









参与过数据资产、数据治理项目的朋友,肯定都听过数据血缘分析。关于数据血缘的定义是这样的:数据血缘,又称数据血统、数据起源、数据谱系,是指数据的全生命周期中,数据从产生、处理、加工、融合、流转到最终消亡,数据之间自然形成一种关系。其记录了数据产生的链路关系,这些关系与人类的血缘关系比较相似,所以被成为数据血缘关系。
在做数据血缘项目的第一步通常都是表级血缘。在开发过程规范的情况下,表级血缘特别简单,只需要用根据ETL加工代码找到程序里面用到的表就可以了。在规范的开发项目中,一个脚本或者一个SQL任务只能生成一个目标表数据,对应的一个目标表数据也只能由一个ETL任务来更新。做到了这个规范要求的企业,表级数据血缘做起来就非常简单。
问题就来了,能做到规范开发的企业就可以很容易实现表级数据血缘,做完表级数据血缘,就会有更高要求,想要字段级血缘;而做不到规范开发的企业,就会觉得表级数据血缘都很难实现,项目可能就止步于此了。
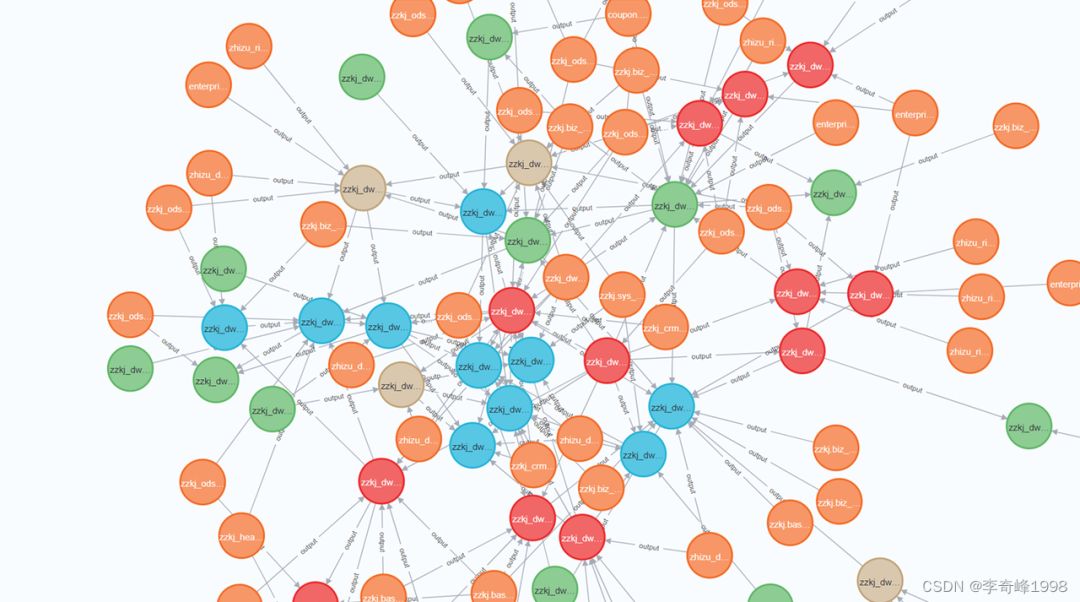
为什么做完表级数据血缘的企业会有字段级血缘的需求呢?其实这个需求最主要的需求方是项目的管理者。作为管理者,看到了表级血缘,肯定是不满意的,一个简单的逻辑包含了十几张表,根本看不出来里面的逻辑来,能不能打开黑箱,进一步透视一下?作为开发者肯定是,要看逻辑必须要看代码,然后去数据库查询和验证啊。但是领导是不会接受的,我当领导就是为了不看代码的,为了让开发过程可视化的,只有可视化的东西才能满足管理要求。从理论上看,表级数据血缘确实太粗糙了,如果从ADS层或者DWS层追溯到接口层,可能会出现几十张、上百张表,那是不是可以做字段级血缘呢?这样我们不就可以裁减逻辑了吗?如果只看一个字段的逻辑,是不是给我3-5个表的字段映射,我不就可以透视这个表的数据了吗?
大家都知道,理想很丰满,现实很骨感。数据ETL并不是简单的A字段映射成B字段,还存在各种关联、过滤、汇总、计算。一个看上去和逻辑毫无关联的表,通过一个join就可以让数据发散;一个看上去毫无作用的过滤也可以让数据丢失;汇总和计算则是完全改变了字段的业务逻辑,变成一个新的指标。理论上说,表级血缘分析中分析出来的任何一张表都有可能影响最终字段的数据,所以就算做出了,也是几十上百张表关联才能得到最终的逻辑。
作为一个资深的数据开发者,我认为这个事就不可能成。即使有些企业声称自己做到了字段级血缘,其实也就是是实现了其中比较简单的一部分内容,绝对做不到100%覆盖。字段级血缘做到30%很容易,做到90%需要努力,但是要做到100%,并且没有人工介入、没有手工维护逻辑是不可能实现的。当然,如果ChatGPT足够智能了,有可能替代人工完成这一功能,毕竟ChatGPT已经能自己写代码了,看懂人的代码也是迟早的事,难的是告诉AI工具,你到底要个啥。
