







 本文详细介绍了深度学习优化算法中的梯度下降、随机梯度下降、小批量随机梯度下降以及动量法,包括动量法的泄漏平均值和Nesterov Accelerated Gradient(NAG)。这些算法在解决梯度下降法计算复杂度高和SGD稳定性差的问题上提供了有效的解决方案。
本文详细介绍了深度学习优化算法中的梯度下降、随机梯度下降、小批量随机梯度下降以及动量法,包括动量法的泄漏平均值和Nesterov Accelerated Gradient(NAG)。这些算法在解决梯度下降法计算复杂度高和SGD稳定性差的问题上提供了有效的解决方案。
概论
梯度下降不会直接用于深度学习,在生产环境中,会使用梯度下降的优化算法
深度学习中的目标函数通常是训练集中每个样本的损失函数平均值。给定 n n n个样本的训练数据集,假设 f i ( x ) f_i(x) fi(x)是第 i i i个训练样本的损失函数,其中 X X X是参数向量。然后我们得到目标函数
f ( X ) = 1 n ∑ i = 1 n f i ( X ) f(X) = \frac{1}{n}\sum_{i=1}^nf_i(X) f(X)=n1i=1∑nfi(X)
X X X的目标函数的梯度计算方式为
∇ f ( x ) = 1 n ∑ i = 1 n ∇ f i ( x ) \nabla f(x)=\frac{1}{n} \sum_{i=1}^n\nabla f_{i}(x) ∇f(x)=n1i=1∑n∇fi(x)
梯度下降法,每个自变量的计算代价是 O ( n ) \mathcal{O}(n) O(n),训练数据集较大时,时间复杂度较高。
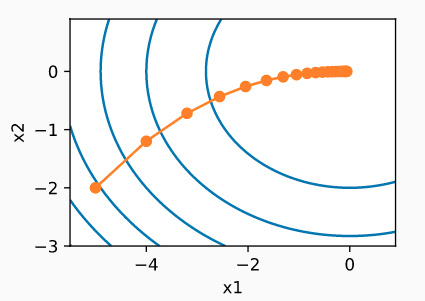
随机梯度下降
随机梯度下降(stochastic gradient descent)算法是深度学习中使用最广泛的优化算法。随机梯度下降(SGD)可降低每次迭代时的计算代价。在每次迭代过程中,我们对数据样本随机均匀采样一个索引 i i i,其中 i ∈ { 1 , … , n } i\in\{1,\ldots, n\} i∈{1,…,n},并计算梯度 ∇ f i ( x ) \nabla f_i(x) ∇fi(x)来更新 x x x
x ← x − η ∇ f i ( x ) x \leftarrow x- \eta \nabla f_i(x) x←x−η∇fi(x)
其中 η \eta η是学习率。每次迭代的时间复杂度从 O ( n ) \mathcal{O}(n) O(n)降低到 O ( 1 ) \mathcal{O}(1) O(1)。其中随机梯度 ∇ f i ( x ) \nabla f_i(x) ∇fi(x)是对完整梯度 ∇ f ( x ) \nabla f(x) ∇f(x)的无偏估计,因为
E i ∇ f i ( x ) = 1 n ∑ i = 1 n ∇ f i ( x ) = ∇ f ( x ) . \mathbb{E}_i \nabla f_i(\mathbf{x}) = \frac{1}{n} \sum_{i = 1}^n \nabla f_i(\mathbf{x}) = \nabla f(\mathbf{x}). Ei∇fi(x)=n1i=1∑n∇fi(x)=∇f(x).
