







 本文介绍了Scrapy框架的基本结构、工作原理和使用方法,并通过实例展示了如何利用Scrapy爬取豆瓣Top250图书数据以及招聘网站的招聘信息。在爬取过程中,详细讲解了items、spiders、settings的设置,以及如何存储数据到CSV和Excel文件。此外,还涉及到设置USER_AGENT、ROBOTSTXT_OBEY和DOWNLOAD_DELAY等参数。
本文介绍了Scrapy框架的基本结构、工作原理和使用方法,并通过实例展示了如何利用Scrapy爬取豆瓣Top250图书数据以及招聘网站的招聘信息。在爬取过程中,详细讲解了items、spiders、settings的设置,以及如何存储数据到CSV和Excel文件。此外,还涉及到设置USER_AGENT、ROBOTSTXT_OBEY和DOWNLOAD_DELAY等参数。
1、Scrapy的结构
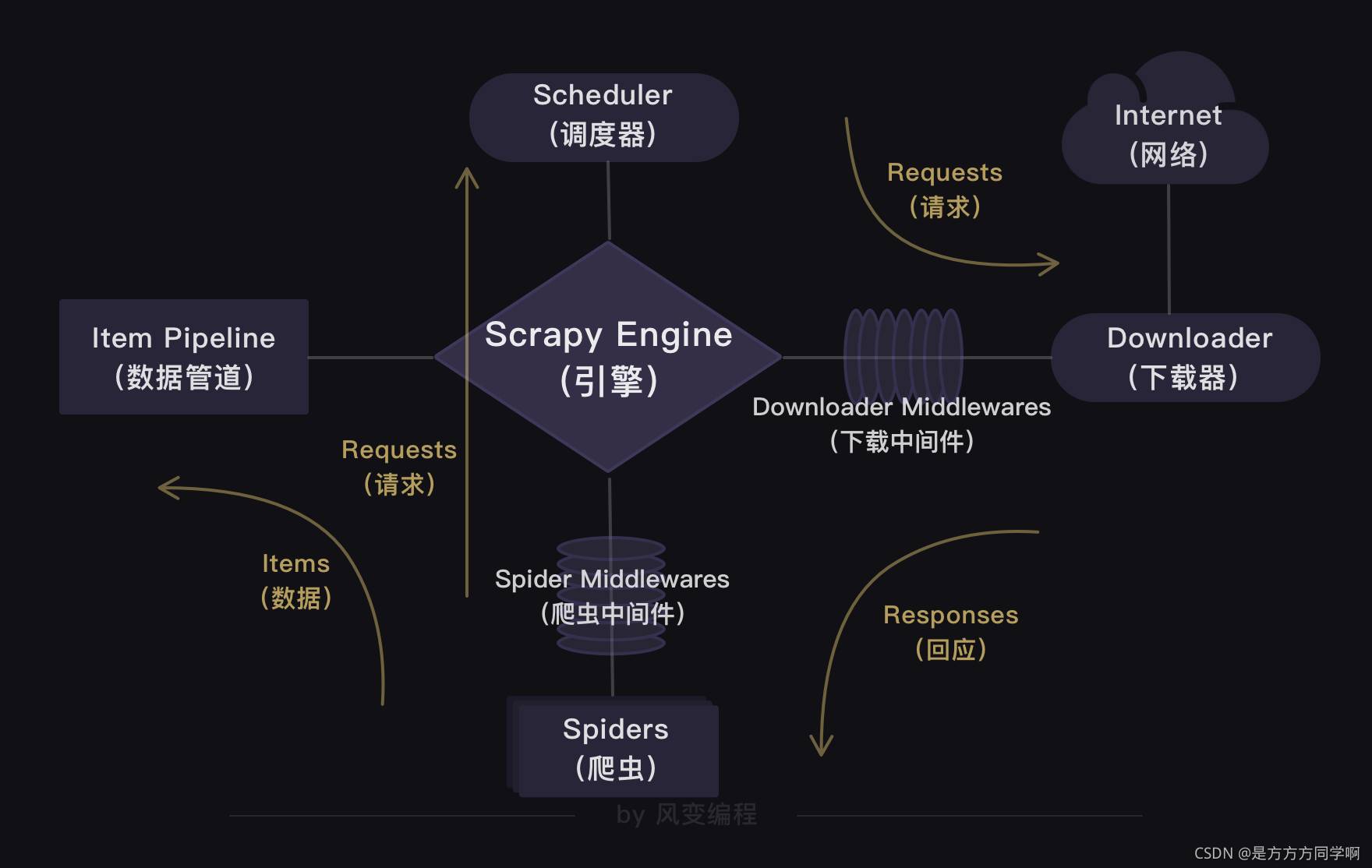
2、Scrapy的工作原理
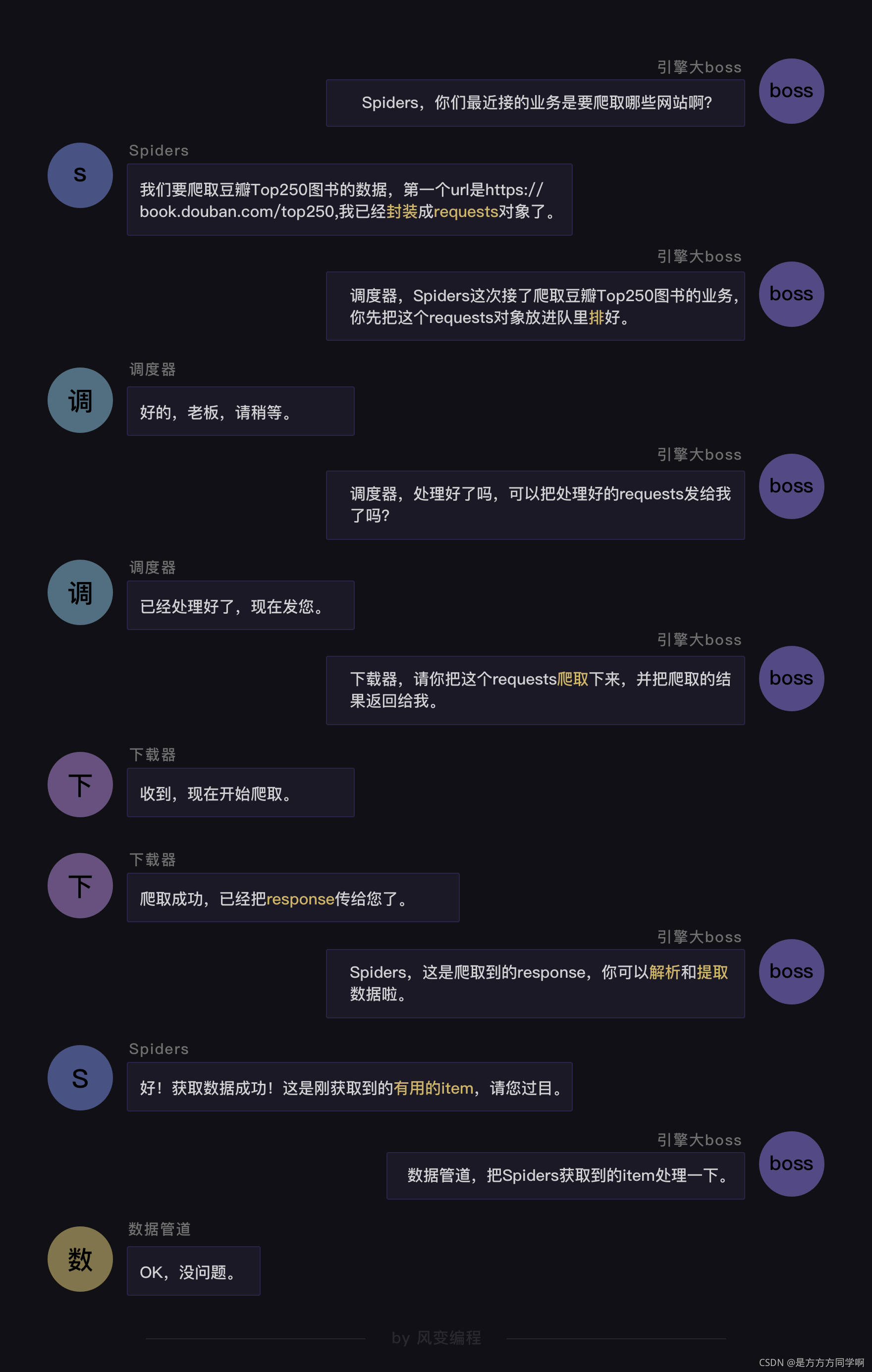
3、Scrapy的用法

4、用Scrapy框架爬取豆瓣Top250图书的数据
创建一个Scrapy框架(cmd -> d: -> cd xxx)
scrapy startproject douban
items.py
import scrapy
class DoubanItem(scrapy.Item):
title = scrapy.Field()
publish = scrapy.Field()
score = scrapy.Field()
spiders_top250.py
import scrapy
import bs4
from ..items import DoubanItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['book.douban.com']
start_urls = []
for x in range(3):
url = 'https://book.douban.com/top250?start=' + str(x*25)
start_urls.append(url)
def parse(self, response):
bs = bs4.BeautifulSoup(response.text, 'html.parser')
datas = bs.find_all('tr', class_='item')
for data in datas:
item = DoubanItem()
item['title'] = data.find_all('a')[1]['title']
