







 本文详细介绍了DOM的概念、节点类型、节点操作方法等内容,包括如何获取、创建、插入、删除节点及属性等,帮助读者全面掌握DOM的基本操作。
本文详细介绍了DOM的概念、节点类型、节点操作方法等内容,包括如何获取、创建、插入、删除节点及属性等,帮助读者全面掌握DOM的基本操作。
目录
parentNode、previousSibling、nextSibling属性
DOM介绍
- DOM中的三个字母,D(文档)可以理解为整个Web加载的网页文档;O(对象)可以理解为类似window对象之类的东西,可以调用属性和方法,这里我们说的是document对象;M(模型)可以理解为网页文档的树型结构。
节点
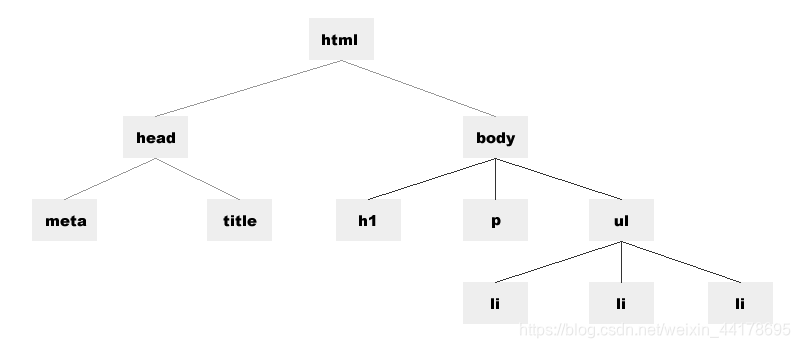
- ·加载HTML页面时,Web浏览器生成一个树型结构,用来表示页面内部结构。DOM将这种树型结构理解为由节点组成。
-
从上图的树型结构,我们理解几个概念,html标签没有父辈,没有兄弟,所以html标签为根标签。head标签是html子标签,meta和title标签之间是兄弟关系。如果把每个标签当作一个节点的话,那么这些节点组合成了一棵节点树。
PS:后面我们经常把标签称作为元素,是一个意思。
节点类型
节点种类:元素节点(标签)、文本节点(标签或文本框的值)、属性节点(标签)。
而这些节点又有三个非常有用的属性,分别为:nodeName、nodeType和nodeValue。
信息节点属性
| 节点类型 | nodeName | nodeType | nodeValue |
| 元素 | 元素名称 | 1 | Null(元素是标签没有值) |
| 属性 | 属性名称 | 2 | 属性值 |
| 文本 | #text | 3 | 文本内容(不包含html) |
元素节点方法
元素节点方法
| 方法 | 说明 |
| getElementById(“id”) | 获取特定ID元素的节点 |
| getElementsByTagName(“标签名”) | 获取相同元素的节点列表 |
| getElementsByName(“name”) | 获取相同名称的节点列表 |
| getAttribute(“属性”) | 获取特定元素节点属性的值 |
| setAttribute(“属性,值”) | 设置特定元素节点属性的值 |
| removeAttribute(“属性”) | 移除特定元素节点属性 |
getElementsByTagName()方法
- getElementsByTagName()方法将返回一个对象数组HTMLCollection(NodeList),这个数组保存着所有相同元素名的节点列表。
- document.getElementsByTagName('*'); //获取所有元素
-
document.getElementsByTagName('li'); //获取所有li元素,返回数组
document.getElementsByTagName('li')[0]; //获取第一个li元素,HTMLLIElement
document.getElementsByTagName('li').item(0) //获取第一个li元素,HTMLLIElement
document.getElementsByTagName('li').length; //获取所有li元素的数目
getElementsByName()方法
- getElementsByName()方法可以获取相同名称(name)的元素,返回一个对象数组HTMLCollection(NodeList)。
- document.getElementsByName('add') //获取input元素
- document.getElementsByName('add')[0].value //获取input元素的value值
- document.getElementsByName('add')[0].checked //获取input元素的checked值
getAttribute()方法
- getAttribute()方法将获取元素中某个属性的值。它和直接使用.属性获取属性值的方法有一定区别。
- document.getElementById('box').getAttribute('id');//获取元素的id值
- document.getElementById('box').id; //获取元素的id值
- document.getElementById('box').getAttribute('mydiv');//获取元素的自定义属性值
- document.getElementById('box').mydiv //获取元素的自定义属性值,非IE不支持
- document.getElementById('box').getAttribute('class');//获取元素的class值,IE不支持
- document.getElementById('box').getAttribute('className');//非IE不支持
PS:HTML通用属性style和onclick,IE7更低的版本style返回一个对象,onclick返回一个函数式。虽然IE8已经修复这个bug,但为了更好的兼容,开发人员只有尽可能避免使用getAttribute()访问HTML属性了,或者碰到特殊的属性获取做特殊的兼容处理。
setAttribute()方法
setAttribute()方法将设置元素中某个属性和值。它需要接受两个参数:属性名和值。如果属性本身已存在,那么就会被覆盖。
- document.getElementById('box').setAttribute('align','center');//设置属性和值
- document.getElementById('box').setAttribute('bbb','ccc');//设置自定义的属性和值
removeAttribute()方法
removeAttribute()可以移除HTML属性。