那个数据血缘到底要个啥呢?首先说一下表级数据血缘的作用。表级数据血缘在调度依赖、任务优先级、任务依赖层级、接口切换等方面都有很实际的应用。表级数据血缘可以大概知道,一个目标表的数据会受到哪些上游表的影响,这个影响有可能是直接的,有可能是间接的,也有可能毫无影响。那么字段级血缘呢?字段级血缘最核心的诉求是看懂某个ADS层或者DWS层字段背后的数据加工过程,想知道这个字段的数据是不是准确,加工过程有没有BUG。但是字段只是表的一个部分,而数据仓库的表不一定都有业务主键,并且数据仓库的数据流动是逐层聚合的,越往上的逻辑越抽象,越抽象越难以溯源。
最后我想说一下,和字段级血缘类似的一个管理工具——数据映射。数据映射,也叫数据Mapping,一般是Excel格式,用于模型设计人员填写字段的加工逻辑和取数来源。数据mapping在银行数仓中应用很普遍,也是我早期做数据开发绕不开的一个工作内容。一个典型的表数据映射如下图:
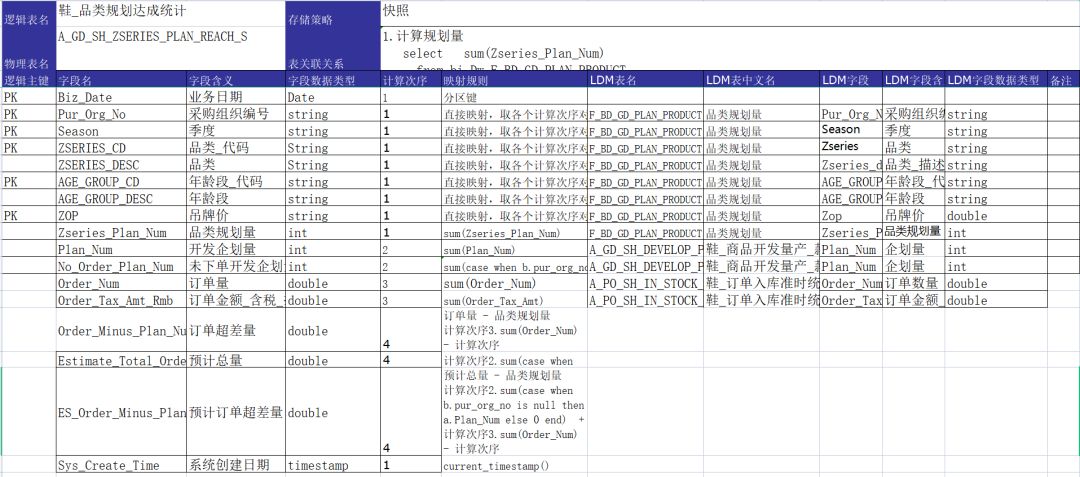
正是因为我多年填写数据映射的经验,所以对字段级血缘分析的难度有深刻的认识。连单表的字段级血缘都写得那么痛苦,你让程序去自动生成跨表、跨层级的字段级血缘,是不是有点太为难计算机了?
最后总结一下,为什么说字段级血缘分析是一个伪需求呢?简单的说,领导很想要,产品做不到,开发不敢用。
字段级血缘这么难做,那我们就不做了吗?其实,我觉得还是有两个方向可以努力的。第一,不考虑字段加工逻辑,做好字段的使用情况分析,每一层程序透视一下每张表用到的 字段,这个在字段下线、字段逻辑变更时是一个很重要的参考。第二,根据表级别数据血缘做好模型优化,减少数据加工层级,如果数仓的数据加工层级能压缩到10层以内,字段级数据血缘做不做就不重要了。但是实际情况是,由于开发的独立性和不规范,导致数仓的数据依赖流程通常高达三四十层甚至上百层,对于这种人工溯源难度太大的数据仓库,难怪管理者想要可以做字段级血缘,透视字段加工过程。
以上是我都一家之言,也是个人工作经验总结。支持的欢迎点赞转发,反对的可以评论区讨论。

《Doris实时数仓实战》已于京东、淘宝、当当、拼多多等平台上架,欢迎有需要的朋友下单购买。

















 5149
5149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