item['publish'] = data.find('p', class_='pl').text
item['score'] = data.find('span', class_='rating_nums').text
print(item['title'])
yield item
settings.py(修改处)
USER_AGENT = 'Mozilla/5.0 ......'
ROBOTSTXT_OBEY = False
运行Scrapy框架
- 第一种方法:cmd -> d: -> xxx -> douban
scrapy crawl douban(douban为爬虫名字)
- 第二种方法:新建main.py(与 scrapy.cfg 同级)
from scrapy import cmdline
cmdline.execute(['scrapy', 'crawl', 'douban'])
5、用scrapy爬取招聘网站的招聘信息
items.py
import scrapy
class JobuiItem(scrapy.Item):
company = scrapy.Field()
position = scrapy.Field()
address = scrapy.Field()
detail = scrapy.Field()
spiders_jobui_jobs.py
import scrapy
import bs4
from ..items import JobuiItem
class JobuiSpider(scrapy.Spider):
name = 'jobui'
allowed_domains = ['www.jobui.com']
start_urls = ['https://www.jobui.com/rank/company/']
def parse(self, response):
bs = bs4.BeautifulSoup(response.text, 'html.parser')
ul_list = bs.find_all('ul', class_='textList flsty cfix')
for ul in ul_list:
a_list = ul.find_all('a')
for a in a_list:
company_id = a['href']
url = 'https://www.jobui.com{id}jobs/'
real_url = url.format(id=company_id)
yield scrapy.Request(real_url, callback=self.parse_job)
def parse_job(self, response):
bs = bs4.BeautifulSoup(response.text, 'html.parser')