document.getElementById('box').removeAttribute('style');//移除属性
元素节点属性
- 通过上面的节点方法获取节点对象之后
- 就可以访问下面的属性
元素节点属性
| 属性 | 说明 |
| tagName | 获取元素节点的标签名 |
| innerHTML | 获取元素节点里的内容,非W3C DOM规范 |
PS:innerHTML必须是获取元素节点的时候才能输出里面包含的文本 直接获取文本节点就不能通过他获取文本内容的
PS:innerHTML和nodeValue第一个区别,就是取值的。那么第二个区别就是赋值的时候,nodeValue会把包含在文本里的HTML转义成特殊字符,从而达到形成单纯文本的效果。
HTML属性的属性
| 属性 | 说明 |
| id | 元素节点的id名称 |
| title | 元素节点的title属性值 |
| style | CSS内联样式属性值 |
| className | CSS元素的类 |
例:
- document.getElementById('box').id; //获取id
- document.getElementById('box').id = 'person'; //设置id
- document.getElementById('box').title; //获取title
- document.getElementById('box').title = '标题' //设置title
- document.getElementById('box').style; //获取CSSStyleDeclaration对象
- document.getElementById('box').style.color; //获取style对象中color的值
- document.getElementById('box').style.color = 'red'; //设置style对象中color的值
- document.getElementById('box').className; //获取class
- document.getElementById('box').className = 'box'; //设置class
层次节点属性
节点的层次结构可以划分为:父节点与子节点、兄弟节点这两种。当我们获取其中一个元素节点的时候,就可以使用层次节点属性来获取它相关层次的节点。
层次节点属性
| 属性 | 说明 |
| childNodes | 获取当前元素节点的所有子节点 |
| firstChild | 获取当前元素节点的第一个子节点 |
| lastChild | 获取当前元素节点的最后一个子节点 |
| ownerDocument | 获取该节点的文档根节点,相当与document,所有对象的跟节点都是document。三个=是比较对象的 |
| parentNode | 获取当前节点的父节点 |
| previousSibling | 获取当前节点的前一个同级节点 |
| nextSibling | 获取当前节点的后一个同级节点 |
| attributes | 获取当前元素节点的所有属性节点集合 |
firstChild和lastChild属性
firstChild用于获取当前元素节点的第一个子节点,相当于childNodes[0];lastChild用于获取当前元素节点的最后一个子节点,相当于childNodes[box.childNodes.length - 1]。
- alert(box.firstChild.nodeValue); //获取第一个子节点的文本内容
- alert(box.lastChild.nodeValue); //获取最后一个子节点的文本内容
ownerDocument属性
ownerDocument属性返回该节点的文档对象根节点,返回的对象相当于document。
alert(box.ownerDocument === document); //true,根节点
parentNode、previousSibling、nextSibling属性
parentNode属性返回该节点的父节点,previousSibling属性返回该节点的前一个同级节点,nextSibling属性返回该节点的后一个同级节点。
- alert(box.parentNode.nodeName); //获取父节点的标签名
- alert(box.lastChild.previousSibling); //获取前一个同级节点
- alert(box.firstChild.nextSibling); //获取后一个同级节点
attributes属性
attributes属性返回该节点的属性节点集合。
- document.getElementById('box').attributes //NamedNodeMap
- document.getElementById('box').attributes.length;//返回属性节点个数
- document.getElementById('box').attributes[0]; //Attr,返回最后一个属性节点
- document.getElementById('box').attributes[0].nodeType; //2,节点类型
- document.getElementById('box').attributes[0].nodeValue; //属性值
- document.getElementById('box').attributes['id']; //Attr,返回属性为id的节点
- document.getElementById('box').attributes.getNamedItem('id'); //Attr
节点操作
DOM不单单可以查找节点,也可以创建节点、复制节点、插入节点、删除节点和替换节点。
节点操作方法
| 方法 | 说明 |
| write() | 这个方法可以把任意字符串插入到文档中 |
| createElement() | 创建一个元素节点 |
