









Python自动化(5)——ocr识字
通过网络识字
网络识字的平台有很多,主要有百度以及科大讯飞,这里以百度智能云来简单示例。
首先需要在百度智能云上注册一个账号,并创建一个应用,网址:
https://console.bce.baidu.com/ai/#/ai/ocr/app/list

获取到API Key和Secret Key之后,python安装request模块。
接下来就可以写代码了,此处直接上代码(部分):
获取百度智能云的access token
def getAccessToken(self):
# 获取token值
# client_id 为官网获取的API_KEY, client_secret 为官网获取的SECRET_KEY
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=' + \
'client_credentials&client_id=' + self.apiKey + \
'&client_secret=' + self.secretKey
response = requests.get(host)
access_token = response.json()['access_token']
return access_token
# 联网识字,通过百度api识字
# @border 识别区域
# @type 识别方式,默认是2(通用文字识别(标准含位置版))
def getWordsByBaiDu(self, border=None, type=2):
assessToken = self.getAccessToken()
request_url = None
if type == self.type_general_basic:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"# 通用文字识别(标准版)1000次/月,QPS/并发:2qps
elif type == self.type_general:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general"# 通用文字识别(标准含位置版)1000次/月,QPS/并发:2qps
elif type == self.type_accurate_basic:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"# 通用文字识别(高精度版)1000次/月,QPS/并发:2qps
elif type == self.type_accurate:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate"# 通用文字识别(高精度含位置版)500次/月,QPS/并发:2qps
elif type == self.type_webimage:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/webimage"# 网络图片文字识别 1000次/月,QPS/并发:2qps
elif type == self.type_webimage_loc:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/webimage_loc"# 网络图片文字识别(含位置版)总量500次,QPS/并发:2qps
elif type == self.type_table:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/table"# 表格文字识别V2 500次/月,QPS/并发:2qps
elif type == self.type_handwriting:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/handwriting"# 手写文字识别 500次/月,QPS/并发:2qps
elif type == self.type_numbers:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/numbers"# 数字识别 1000次/月,QPS/并发:2qps
#
qimg = self.screen.captureScreen('getWords.png', border)
try:
f = open('getWords.png', 'rb')
imgBytes = base64.b64encode(f.read())
params = {"image":imgBytes}
request_url = request_url + "?access_token=" + assessToken
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
print(str(response.json()["words_result"]))
except Exception as e:
print('网络识图出错了')
print(str(e))
return []
else:
return response.json()["words_result"]
这里我实现的是通过截图的方式保存一张临时图片,然后再发送这张图片给百度识字。其中,self.apiKey填写获取到的API Key,self.secretKey填写获取到的Secret Key。百度智能云的OCR分了很多种不同场景使用的API,并且免费版的有次数和迸发限制,具体如下:
通用文字识别(标准版)1000次/月,QPS/并发:2qps
通用文字识别(标准含位置版)1000次/月,QPS/并发:2qps
通用文字识别(高精度版)1000次/月,QPS/并发:2qps
通用文字识别(高精度含位置版)500次/月,QPS/并发:2qps
网络图片文字识别 1000次/月,QPS/并发:2qps
网络图片文字识别(含位置版)总量500次,QPS/并发:2qps
表格文字识别V2 500次/月,QPS/并发:2qps
手写文字识别 500次/月,QPS/并发:2qps
数字识别 1000次/月,QPS/并发:2qps
其它的业务不免费。
使用一个文本文档来测试一下,测试代码以及结果:
from PyQt5.QtWidgets import QApplication
import sys
app = QApplication(sys.argv)
t = Text()
t.bind(2102088)
r = t.getWordsByBaiDu()
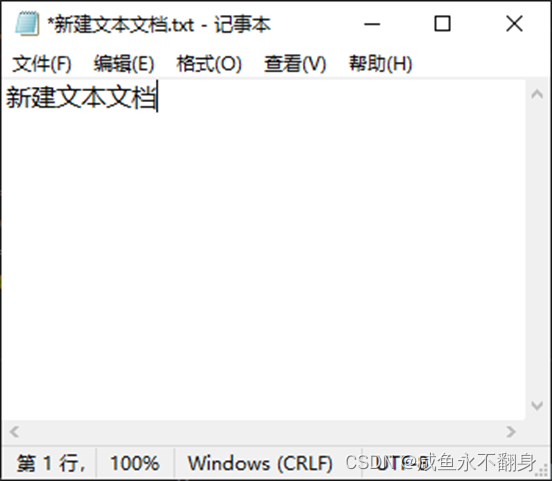