company = bs.find(id='companyH1').text
datas = bs.find_all('div', class_='c-job-list')
for data in datas:
item = JobuiItem()
item['company'] = company
item['position'] = data.find('a').find('h3').text
item['address'] = data.find_all('span')[0]['title']
item['detail'] = data.find_all('span')[1].text + '|' + data.find_all('span')[2].text + '|' + data.find_all('span')[3].text
yield item
settings.py
USER_AGENT = 'Mozilla/5.0 ......'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.5
存储文件
- 存储成 csv
在 settings.py 中添加以下代码:(无效?)
FEED_URI='./storage/data/%(name)s.csv'
FEED_FORMAT='csv'
FEED_EXPORT_ENCODING='ansi'
- 存储成Excel文件
在 settings.py 中做如下修改:
ITEM_PIPELINES = {
'jobui.pipelines.JobuiPipeline': 300,
}
修改 pipelines.py :
import openpyxl
class JobuiPipeline:
def __init__(self):
self.wb = openpyxl.Workbook()
self.ws = self.wb.active
self.ws.append(['公司', '职位', '地址', '招聘信息'])
def process_item(self, item, spider):
line = [item['company'], item['position'], item['address'], item['detail']]
self.ws.append(line)
return item
def close_spider(self, spider):
self.wb.save('./jobui.xlsx')
self.wb.close()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