| appendChild() | 将新节点追加到子节点列表的末尾 |
| createTextNode() | 创建一个文件节点 |
| insertBefore() | 将新节点插入在前面 |
| repalceChild() | 将新节点替换旧节点 |
| cloneNode() | 复制节点 |
| removeChild() | 移除节点 |
write()方法
write()方法可以把任意字符串插入到文档中去。
document.write('<p>这是一个段落!</p>')' ; //输出任意字符串
createElement()方法
createElement()方法可以创建一个元素节点。
document.createElement('p'); //创建一个元素节点
PS:createElement在创建一般元素节点的时候,浏览器的兼容性都还比较好。但在几个特殊标签上,比如iframe、input中的radio和checkbox、button元素中,可能会在IE6,7以下的浏览器存在一些不兼容。
var input = null;
if (BrowserDetect.browser == 'Internet Explorer' && BrowserDetect.version <= 7) {
//判断IE6,7,使用字符串的方式
input = document.createElement("<input type=\"radio\" name=\"sex\">");
} else {
//标准浏览器,使用标准方式
input = document.createElement('input');
input.setAttribute('type', 'radio');
input.setAttribute('name', 'sex');
}
document.getElementsByTagName('body')[0].appendChild(input);
appendChild()方法
appendChild()方法讲一个新节点添加到某个节点的子节点列表的末尾上。
var box = document.getElementById('box'); //获取某一个元素节点
var p = document.createElement('p'); //创建一个新元素节点<p>
box.appendChild(p); //把新元素节点<p>添加子节点末尾
createTextNode()方法
createTextNode()方法创建一个文本节点。
var text = document.createTextNode('段落'); //创建一个文本节点
p.appendChild(text); //将文本节点添加到子节点末尾
insertBefore()方法
insertBefore()方法可以把节点创建到指定节点的前面。
box.parentNode.insertBefore(p, box); //把<div>之前创建一个节点
PS:insertBefore()方法可以给当前元素的前面创建一个节点,但却没有提供给当前元素的后面创建一个节点。那么,我们可以用已有的知识创建一个insertAfter()函数。
function insertAfter(newElement, targetElement) {
//得到父节点
var parent = targetElement.parentNode;
//如果最后一个子节点是当前元素,那么直接添加即可
if (parent.lastChild === targetElement) {
parent.appendChild(newElement);
} else {
//否则,在当前节点的下一个节点之前添加
parent.insertBefore(newElement, targetElement.nextSibling);
}
}
repalceChild()方法
replaceChild()方法可以把节点替换成指定的节点。
box.parentNode.replaceChild(p,box); //把<div>换成了<p>
cloneNode()方法
cloneNode()方法可以把子节点复制出来。
-
var box = document.getElementById('box');
var clone = box.firstChild.cloneNode(true); //获取第一个子节点,true表示复制内容
box.appendChild(clone); //添加到子节点列表末尾
removeChild()方法
removeChild()方法可以把
box.parentNode.removeChild(box); //删除指定节点
类型
Node类型
Node接口是DOM1级就定义了,Node接口定义了12个数值常量以表示每个节点的类型值。除了IE之外,所有浏览器都可以访问这个类型。
Node的常量
| 常量名 | 说明 | nodeType值 |
| ELEMENT_NODE | 元素 | 1 |
| ATTRIBUTE_NODE | 属性 | 2 |
| TEXT_NODE | 文本 | 3 |
| CDATA_SECTION_NODE | CDATA | 4 |
| ENTITY_REFERENCE_NODE | 实体参考 | 5 |
| ENTITY_NODE | 实体 | 6 |
| PROCESSING_INSTRUCETION_NODE | 处理指令 | 7 |
| COMMENT_NODE | 注释 | 8 |
| DOCUMENT_NODE | 文档根 | 9 |
| DOCUMENT_TYPE_NODE | doctype | 10 |
| DOCUMENT_FRAGMENT_NODE | 文档片段 | 11 |
| NOTATION_NODE | 符号 | 12 |
虽然这里介绍了12种节点对象的属性,用的多的其实也就几个而已。
- alert(Node.ELEMENT_NODE); //1,元素节点类型值
- alert(Node.TEXT_NODE); //2,文本节点类型值