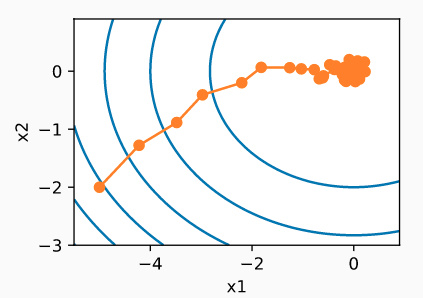
通过观察上图,我们能看出SGD变量的轨迹比梯度下降中的轨迹波动性要大,这正是由SGD的随机性导致的。当接近最小值时,参数受到 η ∇ f i ( x ) \eta \nabla f_i(x) η∇fi(x)不确定性影响,即使增加迭代的次数也不一定有效果。而剩下的唯一解决方案就是改变学习率 η \eta η。这就引出了学习率自适应算法,我们后面再讲。
小批量随机梯度下降
梯度下降算法使用完整的数据集计算梯度并更新参数,SGD用一个训练样本计算梯度和更新参数,这是两个极端情况。这里介绍折中的方案就是小批量随机梯度下降(minibatch gradient descent)
在深度学习中,执行 w ← w − η t g t w \leftarrow w - \eta _tg_t w←w−ηtgt时,如果每次更新一个样本,消耗资源非常大,其中 g t = ∂ w f ( x t , w ) g_t = \partial_wf(x_t,w) gt=∂wf(xt,w)。
我们将其应用在小批量观测值来提高梯度更新的计算效率。我们将单观察值更新梯度 g t g_t gt替换成一个小批量更新。
g t = ∂ w 1 ∣ B t ∣ ∑ i ∈ B t f ( x i , w ) . \mathbf{g}_t = \partial_{\mathbf{w}} \frac{1}{|\mathcal{B}_t|} \sum_{i \in \mathcal{B}_t} f(\mathbf{x}_{i}, \mathbf{w}). gt=∂w∣Bt∣1i∈Bt∑f(xi,w).
让我们看看这对 g t \mathbf{g}_t gt的统计属性有什么影响:由于 x t \mathbf{x}_t xt和小批量 B t \mathcal{B}_t Bt的所有元素都是从训练集中随机抽出的,因此梯度的期望保持不变。另一方面,方差显著降低。由于小批量梯度由正在被平均计算的 b : = ∣ B t ∣ b := |\mathcal{B}_t| b:=∣Bt∣个独立梯度组成,其标准差降低了 b − 1 2 b^{-\frac{1}{2}} b−21。这本身就是一件好事,因为这意味着更新与完整的梯度更接近了。
直观来说,这表明选择大型的小批量 B t \mathcal{B}_t Bt将是普遍可行的。然而,经过一段时间后,与计算代价的线性增长相比,标准差的额外减少是微乎其微的。在实践中我们选择一个足够大的小批量,它可以提供良好的计算效率同时仍适合GPU的内存。
动量法
SGD方法的一个缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定,因为数据有噪音。
Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。Momentum算法会观察历史梯度,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度。若当前梯度与历史梯度方向不一致,则梯度会衰减。
泄漏平均值
小批量随机梯度下降可以通过以下方式计算:
g t , t − 1 = ∂ w 1 ∣ B t ∣ ∑ i ∈ B t f ( x i , w t − 1 ) = 1 ∣ B t ∣ ∑ i ∈ B t h i , t − 1 . \mathbf{g}_{t, t-1} = \partial_{\mathbf{w}} \frac{1}{|\mathcal{B}_t|} \sum_{i \in \mathcal{B}_t} f(\mathbf{x}_{i}, \mathbf{w}_{t-1}) = \frac{1}{|\mathcal{B}_t|} \sum_{i \in \mathcal{B}_t} \mathbf{h}_{i, t-1}. gt,t−1=∂w∣Bt∣1i∈Bt∑f(xi,wt−1)=∣Bt∣1i∈Bt∑hi,t−1.
