










系列文章目录
- 【Domain Generalization(1)】增量学习/在线学习/持续学习/迁移学习/多任务学习/元学习/领域适应/领域泛化概念理解
- 第一篇大概了解了 DG 的概念,那么接下来将介绍 DG 近年在文生图中的相关应用/代表性工作。
- 本文介绍的是 PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization (ICCV 2023)
一句话说清楚
- 任务是图像到文本的类别识别
- 关键是利用 CLIP 的图文联合空间
- 主要做法是1)增加了 style 和 content loss,构造了 style-content 数据,2)训练: 在 CLIP 的 text encoder 前训了类似 Textual Inversion 的风格伪词(style word vectors),以及训了最后分类的 Linear Layer,3)推理:用训好的 Linear Layer 加 CLIP 的 image encoder 进行图像的分类,图像到文本标签的生成。
- 亮点是在没用任何 source domain 数据做训练的情况下,达到了最优结果。(Source-free DG)

研究背景
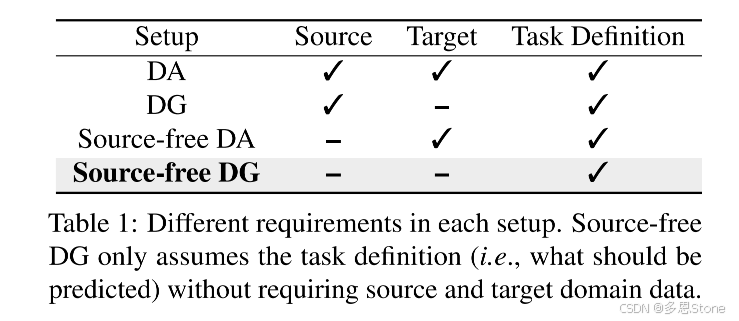
- 深度神经网络的分布偏移问题:深度神经网络通常在训练和测试数据独立同分布的假设下进行训练,但在实际应用中,训练和测试数据之间可能存在显著的分布偏移,这严重影响了模型的性能,成为其在现实应用中的主要障碍之一。
- 领域适应(DA)的研究:为提高模型对分布偏移的鲁棒性,领域适应(DA)旨在利用训练中可用的目标域数据使神经网络适应目标域,但目标域在常见训练场景中往往难以获取,限制了DA的应用。
- 领域泛化(DG)的研究:领域泛化(DG)旨在提高模型对任意未见域的泛化能力,常见做法是利用多个源域学习域不变特征,但存在难以确定理想源域以及收集和标注多源域数据成本高且有时不可行的问题。
- 联合视觉语言空间的特性:大规模预训练模型已观察到多种领域,其联合视觉语言空间中,文本特征可有效表示相关图像特征,且尽管存在模态差异,但存在跨模态迁移性现象,即可以使用文本特征训练分类器并使用图像特征进行推理,这为解决无源域数据的领域泛化问题提供了思路。

研究动机
- 利用大规模模型模拟分布偏移:作者思考能否在不使用任何源域数据的情况下,通过模拟大规模模型潜在空间中的各种分布偏移来进一步提高模型的泛化能力,若可行将使DG更具实用性,但该方法具有挑战性,因为无法获取源域和目标域的实际数据,仅知道目标任务定义(如类名)。
- 基于视觉语言模型解决无源DG问题:作者认为大规模视觉语言模型有助于解决无源域泛化这一具有挑战性的问题。
- 通过在联合视觉语言空间中利用文本特征表示图像特征的特性以及跨模态迁移性,可通过提示(prompt)模拟分布偏移,从而提出了PromptStyler方法。
- 该方法通过学习可学习的风格词向量来合成多样化风格,以模拟超球联合视觉语言空间(hyperspherical joint vision-language space) 中的分布偏移,同时考虑风格多样性和内容一致性,最后使用合成的特征训练分类器来实现领域泛化。