我们建议使用Node类型的属性来代替1,2这些阿拉伯数字,有可能大家会觉得这样岂不是很繁琐吗?并且还有一个问题就是IE不支持Node类型。
如果只有两个属性的话,用1,2来代替会特别方便,但如果属性特别多的情况下,1、2、3、4、5、6、7、8、9、10、11、12,你根本就分不清哪个数字代表的是哪个节点。当然,如果你只用1,2两个节点,那就另当别论了。
IE不支持,我们可以模拟一个类,让IE也支持。
if (typeof Node == 'undefined') { //IE返回
window.Node = {
ELEMENT_NODE : 1,
TEXT_NODE : 3
};
}
Document类型
Document类型表示文档,或文档的根节点,而这个节点是隐藏的,没有具体的元素标签。
或者说 Document就是整个文档,第一个子节点就是文档开头的<!DOCTYPE>声明
- document; //document
- document.nodeType; //9,类型值
- document.childNodes[0]; //DocumentType,第一个子节点对象
- document.childNodes[0].nodeType; //非IE为10,IE为8
- document.childNodes[1]; //HTMLHtmlElement
- document.childNodes[1].nodeName; //HTML
获取Body标签
之前我们采用的是:document.getElementsByTagName('body')[0],那么这里提供一个更加简便的方法:document.body。
document.body; //HTMLBodyElement
获取文档声明节点<!DOCTYPE>
在<html>之前还有一个文档声明:<!DOCTYPE>会作为某些浏览器的第一个节点来处理,这里提供了一个简便方法来处理:document.doctype。
document.doctype; //DocumentType
PS:IE8中,如果使用子节点访问,IE8之前会解释为注释类型Comment节点,而document.doctype则会返回null。
document.childNodes[0].nodeName //IE会是#Comment
Document遗留的属性和对象集合
在Document中有一些遗留的属性和对象合集,可以快速的帮助我们精确的处理一些任务。
//属性
document.title; //获取和设置<title>标签的值
document.URL; //获取URL路径
document.domain; //获取域名,服务器端
document.referrer; //获取上一个URL,服务器端
//对象集合
document.anchors; //获取文档中带name属性的<a>元素集合
document.links; //获取文档中带href属性的<a>元素集合
document.applets; //获取文档中<applet>元素集合,已不用
document.forms; //获取文档中<form>元素集合
document.images; //获取文档中<img>元素集合
Element类型
Element类型用于表现HTML中的元素节点。在DOM基础那章,我们已经可以对元素节点进行查找、创建等操作,元素节点的nodeType为1,nodeName为元素的标签名。
元素节点对象在非IE浏览器可以返回它具体元素节点的对象类型。
元素对应类型表
| 元素名 | 类型 |
| HTML | HTMLHtmlElement |
| DIV | HTMLDivElement |
| BODY | HTMLBodyElement |
| P | HTMLParamElement |
PS:以上给出了部分对应,更多的元素对应类型,直接访问调用即可。
Text类型
Text类型用于表现文本节点类型,文本不包含HTML,或包含转义后的HTML。文本节点的nodeType为3。
//在同时创建两个同一级别的文本节点的时候,会产生分离的两个节点。
var box = document.createElement('div');
var text = document.createTextNode('Mr.');
var text2 = document.createTextNode(张三!);
box.appendChild(text);
box.appendChild(text2);
document.body.appendChild(box);
alert(box.childNodes.length); //2,两个文本节点
//PS:把两个同邻的文本节点合并在一起使用normalize()即可。
box.normalize(); //合并成一个节点PS:有合并就有分离,通过splitText(num)即可实现节点分离。
box.firstChild.splitText(3); //分离一个节点
除了上面的两种方法外,Text还提供了一些别的DOM操作的方法如下:
var box = document.getElementById('box');
- box.firstChild.deleteData(0,2); //删除从0位置的2个字符
- box.firstChild.insertData(0,'Hello.'); //从0位置添加指定字符
- box.firstChild.replaceData(0,2,'Miss'); //从0位置替换掉2个指定字符
- box.firstChild.substringData(0,2); //从0位置获取2个字符,直接输出
- alert(box.firstChild.nodeValue); //输出结果
Comment类型
Comment类型表示文档中的注释。nodeType是8,nodeName是#comment,nodeValue是注释的内容。
var box = document.getElementById('box');
