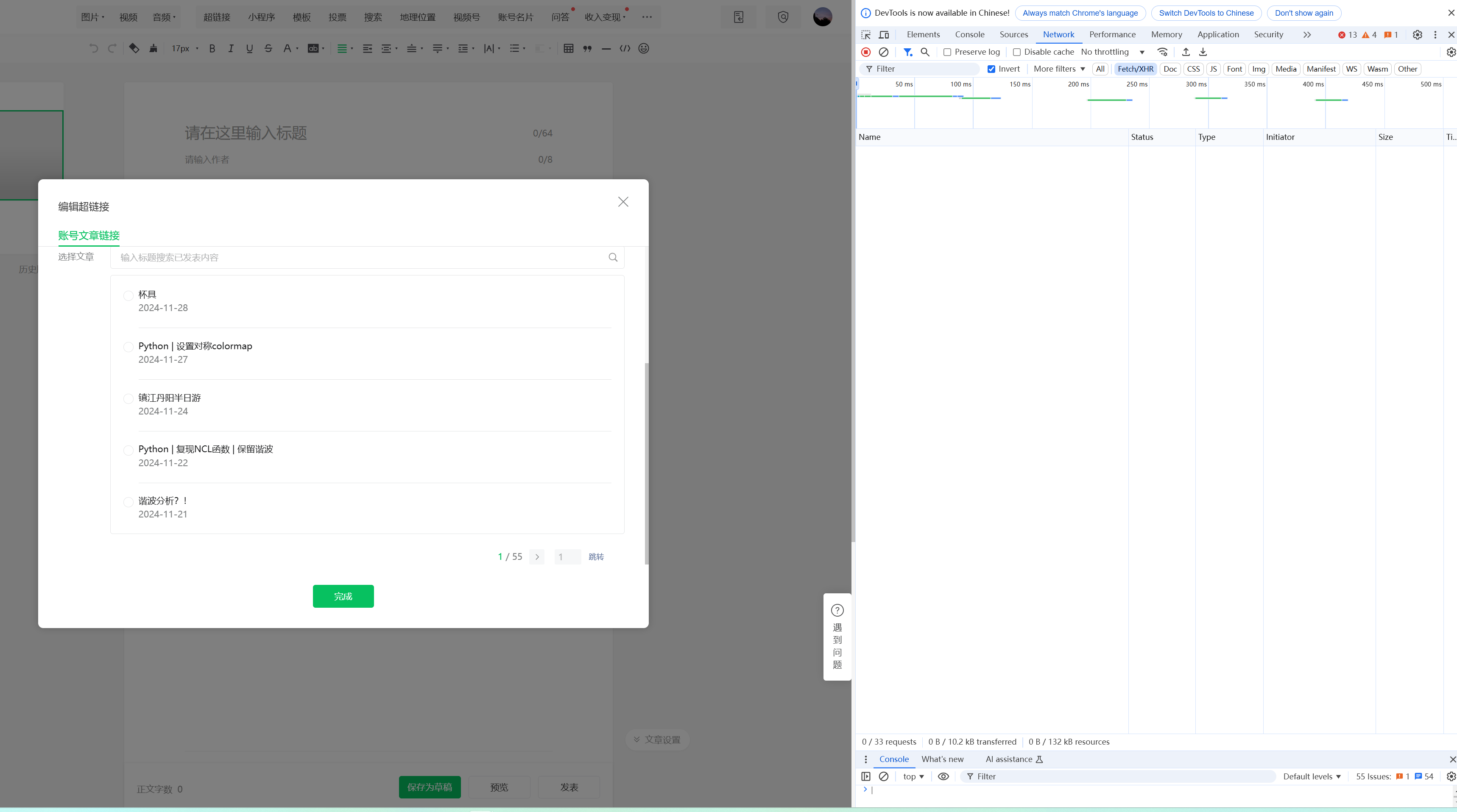
在右侧文章选择中,跳转任一一页,获取你的fakeid和token
- 注意,其中token会发生变化,注意随时更新
python代码
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Mobile Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0",
]
cookie ='替换为你自己的cookie'
headers = {
"Cookie": cookie,
"User-Agent": "替换为你自己的User-Agent",
}
data_template = {
"token": "替换为你自己的token", # 替换为你的token
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": "替换为目标公众号的fakeid", # 替换为目标公众号的fakeid
"type": "9",
}
# 目标url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
content_list = []
seen_titles = set() # 用于存储已抓取的文章标题,避免重复
# 抓取过程
for number in np.arange(0, 200, 5): # 每次请求5条,抓取9页数据
print(f"抓取第 {number} 页...")
# 更新请求参数
data_template["begin"] = number
# 发送 GET 请求并解析返回的 JSON 数据
response = requests.get(url, headers=headers, params=data_template)
content_json = response.json()
if "app_msg_list" in content_json:
for item in content_json["app_msg_list"]:
title = item["title"]
link = item["link"]
# 检查是否已抓取过该文章(避免重复抓取)
if title not in seen_titles:
print(f"抓取到新文章:{title} - {link}")
# 添加到已抓取的标题集合中
seen_titles.add(title)
# 保存文章信息
content_list.append({"title": title, "link": link})
# 暂停,避免请求过快
time.sleep(random.randint(5, 8))
# 每页请求间隙时间
time.sleep(15)
# 将抓取到的数据保存为 pandas DataFrame
df = pd.DataFrame(content_list)
# 输出抓取结果到 CSV 文件
df.to_csv('wechat_articles.csv', index=False, encoding='utf-8-sig')
print("抓取完成,数据已保存为 wechat_articles.csv")
以下是运行代码的日志过程,可以根据自己的推文数量选择合适的运行条数,修改页数的循环

总结
简单调试了一个脚本方便自己的后续推文整理,当然,爬取的内容可能不仅仅是原创推文,以及一些图片的文字。可以再进行相应调整。
最后,声明一下:
- 该教程为个人学习记录,本人公开的代码以及爬取的文本为本人个人公众号,相关代码仅供测试与学习!
参考方法:https://github.com/wnma3mz/wechat_articles_spider?tab=readme-ov-file


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