🔥提出的方法-PromptStyler
为解决无源域泛化问题,本文提出了PromptStyler方法,该方法主要通过在联合视觉语言空间中合成多样化风格来模拟分布偏移,从而提高模型的泛化能力,具体如下:
1. 风格词向量学习
-
在超球联合视觉语言空间(如CLIP潜在空间)中,通过随机初始化风格词向量 s i s_i si,并使用风格多样性损失 L s t y l e \mathcal{L}_{style} Lstyle和内容一致性损失 L c o n t e n t \mathcal{L}_{content} Lcontent来优化,以学习到多样化且不扭曲内容信息的风格词向量。
-
风格多样性损失:为最大化风格多样性,使学习到的风格特征相互正交,其计算方式为
L s t y l e = 1 i − 1 ∑ j = 1 i − 1 ∣ T ( P i s t y l e ) ∥ T ( P i s t y l e ) ∥ 2 ⋅ T ( P j s t y l e ) ∥ T ( P j s t y l e ) ∥ 2 ∣ \mathcal{L}_{style}=\frac{1}{i - 1}\sum_{j = 1}^{i - 1}\left|\frac{T(\mathcal{P}_{i}^{style})}{\|T(\mathcal{P}_{i}^{style})\|_{2}}\cdot\frac{T(\mathcal{P}_{j}^{style})}{\|T(\mathcal{P}_{j}^{style})\|_{2}}\right| Lstyle=i−11∑j=1i−1 ∥T(Pistyle)∥2T(Pistyle)⋅∥T(Pjstyle)∥2T(Pjstyle)
其中 T ( ⋅ ) T(\cdot) T(⋅)是预训练文本编码器, P i s t y l e \mathcal{P}_{i}^{style} Pistyle是风格提示。 -
内容一致性损失:为防止风格扭曲内容信息,使风格 - 内容特征与相应内容特征具有最高余弦相似度,计算方式为
L c o n t e n t = − 1 N ∑ m = 1 N log ( exp ( z i m m ) ∑ n = 1 N exp ( z i m n ) ) \mathcal{L}_{content}=-\frac{1}{N}\sum_{m = 1}^{N}\log\left(\frac{\exp(z_{imm})}{\sum_{n = 1}^{N}\exp(z_{imn})}\right) Lcontent=−N1∑m=1Nlog(∑n=1Nexp(zimn)exp(zimm))
其中 z i m n z_{imn} zimn是风格 - 内容特征与内容特征之间的余弦相似度得分,具体为
z i m n = T ( P i s t y l e ∘ P m c o n t e n t ) ∥ T ( P i s t y l e ∘ P m c o n t e n t ) ∥ 2 ⋅ T ( P n c o n t e n t ) ∥ T ( P n c o n t e n t ) ∥ 2 z_{imn}=\frac{T(\mathcal{P}_{i}^{style} \circ \mathcal{P}_{m}^{content})}{\|T(\mathcal{P}_{i}^{style} \circ \mathcal{P}_{m}^{content})\|_{2}} \cdot \frac{T(\mathcal{P}_{n}^{content})}{\|T(\mathcal{P}_{n}^{content})\|_{2}} zimn=∥T(Pistyle∘Pmcontent)∥2T(Pistyle∘Pmcontent)⋅∥T(Pncontent)∥2T(Pncontent) -
总提示损失:将风格多样性损失和内容一致性损失相加得到总提示损失 L p r o m p t = L s t y l e + L c o n t e n t \mathcal{L}_{prompt}=\mathcal{L}_{style}+\mathcal{L}_{content} Lprompt=Lstyle+Lcontent,用于顺序学习 K K K个风格词向量。
-

2. 使用多样化风格训练线性分类器
- 学习到 K K K个风格词向量后,利用预训练文本编码器 T ( ⋅ ) T(\cdot) T(⋅)和预定义的 N N N个类名合成 K N KN KN个风格 - 内容特征,用于训练线性分类器。
- 分类器采用 ArcFace 损失 L c l a s s \mathcal{L}_{class} Lclass进行训练,ArcFace 损失是一种角度 Softmax 损失,通过添加类间 角度边际惩罚( additive angular margin penalty) 来计算分类器输入特征与权重之间的余弦相似度,使不同类别的特征分得更开,从而实现更具判别性的预测。
3. 使用训练好的分类器进行推理。
- 在推理时,预训练图像编码器 I ( ⋅ ) I(\cdot) I(⋅)从输入图像中提取图像特征,经 ℓ 2 \ell_2 ℓ2归一化后映射到联合视觉语言空间,然后输入到训练好的分类器中产生类别分数。
- 此时文本编码器 T ( ⋅ ) T(\cdot) T(⋅)不参与推理过程,仅图像编码器 I ( ⋅ ) I(\cdot) I(⋅)被使用。


















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