alert(box.firstChild); //Comment
PS:在IE中,注释节点可以使用!当作元素来访问。
var comment = document.getElementsByTagName('!');
alert(comment.length);
Attr类型
Attr类型表示文档元素中的属性。nodeType为11,nodeName为属性名,nodeValue为属性值。
在上面已经有过介绍了
DOM扩展
1.呈现模式
从IE6开始开始区分标准模式和混杂模式(怪异模式),主要是看文档的声明。IE为document对象添加了一个名为compatMode属性,这个属性可以识别IE浏览器的文档处于什么模式如果是标准模式,则返回CSS1Compat,如果是混杂模式则返回BackCompat。
if (document.compatMode == 'CSS1Compat') {
alert(document.documentElement.clientWidth);
} else {
alert(document.body.clientWidth);
}
PS:后来Firefox、Opera和Chrome都实现了这个属性。从IE8后,又引入documentMode新属性,因为IE8有3种呈现模式分别为标准模式8,仿真模式7,混杂模式5。所以如果想测试IE8的标准模式,就判断document.documentMode > 7 即可。
2.滚动
DOM提供了一些滚动页面的方法,如下:
document.getElementById('box').scrollIntoView(); //设置指定可见
3.children属性
由于子节点空白问题,IE和其他浏览器解释不一致。虽然可以过滤掉,但如果只是想得到有效子节点,可以使用children属性,支持的浏览器为:IE5+、Firefox3.5+、Safari2+、Opera8+和Chrome,这个属性是非标准的。
var box = document.getElementById('box');
alert(box.children.length); //得到有效子节点数目
4.contains()方法
判断一个节点是不是另一个节点的后代,我们可以使用contains()方法。这个方法是IE率先使用的,开发人员无须遍历即可获取此信息。
var box = document.getElementById('box');
alert(box.contains(box.firstChild)); //true
PS:早期的Firefox不支持这个方法,新版的支持了,其他浏览器也都支持,Safari2.x浏览器支持的有问题,无法使用。所以,必须做兼容。
在Firefox的DOM3级实现中提供了一个替代的方法compareDocumentPosition()方法。这个方法确定两个节点之间的关系。
var box = document.getElementById('box');
alert(box.compareDocumentPosition(box.firstChild)); //20关系掩码表
| 掩码 | 节点关系 |
| 1 | 无关(节点不存在) |
| 2 | 居前(节点在参考点之前) |
| 4 | 居后(节点在参考点之后) |
| 8 | 包含(节点是参考点的祖先) |
| 16 | 被包含(节点是参考点的后代) |
PS:为什么会出现20,那是因为满足了4和16两项,最后相加了。为了能让所有浏览器都可以兼容,我们必须写一个兼容性的函数。
//传递参考节点(父节点),和其他节点(子节点)
function contains(refNode, otherNode) {
//判断支持contains,并且非Safari浏览器
if (typeof refNode.contains != 'undefined' &&
!(BrowserDetect.browser == 'Safari' && BrowserDetect.version < 3)) {
return refNode.contains(otherNode);
//判断支持compareDocumentPosition的浏览器,大于16就是包含
} else if (typeof refNode.compareDocumentPosition == 'function') {
return !!(refNode.compareDocumentPosition(otherNode) > 16);
} else {
//更低的浏览器兼容,通过递归一个个获取他的父节点是否存在
var node = otherNode.parentNode;
do {
if (node === refNode) {
return true;
} else {
node = node.parentNode;
}
} while (node != null);
}
return false;
}
DOM操作
DOM操作内容
虽然在之前我们已经学习了各种DOM操作的方法,这里所介绍是innerText、innerHTML、outerText和outerHTML等属性。除了之前用过的innerHTML之外,其他三个还么有涉及到。
innerText属性
document.getElementById('box').innerText; //获取文本内容(如有html直接过滤掉)
document.getElementById('box').innerText = 'Mr.张三'; //设置文本(如有html转义)
PS:除了Firefox之外,其他浏览器均支持这个方法。但Firefox的DOM3级提供了另外一个类似的属性:textContent,做上兼容即可通用。
document.getElementById('box').textContent; //Firefox支持
//兼容方案
function getInnerText(element) {
return (typeof element.textContent == 'string') ?
