




目录
1、误差分析
首先当我们在设计一个算法的时候,我们通常会花很多时间在第一步的复杂构想上,然后设计出模型,当我们的算法基本成型的时候才发现问题(难点)的所在,这时,要修改其实就比较麻烦了,需要重新构思、修改模型。
这里我们推荐一种办法,通过设计一个简单粗暴的算法,一个最基础的系统,或许这个最基础的系统与我们所能构建的 “最佳” 系统相去甚远,但研究其中的基础功能也是很有价值的,我们可以用来找到算法的不足之处和难以处理的样本类型。
那么又怎么进行误差分析呢?
如吴恩达所讲授的垃圾邮件分类的例子中,我们找出在交叉验证集中一些分类错误的样本(100个),我们可以手动对这100个样本进行分类,然后找出是什么原因导致的分类错误(采用了拼音?字母变形?间隔符?等等原因,这里假设三种情况),假设这100个样本之中,由于垃圾邮件使用拼音导致分类错误的样本有90个,字母变形导致分类错误的样本有2个,间隔符导致的有8个。那么接下来我们是不是已经知道要重点优化那一部分的代码了。在我们重点优化拼音那一部分代码之后,我们可以发现这个算法的精度有着明显的提升了。
或许有人还会问到,如果我不知道这个参数是否有用(例如是否要将university和universe是否识别为同一个单词),我又应该怎么样去验证呢?我们可以利用交叉验证集,观察将universe和university视为用一个单词的算法精度和不视为同一个单词的精度,观察哪一个分类的精度会更高,则采取哪一种分类方式。
2、偏斜类问题
对于正例和负例的比率处于一个极端的情况(一类样本数比另一类样本数多很多),叫偏斜类问题。

对于偏斜类问题,单一的数值指标,即通过某个实数来评估你的学习算法,就不管用了,因为从准确率99.3%,到准确率99.5% 。看似数值提高了,但是实际效果没有什么帮助。
有另外一种评估度量值,叫查准率和召回率。
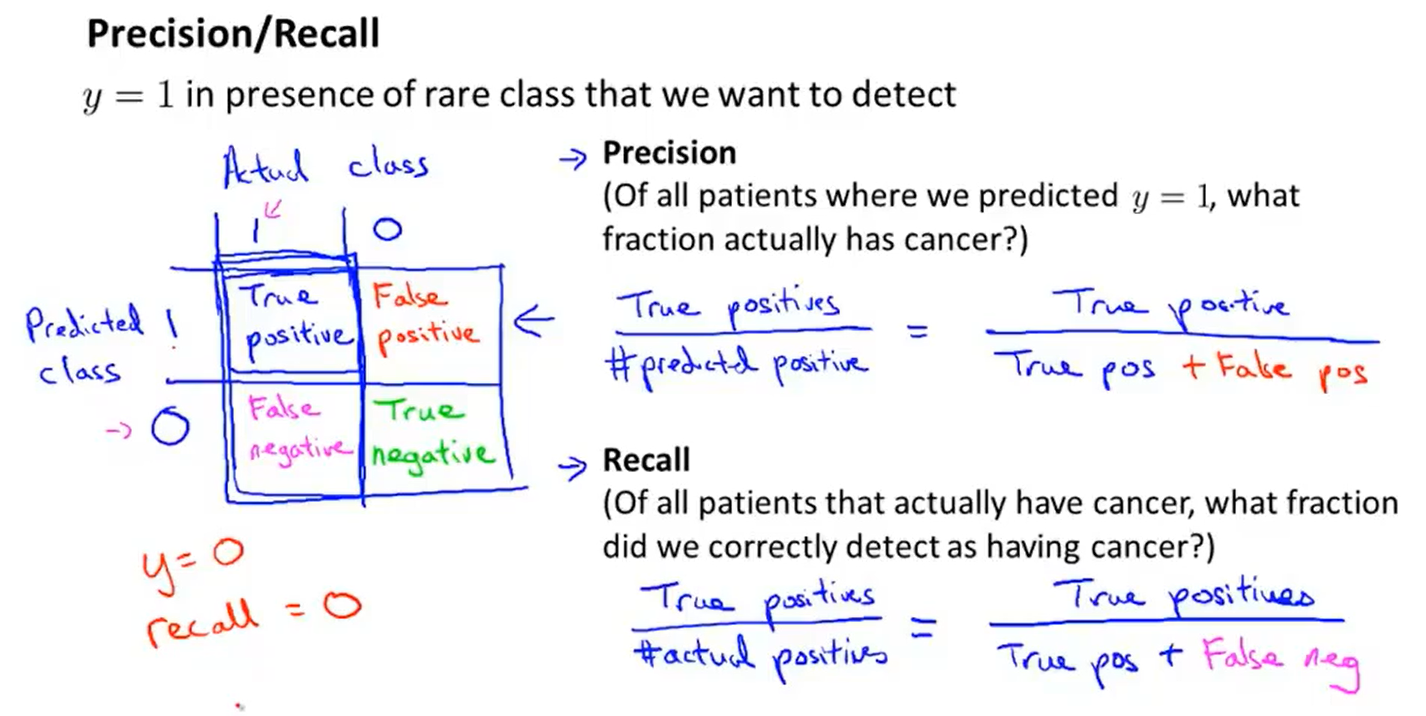
①正确肯定(TruePositive,TP):预测为真,实际为真 ;
②正确否定(TrueNegative,TN):预测为假,实际为假;
③错误肯定(FalsePositive,FP):预测为真,实际为假;
④错误否定(FalseNegative,FN):预测为假,实际为真。
对于分类问题,查准率和召回率高,这个算法就表现得好。
偏斜类问题,用查准率和召回率,比用分类误差或分类准确性好的多。
3、查准率和召回率的权衡
①沿用一下癌症预测的例子,当我们希望,我们能够非常准备才通知患者可能患有癌症时,我们可以修改预测模型,当y=1:h>0.7 ,h>0.9才通知患者。这是我们的查询率可以得到一个比较理想的值,但是回召率相对而言却比较低。
②当我们希望宁可误诊让患者虚惊一场,也不能让一个真正的癌症患者(FN)得不到治疗的情况下,我们可以使y=1: h>0.3,h>0.4就通知患者,及时诊断、治疗。这时我们的回召率就会比较高,查准率会比较低。

