






 本文深入探讨Python中的函数参数类型、不可变与可变数据类型的自加区别、全局及局部变量的作用域,并详细解析abs、max等内置函数的用法,以及map、filter、zip的功能和应用场景。
本文深入探讨Python中的函数参数类型、不可变与可变数据类型的自加区别、全局及局部变量的作用域,并详细解析abs、max等内置函数的用法,以及map、filter、zip的功能和应用场景。
函数进阶
函数参数类型
不可变类型参数:整数、字符串、元组
可变型参数:列表、字典
1.传递不可变参数,不会影响参数本身
2.传递可变型参数,会影响参数本身
不可变数据类型和可变数据类型自加的区别
1. 判断gl_num和gl_list的值
# 不可变数据类型和可变数据类型自加的区别
# 1. 判断gl_num和gl_list的值
def demo(num, num_list):
num += num
# 列表变量使用 + 不会做相加再赋值的操作 !
# num_list = num_list + num_list
# 本质上是在调用列表的 extend 方法
num_list += num_list
# num_list.extend(num_list)
print(num)#18
print(num_list)#[1, 2, 3, 1, 2, 3]
print("函数完成")
gl_num = 9
gl_list = [1, 2, 3]
demo(gl_num, gl_list)
print(gl_num)# 9 因为这是数字类型,传递不可变参数,不会影响参数本身
print(gl_list)#[1, 2, 3, 1, 2, 3] 这是可变型参数
def hanshu(a=[]):
a.append(10)
print(a)
hanshu()#[10]
hanshu()#[10, 10]
def hanshu(a=[]):
a.append(10)
print(a)
hanshu()#[10]
b=[9]
hanshu(b)#[9,10]
hanshu()#[10,10]
命名空间
三种:局部命名空间、全局命名空间、内置命名空间
局部空间:locals()函数访问
全局空间:globals()函数访问
内置名称空间:放着内置的函数和异常。
a=3
b=4
def hanshu(x):
c=5 #x=6
d=6
print("aaaa:",locals())
print("globals:",globals()["__file__"])
hanshu(6)
运行结果:
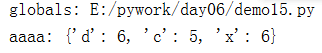
作用域
#作用域
a=3
b=30
c=300
def hsw():
a=4
b=40
def hsn():
a=5
print(a)#L LOCAL(局部作用域:函数内部) 优先使用本地 #5
print(b)#E Enclosing(嵌套作用域:嵌套函数的外层函数内部) 本地没有找嵌套作用域#40
print(c)#G GLOBAL 全局作用域:模块全局 #300
print(__name__,min,max,id)#B Built-in 找内置作用域
hsn()
hsw()
"""
运行结果:
5
40
300
__main__ <built-in function min> <built-in function max> <built-in function id>
"""
全局变量和局部变量
局部变量:在函数中定义,只在函数内部生效。
全局变量:函数外部定义的变量,作用域从定义开始到程序结束。
全局变量是不可改变数据类型,函数无法修改全局变量的值
全局变量是可变数据类型,函数可以修改全局变量的值
global 和nonlocal关键字
1.global可以将局部变量变成一个全局变量
格式:global 变量名称
def hanshu():
global a
a += 10
print("函数内部:", a)
a = 20
hanshu() # 30
print("函数外部", a) # 30
2.nonlocal关键字可以修改外层(非全局变量)
a = 1000
def hsw():
a = 9
def hsn(): # 函数嵌套 enclosing
nonlocal a
a = 98
print("我是内部", a) # 98
hsn()
print("我是外部", a) # 98
hsw()
print(a) # 1000
内置函数
1.abs()函数
作用:求数字的绝对值
2.max()函数(可迭代内容,函数)
max(iterable,key,default)求迭代器的最大值
其中iterable为迭代器,max会for i in ···遍历一遍这个迭代器,然后将迭代器的每一个返回值当做参数传给key=func中的func(一般用lambda表达式定义),然后将func的执行结果传给key,然后以key为标准进行大小的判断。
a = [1, 6, -8, 5]
b = max(a, key=abs) # key后面写的abs是没有()的
print(b) # -8
def hanshu(x):
print("哈哈")
return abs(x)
a=[-1,-3,-2,-5,-4]
b=max(a,key=hanshu)#先将a迭代得到的值,返回参数传递给key=hanshu,hanshu的执行结果传给key,然后以key为标准进行大小的判断
print(b)
"""
运行结果:
哈哈
哈哈
哈哈
哈哈
哈哈
-5
"""
#1.根据name值进行比较
a=[{"name":"a","age":20},{"name":"b","age":25},{"name":"c","age":15}]
def getName(x):
return x["name"]
b=max(a,key=getName)
print(b)
#2.根据age值进行比较
a=[{"name":"a","age":20},{"name":"b","age":25},{"name":"c","age":15}]
def getAge(x):
return x["age"]
b=max(a,key=getAge)
print(b)
#对a的列表进行排序,用绝对值升序
a=[-1,-3,-2,-5,-4]
a.sort(key=abs) # 先对a进行排序,后面再打印
print(a)#[-1, -2, -3, -4, -5]
3.map()函数
有两个参数(函数,可迭代内容)
函数会依次作用在可迭代内容的每一个元素上进行计算,然后返回一个新的可迭代内容。
#计算列表里每一个数的平方
def pingfang(x):
return x * x
a = [1, 2, 3]
ret = map(pingfang, a)
for i in ret:
print(i)
def hanshu(x):
return x * x
a = [1, 2, 3]
b = map(hanshu, a) # 映射,加工过的值
print(b) # <map object at 0x00000000025A7550>
c = list(b)
print(c) # [1, 4, 9]
4.filter()函数
两个参数(函数,序列)