element.textContent : element.innerText;
}
function setInnerText(element, text) {
if (typeof element.textContent == 'string') {
element.textContent = text;
} else {
element.innerText = text;
}
}innerHTML属性
这个属性之前就已经研究过,不拒绝HTML。
document.getElementById('box').innerHTML; //获取文本(不过滤HTML)
document.getElementById('box').innerHTML = '<b>123</b>'; //可解析HTML
//虽然innerHTML可以插入HTML,但本身还是有一定的限制,也就是所谓的作用域元素,离开这个作用域就无效了。
box.innerHTML = "<script>alert('张三');</script>"; //<script>元素不能被执行
box.innerHTML = "<style>background:red;</style>"; //<style>元素不能被执行outerText属性
outerText在取值的时候和innerText一样,同时火狐不支持,而赋值方法相当危险,他不单替换了文本内容,还将元素直接抹去。
var box = document.getElementById('box');
box.outerText = '<b>123</b>';
alert(document.getElementById('box')); //null,建议不去使用
outerHTML属性
outerHTML属性在取值和innerHTML一致,但和outerText也一样,很危险,赋值的之后会将元素抹去。
var box = document.getElementById('box');
box.outerHTML = '123';
alert(document.getElementById('box')); //null,建议不去使用,火狐旧版未抹去
PS:关于最常用的innerHTML属性和节点操作方法的比较,在插入大量HTML标记时使用innerHTML的效率明显要高很多。因为在设置innerHTML时,会创建一个HTML解析器。这个解析器是浏览器级别的(C++编写),因此执行JavaScript会快的多。但,创建和销毁HTML解析器也会带来性能损失。最好控制在最合理的范围内,如下:
for (var i = 0; i < 10; i ++) {
ul.innerHTML = '<li>item</li>'; //避免频繁
}
//改
for (var i = 0; i < 10; i ++) {
a = '<li>item</li>'; //临时保存
}
ul.innerHTML = a;
忽略空白文本节点
var body = document.getElementsByTagName('body')[0];//获取body元素节点
alert(body.childNodes.length); //得到子节点个数,IE3个,非IE7个
PS:在非IE中,标准的DOM具有识别空白文本节点的功能,所以在火狐浏览器是7个,而IE自动忽略了,如果要保持一致的子元素节点,需要手工忽略掉它。
function filterSpaceNode(nodes) {
var ret = []; //新数组
for (var i = 0; i < nodes.length; i ++) {
//如果识别到空白文本节点,就不添加数组
if (nodes[i].nodeType == 3 && /^\s+$/.test(nodes[i].nodeValue)) continue;
//把每次的元素节点,添加到数组里
ret.push(nodes[i]);
}
return ret;
}
PS:上面的方法,采用的忽略空白文件节点的方法,把得到元素节点累加到数组里返回。那么还有一种做法是,直接删除空白节点即可。
function filterSpaceNode(nodes) {
for (var i = 0; i < nodes.length; i ++) {
if (nodes[i].nodeType == 3 && /^\s+$/.test(nodes[i].nodeValue)) {
//得到空白节点之后,移到父节点上,删除子节点
nodes[i].parentNode.removeChild(nodes[i]);
}
}
return nodes;
}
PS:如果firstChild、lastChild、previousSibling和nextSibling在获取节点的过程中遇到空白节点,我们该怎么处理掉呢?
function removeWhiteNode(nodes) {
for (var i = 0; i < nodes.childNodes.length; i ++) {
if (nodes.childNodes[i].nodeType === 3 &&
/^\s+$/.test(nodes.childNodes[i].nodeValue)) {
nodes.childNodes[i].parentNode.removeChild(nodes.childNodes[i]);
}
}
return nodes;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









