







大家好呀,我是前端创可贴。

上一章我们一起学习了 HTML 的历史、设计原则和基本介绍,这一章我们再一起来学习一下 HTML 的语法,并且会做出一些延伸,以此来更好的理解语法以及扩展自己的知识储备。

基本组成
一个 HTML 文档必须以指定顺序包含以下部分:
1. 可选的字节顺序标记(Byte Order Mark, BOM)字符;
2. 任意数量的注释和空格;
3. 一个 DOCTYPE;
4. 任意数量的注释和空格;
5. document element(这个名字很容易让人误解为 document element 就是 document 对象本身,但其实代表的是父元素是 document 对象的元素),用 html 元素来表示;
6. 任意数量的注释和空格。
HTML 语法中许多字符串(比如元素名称和属性名)对于英文字母是不区分大小写的(case-insensitive),所以要注意一个元素如果 2 个属性名全都小写后是相同的,只有第一个属性生效。
<div id="aaa" ID="bbb">前端创可贴</div>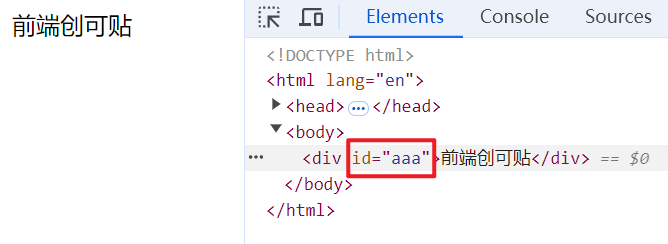
什么是 BOM
首先来解释一下上面说的字节顺序标记(Byte Order Mark, BOM)是个什么东西。
这个 BOM 可不是我们常说的浏览器的那个 BOM(Browser Object Model),Byte Order Mark (BOM) 是位于 DOCTYPE 之前的一个特殊字符,但它并不是直接写在 HTML 代码里的,而是作为文件的字节序列存在,它存在于文件的编码层面上,是文件的第一个字节序列。它的存在是通过特定的字节序列(例如 UTF-8 中的 EF BB BF)来标识的,使用十六进制编辑器打开文件,如果文件开头的字节是 EF BB BF,那么该文件就包含了表示 UTF-8 的 BOM。
BOM 的主要作用是帮助浏览器和其他应用程序自动识别文本文件的编码,尤其是 Unicode 编码(比如 UTF-8)。一些编辑器比如 Visual Studio Code、Notepad++ 等允许在保存文件时可以选择带有 BOM 的编码方式(例如 UTF-8 with BOM)。
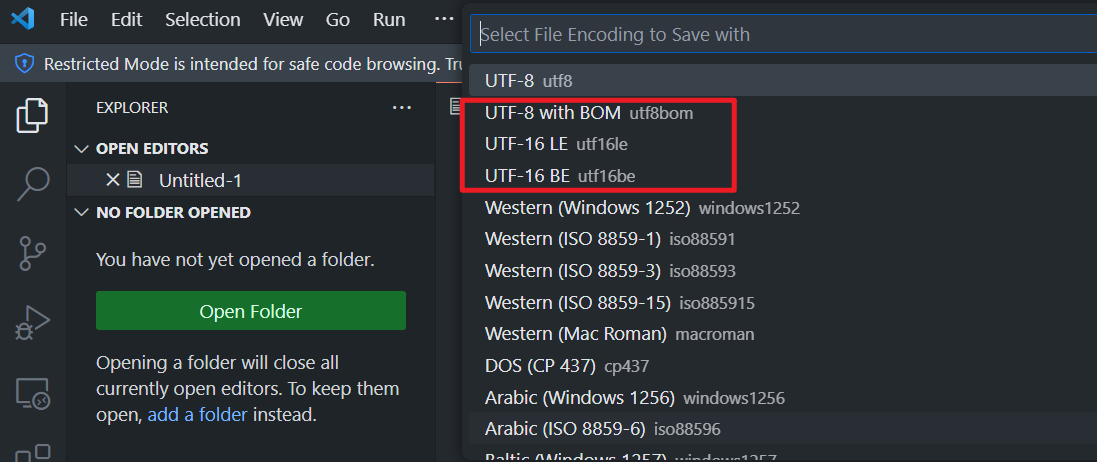
我们来用 VS Code 测试一下,用 UTF-8 with BOM 字符编码方式存储文件,并且用 16 进制查看文件内容。首先需要在 VS Code 下载 Hex Editor 插件,然后鼠标右键文件 -> Reopen Editor With -> Hex Editor,即可查看该文件 16 进制文件内容。
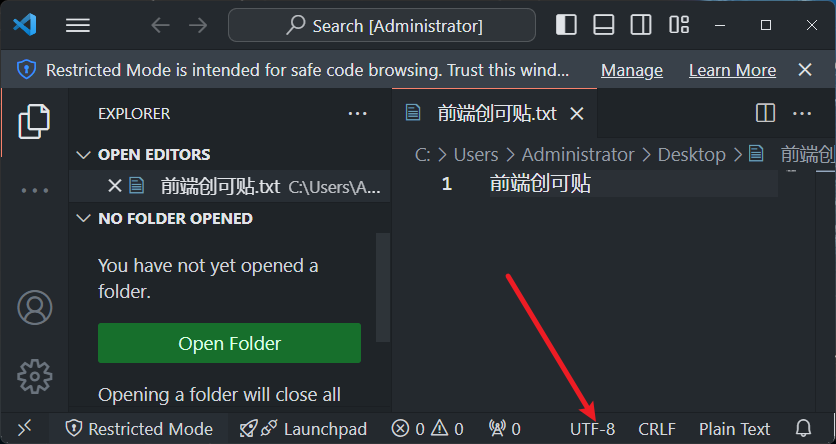
源文件是 UTF-8 的格式:
接下来我们将文件字符编码格式修改为 UTF-8 with BOM,然后查看 16 进制内容:
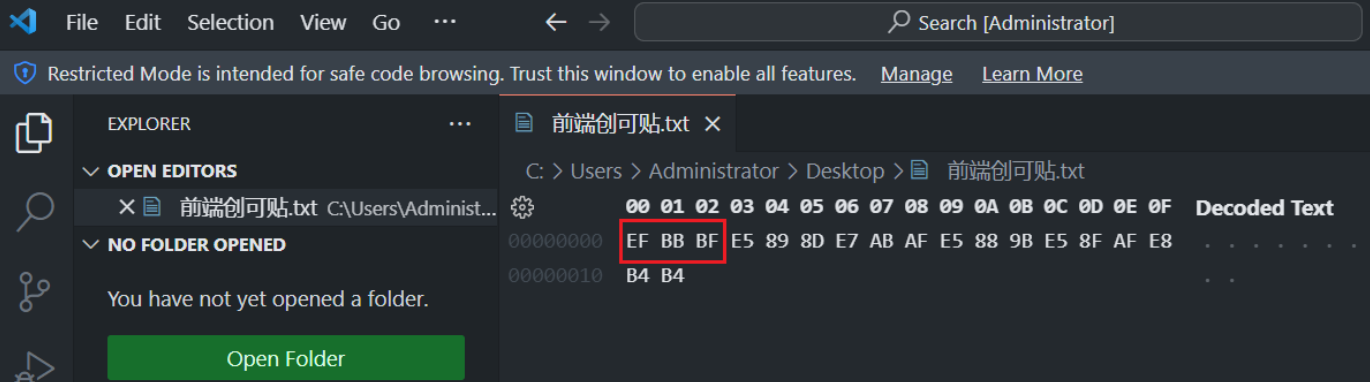
可以看到,UTF-8 with BOM 的字节序正由 EF BB BF 开头。
但是为什么我们开发过程中基本上没见过这个 BOM 呢?因为我们都会用 <meta charset="UTF-8"> 在 HTML 代码里显式的指定编码方式,毕竟 BOM 在我们代码里是看不见的。
对于 UTF-16 和 UTF-32,BOM 还可以负责指定字节存储顺序是大端序(Big-Endian)还是小端序(Little-Endian)。在各种计算机体系结构中,对于多字节的数据,这多个字节该以什么顺序存储呢?对于大端序,数据的高位存储在地址的低端,数据的低位存储在地址的高端;而小端序正好反过来,数据的高位存储在地址的高端,数据的低位存储在地址的低端。对于 UTF-16,如果含有 BOM,大端序的字节序是以 FE FF 开头,小端序是以 FF FE 开头。
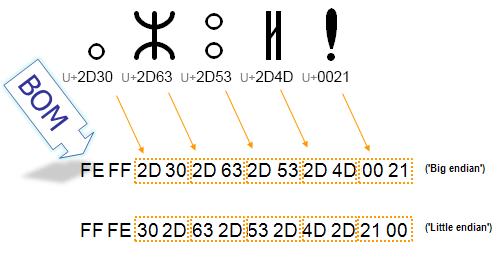
以 UTF-16 为例,它是可变长度编码方式,一个字符占 2 或 4 个字节。一个代码单元(Code Unit,一个字符由一到多个代码单元组成)16 位,即 2 个字节,一个字符至少由 2 个字节组成,那就存在这 2 个字节顺序如何存放和解析的问题,所以 BOM 需要指定 UTF-16 的字节存储顺序。
UTF-16 代码单元 16 位即 2 个 字节,最大值为 2^16 - 1 = 65535,加上 0 一个代码单元总共可以表示 65536 个字符,大部分常用的字符都被包含在内,所以大部分常用字符占据 2 个字节。
但是整个 Unicode 字符集个数远远超过 65536。超出 65536 的字符需要用代理对(Surrogate Pairs)存储,代理对是一对(即 2 个) 16 位的 code unit,表示一个单一字符,此时该字符就占据 4 个字节。
为了避免歧义,代理对的两部分的 code unit 的值都必须在 0xD800 和 0xDFFF 区间,并且这些 code unit 不能编码单一 code unit 的字符。(更准确的说,首位代理(leading surrogate)也被称为高位代理(high-surrogate)的 code unit,值在 0xD800 和 0xDBFF 区间,包含两端。尾部代理(trailing surrogate)也被称为低位代理(low-surrogare)的 code unit,值在 0xDC00 和 0xDFFF 区间,包含两端)。
而对于 UTF-8,一个代码单元 8 位即 1 个字节,虽然它也是可变长度的字符编码(使用 1-4 个字节),但是它的设计能通过每个字节中的特定位来识别出字节的类型(单字节、起始字节、后续字节),字节顺序对 UTF-8 没有影响
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