用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
两个参数(函数,序列),序列的每个元素作为参数传递给函数进判,然后返回True或False,最后将返回True的元素放到新列表中。
def gl(a):
if a % 3 == 0 or a % 7 == 0:
return True
else:
return False
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
b = filter(gl, a) # 过滤
print(b)
print(list(b))
5.zip()函数
zip函数接受任意多个可迭代对象作为参数,将对象中对应的元素打包成一个tuple。
然后返回一个可迭代的zip对象,这个可迭代对象可以使用循环的方式列出其元素。
若多个可迭代对象的长度不一致,返回的长度与短的一致
a=[1,2,3,4]
b=['a','b','c']
c=zip(a,b)
for x in c:
print(x)
"""
(1, 'a')
(2, 'b')
(3, 'c')
"""
a=[1,2,3]
b=['a','b','c']
def hs(x):
return {x[0]:x[1]}
x=map(hs,zip(a,b))
d=list(x)
print(d)
"""
运行结果:
[{1: 'a'}, {2: 'b'}, {3: 'c'}]
"""
加深理解
a=(('a',),('b'))#当在其中一个里面加上一个,号,就变成了元组
print(type(a[0]))#<class 'tuple'>
b=(('c'),('d'))#这里是元组里面有两个元素,不是有两个元组
x=zip(a,b)
print(x)#<zip object at 0x00000000025C6608>
for i in x:
print(i)
"""
这里的结果:
(('a',), 'c')
('b', 'd')
"""
print(list(x))#[] 这里是空,因为迭代器x用for已经遍历空了,所以再list的时候就空了
将这两个元组((‘a’),(‘b’)),((‘c’),(‘d’)),生成[{‘a’: ‘c’}, {‘b’: ‘d’}]的格式。
a=(('a'),('b'))
b=(('c'),('d'))
def hanshu(a):
return {a[0]:a[1]}
x=map(hanshu,zip(a,b))
print(list(x))
"""
运行结果:
[{'a': 'c'}, {'b': 'd'}]
"""
匿名函数 lambda
语法:
变量名=lambda 参数 :表达式(block)
func = lambda: 3 < 2
ret = func()
print(ret) # false
hs = lambda x, y, z: x + y + z # 小型函数关键字
b = hs(2, 3, 4)
print(b) # 9
x = lambda a, b: a if a > b else b
y = x(2, 3)
print(y) # 3
a = [{"name": "战三", 'age': 19}, {"name": "lisi", 'age': 29}, {"name": "wanh", 'age': 9}]
# def getAge(x):
# return x["age"]
x = lambda z: z['age']
b = max(a, key=x)
print(b)#{'name': 'lisi', 'age': 29}
a = [{"name": "战三", 'age': 19}, {"name": "lisi", 'age': 29}, {"name": "wanh", 'age': 9}]
b = max(a, key=lambda z: z['age'])
print(b)
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
b = filter(lambda x: True if x % 2 == 0 else False, a)
print(list(b)) # [2, 4, 6, 8]
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list(filter(lambda x: not x % 2, a))) # [2, 4, 6, 8]
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list(filter(lambda x: True if x % 3 == 0 or x % 7 == 0 else False, a))) # [3, 6, 7, 9]
a = [1, 2, 3]
b = ['a', 'b', 'c']
print(list(map(lambda x: {x[0]: x[1]}, zip(a, b)))) # [{1: 'a'}, {2: 'b'}, {3: 'c'}]
嵌套作用域
def hs(): # 函数执行过程:
x = 3
def nb(n):
return x ** n
return nb # 这里有返回值,所以b就等于了nb
b = hs() # 会遇到返回值
print(b)
print(b(2)) # 这其实就是nb(2) 9
print(b(3)) # 27
def hs():
x = 3
return lambda n: x ** n
b = hs()
print(b(2)) # 9
print(b(3)) # 27
def func():
x = 2
def nb(n, x=x): # 可以不一定是多个参数,不写在见到b(3)的时候就会报错了
return x ** n
return nb
b = func()
print(b(3)) # 8
print(b(2, 3)) # 9
def func():
x = 2
return lambda n, x=x: x ** n
b = func()
print(b(3, 2)) # 8
#第一
def hehe():
a=[]
for i in range(3):
a.append(lambda y:y*i)
# b=lambda y: y * i
# a.append(b)
return a
z=hehe()
print(z[0](2))#4
print(z[1](2))#4
print(z[2](2))#4
#第二
def hehe():
a=[]
for i in range(3):
b=lambda y,i=i: y * i
a.append(b)
return a
z=hehe()
print(z[0](2))#0
print(z[1](2))#2
print(z[2](2))#4
i = 6
def x1(x=i):
print(x)
i = 7
def x2(x=i):
print(x)
x1() # 6
x2() # 7

















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









