







 联邦机器学习是一种在保障用户隐私、数据安全和遵循法规的前提下,让多个机构协作进行机器学习的方法。它允许数据保留在本地,通过加密的参数交换创建虚拟共享模型,适用于数据特征或用户重叠不同的场景。联邦学习主要分为横向联邦(特征对齐)、纵向联邦(样本对齐)和联邦迁移学习,分别应对不同类型的数据分布,旨在提高模型质量和数据利用效率,同时确保数据合规性。
联邦机器学习是一种在保障用户隐私、数据安全和遵循法规的前提下,让多个机构协作进行机器学习的方法。它允许数据保留在本地,通过加密的参数交换创建虚拟共享模型,适用于数据特征或用户重叠不同的场景。联邦学习主要分为横向联邦(特征对齐)、纵向联邦(样本对齐)和联邦迁移学习,分别应对不同类型的数据分布,旨在提高模型质量和数据利用效率,同时确保数据合规性。
联邦机器学习(Federated machine learning/Federated Learning),又名联邦学习,联合学习,联盟学习。联邦机器学习是一个机器学习框架,能有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。
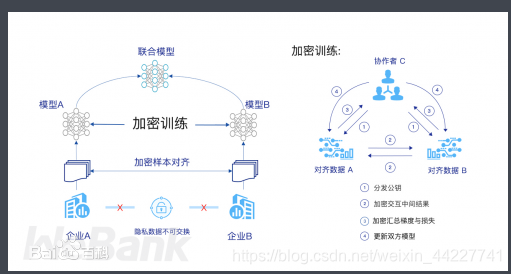
举例来说,假设有两个不同的企业 A 和 B,它们拥有不同数据。比如,企业 A 有用户特征数据;企业 B 有产品特征数据和标注数据。这两个企业按照上述 GDPR 准则是不能粗暴地把双方数据加以合并的,因为数据的原始提供者,即他们各自的用户可能不同意这样做。假设双方各自建立一个任务模型,每个任务可以是分类或预测,而这些任务也已经在获得数据时有各自用户的认可,那问题是如何在 A 和 B 各端建立高质量的模型。由于数据不完整(例如企业 A 缺少标签数据,企业 B 缺少用户特征数据),或者数据不充分 (数据量不足以建立好的模型),那么,在各端的模型有可能无法建立或效果并不理想。联邦学习是要解决这个问题:它希望做到各个企业的自有数据不出本地,而后联邦系统可以通过加密机制下的参数交换方式,即在不违反数据隐私法规情况下,建立一个虚拟的共有模型。这个虚拟模型就好像大家把数据聚合在一起建立的最优模型一样。但是在建立虚拟模型的时候,数据本身不移动,也不泄露隐私和影响数据合规。这样,建好的模型在各自的区域仅为本地的目标服务。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了“共同富裕”的策略。 这就是为什么这个体系叫做“联邦学习”。
根据孤岛数据的分布特点将联邦学习分为三类。
数据分布基本可以分为以下三种情况:
两个数据集的数据特征(X1,X2,…)重叠部分较大,而用户(U1, U2…)重叠部分较小;
两个数据集的用户(U1, U2…)重叠部分较大,而数据特征(X1,X2,…)重叠部分较小;
两个数据集的用户(U1, U2…)与数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









