






 文章提出了一种名为CCAH的新方法,它利用CLIP进行无监督的视觉-文本检索。通过循环对齐哈希,CCAH在模态内和模态间实现语义对齐,改善了无监督模型的检索性能。该方法包括深度特征提取、循环对齐和哈希编码学习,提高了跨模态检索的准确性。
文章提出了一种名为CCAH的新方法,它利用CLIP进行无监督的视觉-文本检索。通过循环对齐哈希,CCAH在模态内和模态间实现语义对齐,改善了无监督模型的检索性能。该方法包括深度特征提取、循环对齐和哈希编码学习,提高了跨模态检索的准确性。
文章目录
CCAH: A CLIP-Based Cycle Alignment Hashing Method for Unsupervised Vision-Text Retrieval【Hindawi,International Journal of Intelligent Systems,Volume 2023】
基于CLIP的无监督视觉-文本检索循环对齐哈希方法
Abstract
存在问题:
图片通常附有相应的文字描述而不是标签。然而,由于 模态划分(modal divide) 和 语义差异(semantic differences) ,现有的无监督方法不能充分弥合模态差距,导致检索结果不理想。
文本提出: 基于CLIP的循环对齐哈希算法 用于无监督视觉文本检索(CCAH)
其目的是利用 模态原始特征 与 重构特征 之间的语义联系。
-
首先,我们设计了一种 模态循环交互方法(modal cyclic interaction method),在模态内进行语义对齐,其中一个模态特征重构另一个模态特征,从而充分考虑了模态内和模态间关系的语义相似性。
-
其次,将 GAT 引入到跨模态检索任务。我们考虑了文本邻居节点的影响,并添加了注意力机制来捕捉文本模态的全局特征。
-
第三,使用 CLIP视觉编码器 对图像特征进行 细粒度提取。
-
最后,通过哈希函数学习哈希编码。
1 Introduction
存在问题
无监督方法的一个共同缺点是,由于缺乏标记信息引导,视觉-文本中固有的共现信息在高级语义特征提取过程中很容易被忽略(图1)。
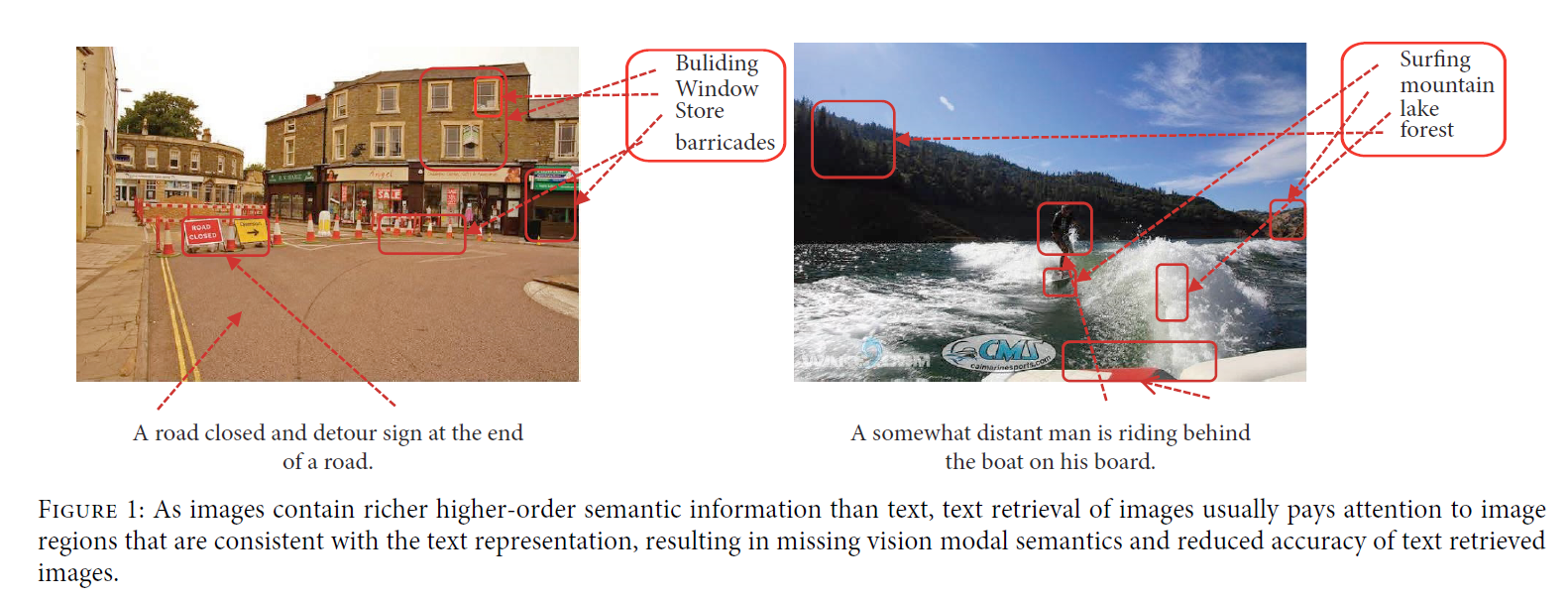
