






系列文章目录
- 【整流模型(一) / 扩散模型(十一)】SD1.5 / SDXL / SD3 / Flux 整体区别梳理汇总,扩散与整流(Rectified Flow)的区别
- 【整流模型(二)】RF-inversion/ Flux 中 free lunch / training-free 的 Editing 和 Style Transfer (Inversion)
- 本文【整流模型(三)】Flux 中 MM-DiT 和 Single-DiT 中的具体区别,下图为 OminiControl 时的 Flux,在 MM-attention 中增加了一个新的 Condition 分支。
| 特性 | FluxSingleTransformerBlock | FluxTransformerBlock |
|---|---|---|
| 架构基础 | Single-DiT | MM-DiT |
| 处理类型 | 单一输入流 | 双输入流 (hidden_states 和 encoder_hidden_states) |
| 归一化层 | AdaLayerNormZeroSingle | AdaLayerNormZero (两个实例) |
| 注意力机制 | 自注意力 | 自注意力 + 交叉注意力 |
| MLP结构 | 简单MLP (proj_mlp + act_mlp) | FeedForward (两个实例) |
| 输出连接 | 注意力输出与MLP输出拼接 | 分别处理注意力输出和MLP输出 |
| 门控机制 | 单一门控 (gate) | 多重门控 (gate_msa, gate_mlp, c_gate_msa, c_gate_mlp) |
| 归一化后处理 | 无 | 有缩放和偏移 (scale_mlp, shift_mlp) |
| 输入参数 | hidden_states, temb, image_rotary_emb | hidden_states, encoder_hidden_states, temb, image_rotary_emb |
| 输出 | 单一张量 | 两个张量 (encoder_hidden_states, hidden_states) |
| 典型用途 | 处理单一特征流 | 处理文本条件和图像特征的交互 |
MM-DiT
Single-DiT
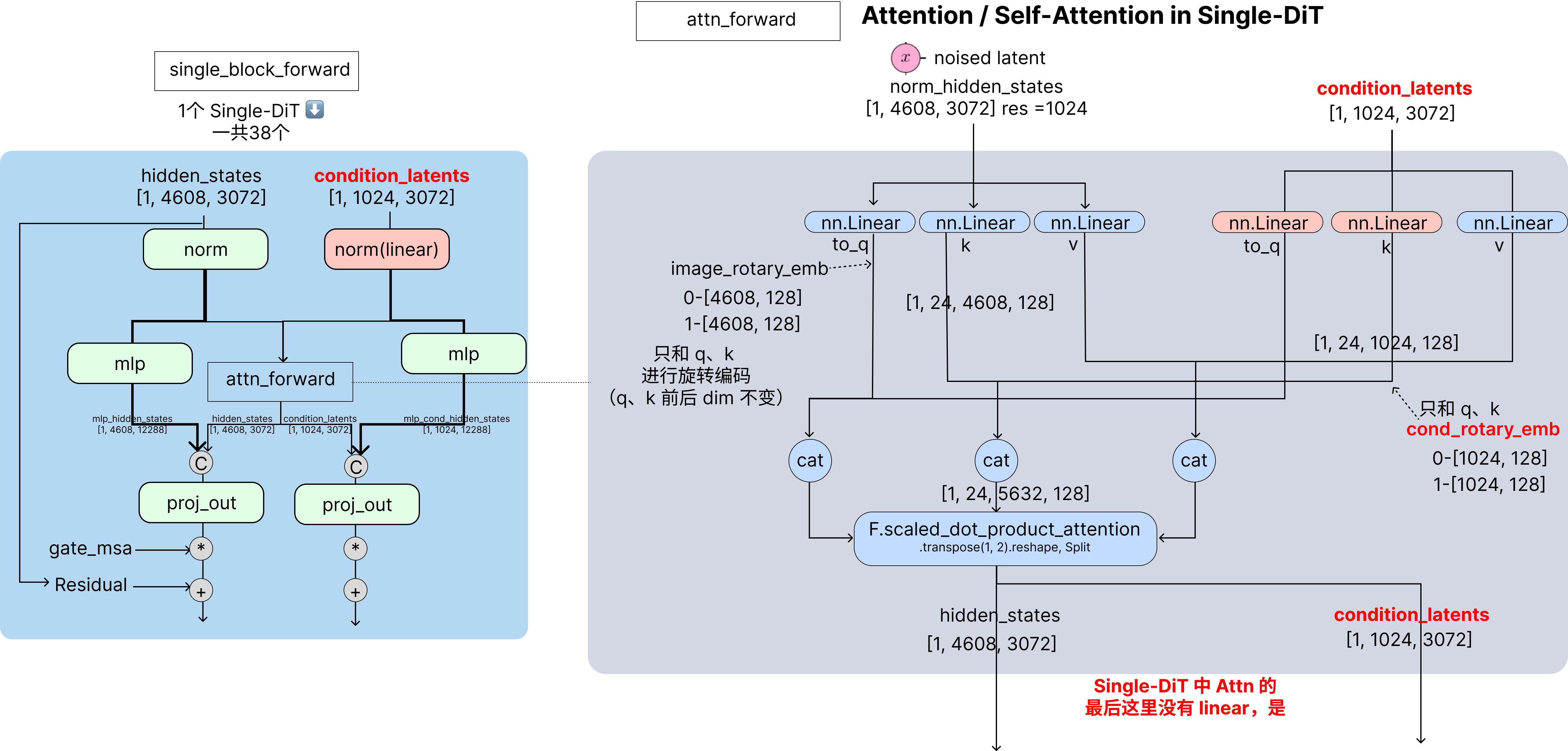
左图的加粗线可以看出 MLP 和 Attention 是并行的关系
主要区别总结
- 处理流程:
- MM-DiT 同时处理两个输入流并让它们相互交互
- Single-DiT 处理单一输入流 (MM-DiT 的双流合并后的单流)
- 并行注意力机制:
- Single-DiT 块里用到了并行注意力层,而 MM-DiT 是串行的。
- 主要指 MLP 和 Attention 的关系(并行 or 串行)
并行注意力层是在文章 Scaling Vision Transformers to 22 Billion Parameters 中提出的。如下图所示,这项技术很好理解,只不过是把注意力和线性层之间的串联结构变成并联结构。
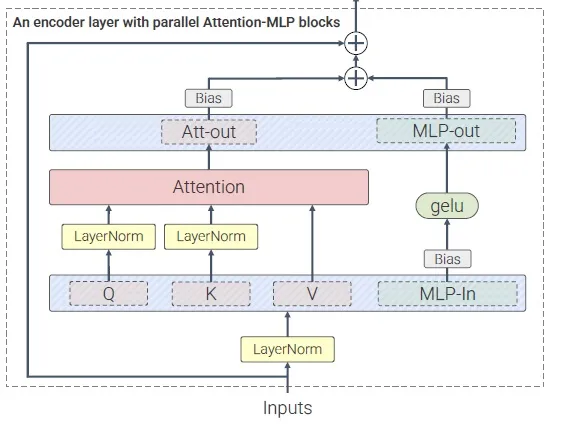
- 好处是,由于数据在过**
注意力层前后本身就要各过一次线性层,在并联后,这些线性层和 MLP 可以融合**。 - 这样的话,由于计算的并行度更高,模型的运行效率会高上一些。
- 顺带一提,在 Q, K 后做归一化以提升训练稳定性也是在这篇文章里提出的。SD3 和 FLUX.1 同样用了这一设计,但用的是
RMSNorm而不是 LayerNorm。


















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









