







 本文详细介绍了如何在完全分布式Hadoop环境中搭建Spark集群。首先,创建sparkCluster文件夹并解压缩Spark包,然后配置slaves文件和spark-env.sh文件。接着,将配置好的Spark文件夹复制到所有节点,并在slave节点上解压和配置。启动Hadoop后,依次启动Spark Master、Slaves。通过浏览器可以检查集群状态。关闭时,先停止Spark Master和Slaves,再停Hadoop集群。最后,提供了使用独立和YARN集群管理器提交应用的方法。
本文详细介绍了如何在完全分布式Hadoop环境中搭建Spark集群。首先,创建sparkCluster文件夹并解压缩Spark包,然后配置slaves文件和spark-env.sh文件。接着,将配置好的Spark文件夹复制到所有节点,并在slave节点上解压和配置。启动Hadoop后,依次启动Spark Master、Slaves。通过浏览器可以检查集群状态。关闭时,先停止Spark Master和Slaves,再停Hadoop集群。最后,提供了使用独立和YARN集群管理器提交应用的方法。
完全分布式Hadoop搭建可参考一下网址
https://blog.youkuaiyun.com/weixin_44168245/article/details/118941000
搭建spark集群
先创建一个sparkCluster文件夹

将spark包解压至sparkCluster中
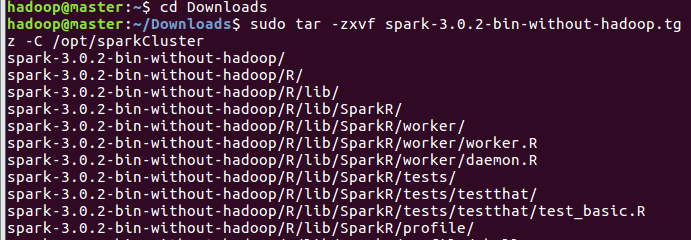
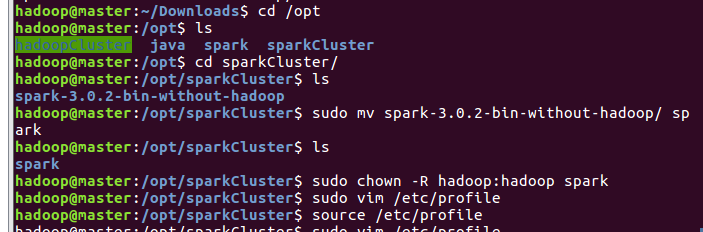
将解压后的文件名重命名为spark,同时把spark文件夹的权限赋给hadoop用户和hadoop组,最后配置环境变量

配置slaves文件和spark-env.sh文件(slaves文件设置Worker节点)
将 slaves.template 拷贝到 slaves,编辑slaves内容,把默认内容localhost替换成slave1,slave2
将 spark-env.sh.template 拷贝到 spark-en
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