使用 h i , t − 1 = ∂ w f ( x i , w t − 1 ) \mathbf{h}_{i, t-1} = \partial_{\mathbf{w}} f(\mathbf{x}_i, \mathbf{w}_{t-1}) hi,t−1=∂wf(xi,wt−1)作为样本 i i i的随机梯度下降,使用时间 t − 1 t-1 t−1时更新的权重 t − 1 t-1 t−1。如果我们能够从方差减少的影响中受益,甚至超过小批量上的梯度平均值,那很不错。完成这项任务的一种选择是用泄漏平均值(leaky average)取代梯度计算:
v t = β v t − 1 + g t , t − 1 \mathbf{v}_t = \beta \mathbf{v}_{t-1} + \mathbf{g}_{t, t-1} vt=βvt−1+gt,t−1
其中 β ∈ ( 0 , 1 ) \beta \in (0, 1) β∈(0,1)。这有效地将瞬时梯度替换为多个“过去”梯度的平均值。 v \mathbf{v} v被称为动量(momentum),它累加了过去的梯度。为了更详细地解释,让我们递归地将 v t \mathbf{v}_t vt扩展到
v t = β 2 v t − 2 + β g t − 1 , t − 2 + g t , t − 1 = … , = ∑ τ = 0 t − 1 β τ g t − τ , t − τ − 1 . \begin{aligned} \mathbf{v}_t = \beta^2 \mathbf{v}_{t-2} + \beta \mathbf{g}_{t-1, t-2} + \mathbf{g}_{t, t-1} = \ldots, = \sum_{\tau = 0}^{t-1} \beta^{\tau} \mathbf{g}_{t-\tau, t-\tau-1}. \end{aligned} vt=β2vt−2+βgt−1,t−2+gt,t−1=…,=τ=0∑t−1βτgt−τ,t−τ−1.
其中,较大的 β \beta β相当于长期平均值,而较小的 β \beta β相对于梯度法只是略有修正。新的梯度替换不再指向特定实例下降最陡的方向,而是指向过去梯度的加权平均值的方向。这使我们能够实现对单批量计算平均值的大部分好处,而不产生实际计算其梯度的代价。
上述推理构成了"加速"梯度方法的基础,例如具有动量的梯度。在优化问题条件不佳的情况下(例如,有些方向的进展比其他方向慢得多,类似狭窄的峡谷),"加速"梯度还额外享受更有效的好处。此外,它们允许我们对随后的梯度计算平均值,以获得更稳定的下降方向。诚然,即使是对于无噪声凸问题,加速度这方面也是动量如此起效的关键原因之一。
梯度加速算法
Nesterov Accelerated Gradient,或者叫做Nesterov Momentum。
在小球向下滚动的过程中,我们希望小球能够提前知道在哪些地方坡面会上升,这样在遇到上升坡面之前,小球就开始减速。这方法就是Nesterov Momentum,其在凸优化中有较强的理论保证收敛。并且,在实践中Nesterov Momentum也比单纯的Momentum 的效果好。
输入和参数
- η \eta η - 全局学习率
- α \alpha α - 动量参数,缺省取值0.9
- v - 动量,初始值为0
算法
临时更新: θ ^ = θ t − 1 − α ⋅ v t − 1 \hat \theta = \theta_{t-1} - \alpha \cdot v_{t-1} θ^=θt−1−α⋅vt−1
前向计算: f ( θ ^ ) f(\hat \theta) f(θ^)
计算梯度: g t = ∇ θ ^ J ( θ ^ ) g_t = \nabla_{\hat\theta} J(\hat \theta) gt=∇θ^J(θ^)
计算速度更新: v t = α ⋅ v t − 1 + η ⋅ g t v_t = \alpha \cdot v_{t-1} + \eta \cdot g_t vt=α⋅vt−1+η⋅gt
更新参数: θ t = θ t − 1 − v t \theta_t = \theta_{t-1} - v_t θt=θt−1−vt
其核心思想是:注意到 momentum 方法,如果只看 α ⋅ v t − 1 \alpha \cdot v_{t-1} α⋅vt−1 项,那么当前的θ经过momentum的作用会变成 θ − α ⋅ v t − 1 \theta - \alpha \cdot v_{t-1} θ−α⋅vt−1。既然我们已经知道了下一步的走向,我们不妨先走一步,到达新的位置”展望”未来,然后在新位置上求梯度, 而不是原始的位置。
所以,同Momentum相比,梯度不是根据当前位置θ计算出来的,而是在移动之后的位置 θ − α ⋅ v t − 1 \theta - \alpha \cdot v_{t-1} θ−α⋅vt−1计算梯度。理由是,既然已经确定会移动 θ − α ⋅ v t − 1 \theta - \alpha \cdot v_{t-1} θ−α⋅vt−1,那不如之前去看移动后的梯度。
这个改进的目的就是为了提前看到前方的梯度。如果前方的梯度和当前梯度目标一致,那我直接大步迈过去; 如果前方梯度同当前梯度不一致,那我就小心点更新。
NAG 可以使 RNN 在很多任务上有更好的表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