可以看到,基本上能正确识别出来结果(只是多了一个“》”号)。
这种方法的优缺点也很明显,优点是使用的是百度的识字模型,百度的识字模型一般都不会太差,并且也不用把模型保存在本地,可以省点空间,使用起来也很快捷。缺点是需要网络,并且有迸发限制,次数限制,还有网络延迟,可以说缺点比较多,因此更建议使用本地的OCR识字模块。
使用Easy OCR识字
首先安装EasyOCR模块。
接下来就比较简单,就是通过easyocr的模型来识别图片中的文字,直接上代码:
import easyocr
self.easyocr = easyocr.Reader(['ch_sim','en'])
def getWordsByEasyOcr(self, border=None):
qimg = self.screen.captureScreen(None, border)
res = self.easyocr.readtext(self.screen.qimageToNDArray(qimg))
print('getWordsByEasyOcr words: '+str(res))
return res
测试代码:
from PyQt5.QtWidgets import QApplication
import sys
app = QApplication(sys.argv)
t = Text()
t.bind(2691300)
r = t.getWordsByEasyOcr()
这里用到了屏幕截图的qimageToNDArray方法,就是用于将截取出来的图片(QImage类型)转换成可以被easyocr识别的NDArray类型。因为用到了屏幕截图,所以还是需要加上QApplication类
结果:

首次运行时,easyocr会自动下载所需的模型到电脑里,下载位置:C:\Users\Administrator.EasyOCR
创建easyocr的时候,传入的第一个参数是需要识别的语言,是一个数组,可以同时识别多种语言,easyocr常用的语言代号:
ch_sim:简体中文
ch_tra:繁体中文
en:英语
ja:日语
ko:韩语
de:德语
fr:法语
es:西班牙语
pt:葡萄牙语
注意,初始化easyocr时,会有一个warnning,意思是,CUDA不可用,默认使用CPU,使用GPU时,此模块的速度要快得多。如果要使用的话,可以开启显卡的CUDA功能,不过此处不做说明(因为本人也没有开启…)。创建easyocr类的时候是默认开启的,就算设置成不开启,也会弹提示,因此这里我就没管。
后面就是识字的结果,可以看到,是正确识别出我所输入的文本了。结果是一个大数组,每一段识别出来的文本都是一个元组(使用英文小括号括住的),元组里面第一个数组就是识别出的文本区域4个点的坐标,接着是识别出的文本,以及识别结果的相似度。
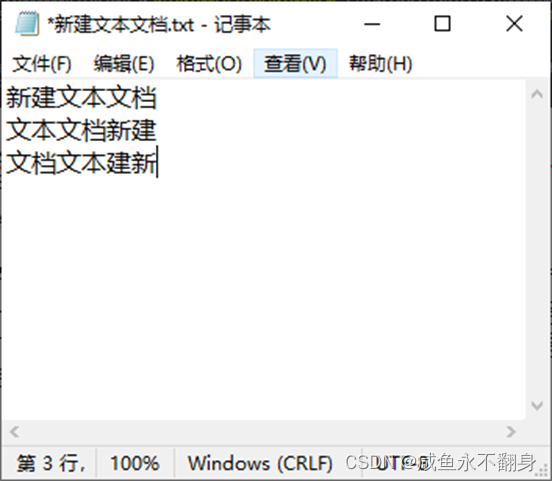

