







Mysql索引
索引的相关概念
-
Mysql索引是什么
数据库系统还维护这满足某种特定查找算法的数据结构 这些数据结构以特定的方式指向数据 这种
数据结构就是索引
看一个例子:
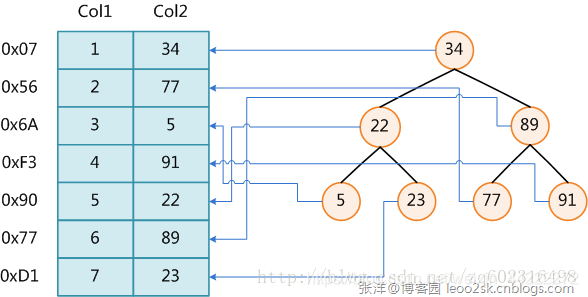
上图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找获取到相应数据
-
索引的优点
1)
提高检索效率,降低I/O成本
2)通过索引对数据进行排序,降低数据排序成本,降低CPU消耗 -
索引的缺点
1)虽然提高了查询效率,但降低了
更新效率(每次INSERT、UPDATE、DEIETE,Mysql不仅要保存数据,还要更新索引文件)
2)索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引也要占用空间索引相关数据结构对比
-
BTree 多路平衡查找树
BTree示意图
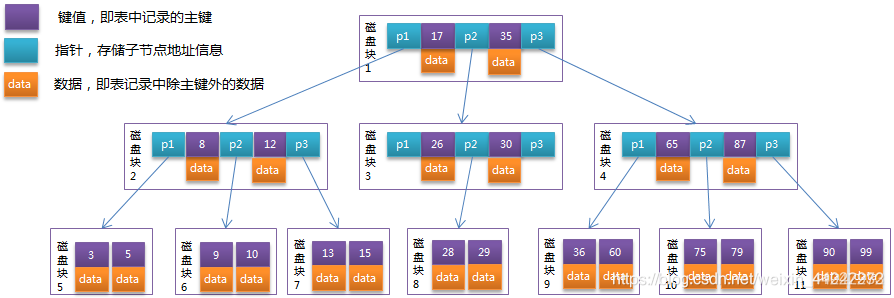
BTree图解析1)每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址
2)两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35查找过程 查找数据项29
1)第一次IO,先把磁盘块1由磁盘加载到内存,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计
2)第二次IO,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,29在26和30之间,锁定磁盘块3的P2指针,
3)第三次IO,通过指针加载磁盘块8到内存,同时内存中做二分查找找到29,结束查询BTree缺点
1)每个节点中有key、指针和data,而每一个页的存储空间是有限的,如果data数据较大时就会导致每个节点(即一个页)能存储的key的数量很小
2)当存储的数据量很大时,同样会导致B-Tree的深度较大,增加查询时的磁盘I/O次数,进而影响查询效率
-
B+Tree B+Tree是在BTree基础上的一种优化,innoDB存储引擎就是用B+Tree实现其索引结构的
B+Tree和BTree的区别
1)非叶子节点只存储键值(key)和指针
2)所有叶子节点间都有链指针
3)数据记录都放在叶子节点中B+Tree示意图
-
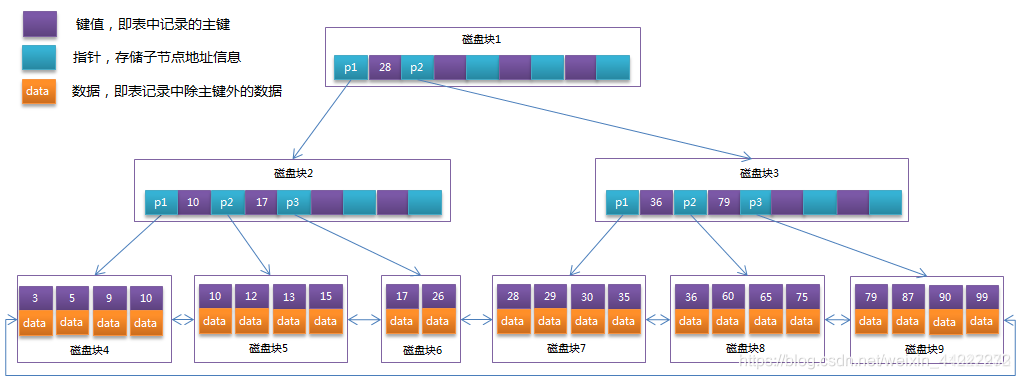
为什么说B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?
B+Tree的磁盘读写代价更低
B+Tree的内部结点并没有指向关键字具体数据的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了
Mysql的索引实现
-
MyISAM索引实现
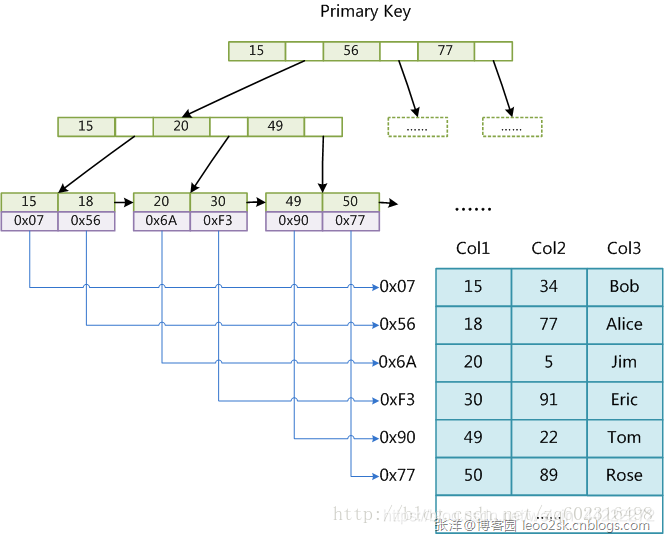
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图:
-
InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
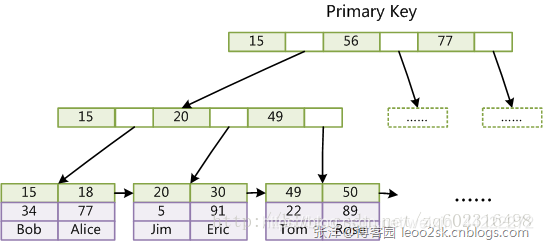
与MyISAM的一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录
-
小结 MyISAM和InnoDB引擎的区别
MyISAM存储引擎B+tree的叶子节点中data不是数据本身,而是数据存放的地址,主索引和辅助索引没什么区别,只是主索引是唯一的,这里的主索引和辅助索引都是非聚簇索引。myisam引擎的索引文件和数据文件是独立分开的
InnoDB存储引擎B+tree中叶子节点中data存储的是数据本身,key为主键,这是聚簇索引。在innodb中,即存储主键索引值,又存储行数据

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









