







 本文深入探讨了顺序表和链表两种基本数据结构的特点和区别。顺序表使用连续内存存储,适合快速访问,但插入和删除操作较慢;链表使用指针连接不连续的内存,便于动态增删,但查找速度慢。文章详细分析了两者在存储方式、长度调整、数据访问和增删操作上的不同,以及各自适用的场景。
本文深入探讨了顺序表和链表两种基本数据结构的特点和区别。顺序表使用连续内存存储,适合快速访问,但插入和删除操作较慢;链表使用指针连接不连续的内存,便于动态增删,但查找速度慢。文章详细分析了两者在存储方式、长度调整、数据访问和增删操作上的不同,以及各自适用的场景。
一.顺序表
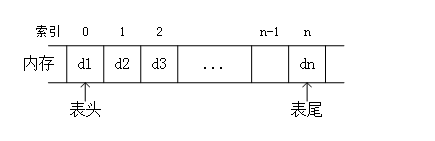
顺序表一般表现为数组,使用一组地址连续的存储单元依次存储数据元素,如图 1 所示。
它具有如下特点:
1.长度固定,必须在分配内存之前确定数组的长度。
2.存储空间连续,即允许元素的随机访问。
3.存储密度大,内存中存储的全部是数据元素。
4.要访问特定元素,可以使用索引访问,时间复杂度为 O(1)。
5.要想在顺序表中插入或删除一个元素,都涉及到之后所有元素的移动,因此时间复杂度为 O(n)。
顺序表最主要的问题就是要求长度是固定的,可以使用倍增-复制的办法来支持动态扩容,将顺序表变成“可变长度”的。具体做法是初始情况使用一个初始容量(可以指定)的数组,当元素个数超过数组的长度时,就重新申请一个长度为原先二倍的数组,并将旧的数据复制过去,这样就可以有新的空间来存放元素了。这样,列表看起来就是可变长度的。
//在顺序表中插入下标为Index的位置以val值
typedef struct Seqlist{
int *array;
int capacity;
int size;
}Seqlist;
void Seqlist(Seqlist* s,int index,int val){
//先判断容量是否够用,不够则扩容
if(s->size>=s->capacity)
{
//扩容
int* nexcapacity=(int*)malloc(sizeof(int)*s->capacity*2);//找新家
for(int i=0;i<s->size;i++){
newcapacity[i]=s->array[i];}//一家老小搬家
free(s->array);//退房
s->array=newcapacity;//发朋友圈
for(int i=s->size;i>index;i--){//给新人腾地方
s->array[i]=s->array[i+1];}
s->array[index]=val;//新人获得身份
s->size++;
}
这个办法不可避免的会浪费一些内存,因为数组的容量总是倍增的。而且每次扩容的时候,都需要将旧的数据全部复制一份,肯定会影响效率。不过实际上,这样做还是直接使用链表的效率要高,具体原因会在下一节进行分析。
二.链表
链表,类似它的名字,表中的每个节点都保存有指向下一个节点的指针,所有节点串成一条链。根据指针的不同,还有单链表、双链表和循环链表的区分,如图 2 所示。
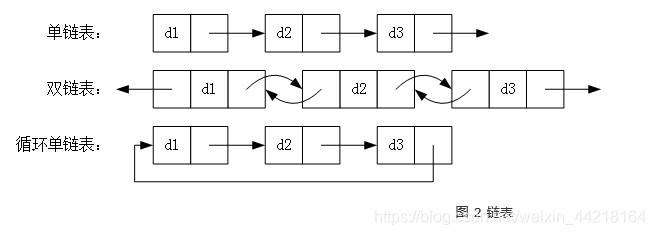
由于链表是使用指针将节点连起来,因此无需使用连续的空间,它具有以下特点:
1.长度不固定,可以任意增删。
2.存储空间不连续,数据元素之间使用指针相连,每个数据元素只能访问周围的一个元素(根据单链表还是双链表有所不同)。
3.存储密度小,因为每个数据元素,都需要额外存储一个指向下一元素的指针(双链表则需要两个指针)。
4.要访问特定元素,只能从链表头开始,遍历到该元素,时间复杂度为O(N) 。
5.在特定的数据元素之后插入或删除元素,不涉及到其他元素的移动,因此时间复杂度为O(1) 。双链表还允许在特定的数据元素之前插入或删除元素。
三.比较
| 顺序表 | 链表 |
|---|---|
| 从栈中开辟一片连续的存储单元对数据进行存储,存储结构和数据逻辑相同 | 从堆中动态开辟出的不连续存储单元,通过指针在计算机存储单元上对数据逻辑进行链接 |
| 空间大小固定,管理方便,自由度小 | 空间大小不固定,申请管理麻烦,自由度大 |
| 通过下标获取元素,存储密度为1 | 通过结构体next数据项中存储的指针寻找并获取元素 |
| 查找元素快,平均时间复杂度为O(1) | 查找元素慢,查找平均时间复杂度为O(n) |
| 增删元素慢,增删的平均时间复杂度为O(n) | 增删元素快,增删的平均时间复杂度为O(1) |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