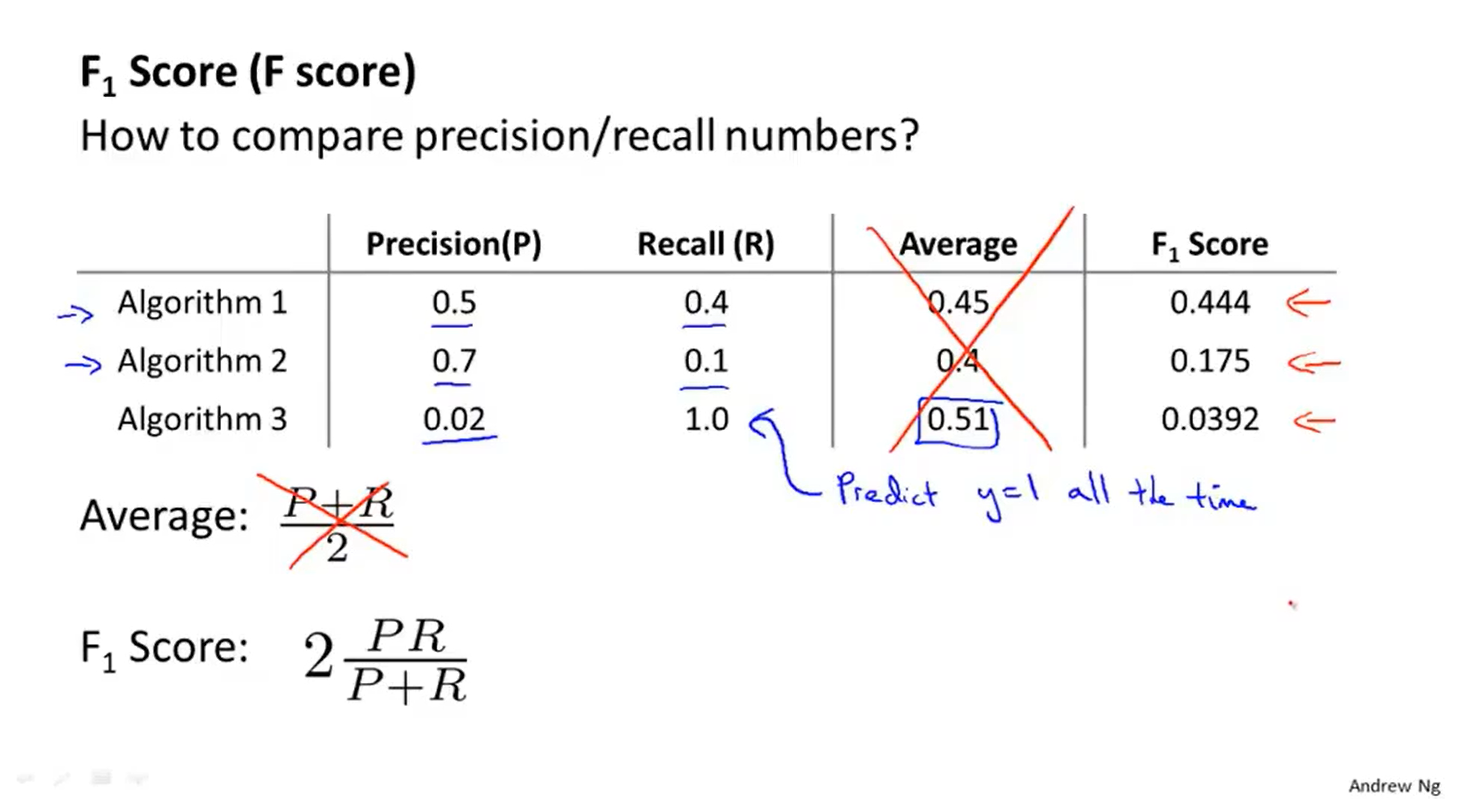
评估查准率和召回率的方法,计算F值,可以用它衡量算法好坏的标准。

















 2004
2004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