多行文本会识别出多段结果。
当然,easyocr也可以直接识别一张图片,传入一张图片的地址就行,例如:
t.easyocr.readtext(‘xxx.png’)
这样也能识别出图片中的文本。不过easyocr有一个问题,就是识别多行文本的时候,可能会识别不出来(我就试过,不过忘记了复现不出来),因此我使用了paddleocr。
使用Paddle OCR识字
paddlerocr的使用和easyocr其实差别不大,首先安装paddleocr模块。
接着同样是使用paddleocr直接识别就行:
self.paddleOcr = PaddleOCR(use_angle_cls=True, lang="ch")
def getWordsByPaddleocr(self, border=None):
qimg = self.screen.captureScreen(None, border)
res = self.paddleOcr.ocr(self.screen.qimageToNDArray(qimg))
print('getWordsByPaddleocr words: '+str(res))
return res
与easyocr相同,使用paddleocr同样需要下载模型,首次运行时会自动下载所需的模型。创建paddleocr时,use_angle_cls参数用于确定是否使用角度分类模型,即是否识别垂直方向的文字。lang参数定义需要识别的文字类型,ch是中文。
Paddleocr常用的语言代号:
ch:中文
en:英语
japan:日语
korean:韩语
german:德语
fr:法语
测试代码:
from PyQt5.QtWidgets import QApplication
import sys
app = QApplication(sys.argv)
t = Text()
t.bind(2691300)
r = t.getWordsByPaddleocr()
结果:
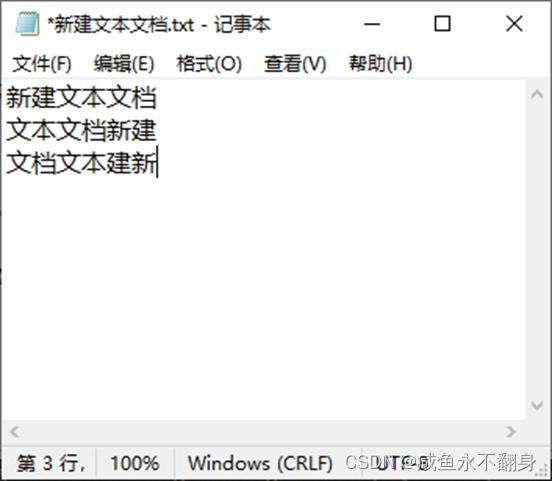
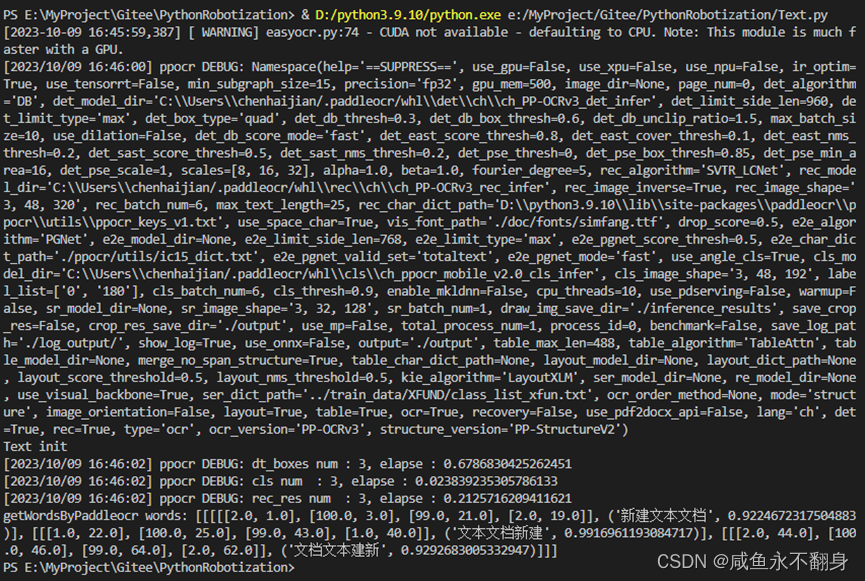
paddlerocr初始化时会有一大堆的log输出,这些可以忽略。识别结果还是比较准确的,格式和easyocr稍微有些不一样,这里我改了下方法,让识别结果的格式与easyocr识别结果一致。
def getWordsByPaddleocr(self, border=None):
qimg = self.screen.captureScreen(None, border)
res = self.paddleOcr.ocr(self.screen.qimageToNDArray(qimg))
easyOcrRes = [] # 转换成EasyOcr的返回格式
for i in range(len(res[0])):
pos = res[0][i][0]
text = res[0][i][1][0]
similar = res[0][i][1][1]
easyOcrRes.append((pos, text, similar))
print('getWordsByPaddleocr words: '+str(res))
return easyOcrRes
这样识别出来的结果经过封装后,和easyocr识别结果的格式一致了,这样使用的时候会方便一点。
完整自动化工程代码:https://gitee.com/chj-self/PythonRobotization
大佬们找到问题欢迎拍砖~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