这进一步导致无监督模型无法准确捕获不同模态数据之间的语义连接,使得检索精度次优。鉴于此,我们指出成对出现的图像和文本的哈希码应该具有最小的汉明距离或最大的语义相似度。
此外,大多数现有的跨模态方法 侧重于跨模态数据之间语义特征的对齐(GAN)。
简化模态内重构特征与原始特征的语义关联 使得生成的哈希码不能完全兼容跨模态检索任务。
不可避免地,在高级语义交互中存在 固有的模态划分问题,即 不能同时关注 自己模态的模态内和模态间的语义信息,也不能将 模态特征的对齐 和 哈希编码 连接起来,从而导致检索结果无法获得最优解。
解决方案——CCAH
为了解决上述问题,本文提出了一种新的深度无监督循环语义对齐跨模哈希方法,即 基于CLIP的无监督视觉文本检索循环对齐哈希方法(CCAH)。
CCAH是一个端到端的学习框架,它同时注意到模态内和模态间的语义特征和哈希码的一致性。
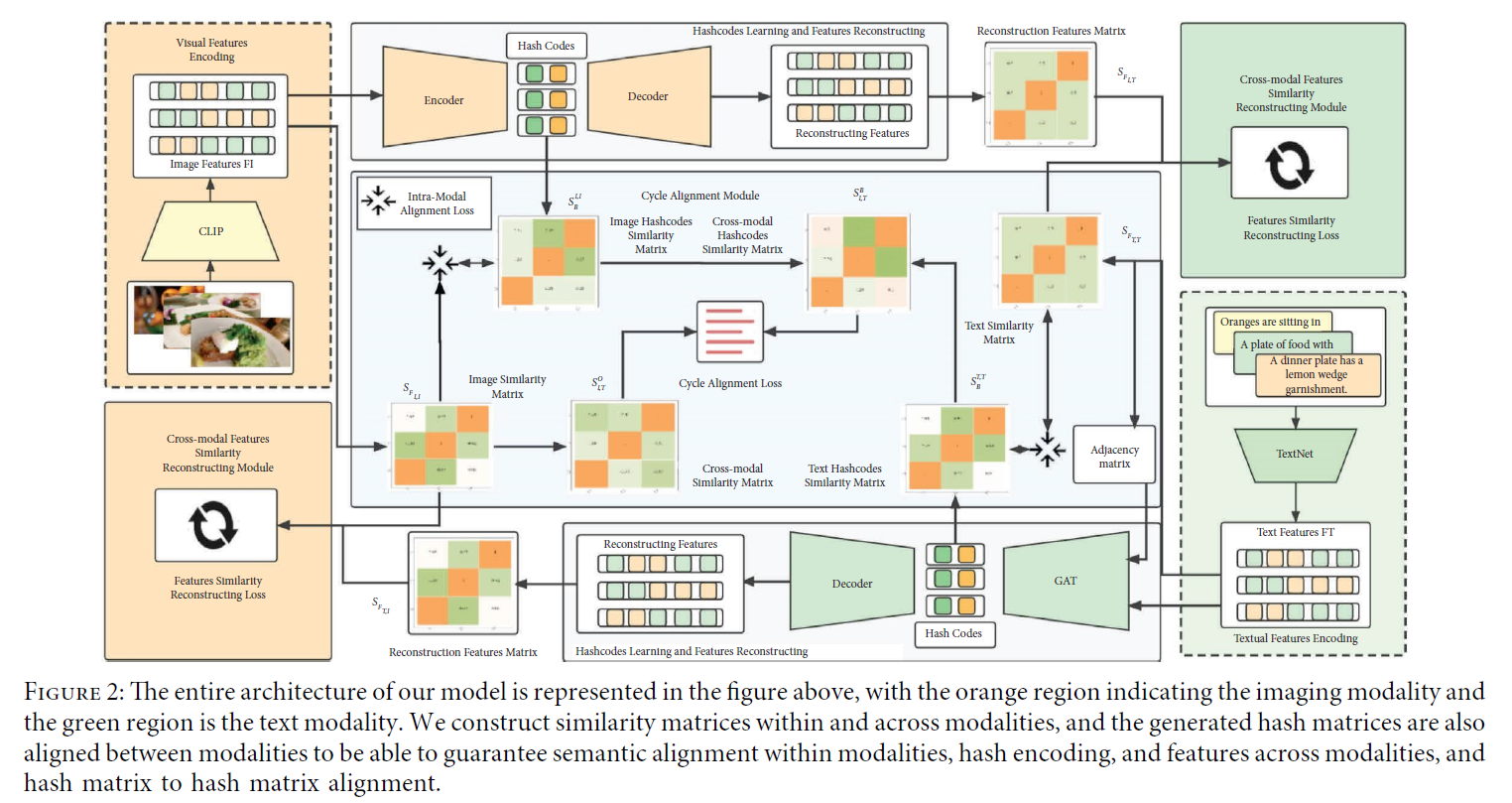
我们的CCAH网络模型由三个部分组成:
- 深度特征提取deep feature extraction
- 循环对齐cycle alignment
- 哈希编码学习hash encoding learning
之前的无监督网络模型在 文本检索图像 中存在准确率低的问题。
在图像文本对中,图像包含更丰富的语义信息,可以在更好的层面提取更高层次的语义表示。
相对于对应的文本描述(例如,BOW),文本的语义信息相对较少,通常只有少数几个关键词可以匹配到描述的图像区域(注意点attention points)。
此外,文本具有上下文关系,同一个单词可能代表不同的语义信息,导致文本检索图像往往不如图像检索文本准确。
我们提出 将文本作为图结构中的数据,将文本特征转化为图中的节点信息,利用GAT网络进一步融合稀疏文本特征,并将相关相邻节点信息与原始节点融合在注意力评分机制中,而注意力评分则表示不同节点之间的联系紧密程度,得分越高关联越紧密。利用自编码器对提取的模态特征进行编码和解码。
Contributions
- 我们提出了一种新的深度哈希网络模型CCAH。CLIP被用作视觉编码器来提取细粒度特征。GAT网络也用于文本模态的特征提取。
- 我们提出了一种循环对齐方法,将图像特征与自编码器提取的特征对齐,然后将特征映射到文本模态空间后对齐,以确保模态之间的语义连接,反之亦然。
- 实验表明,在三种常用的多模态数据集上,我们的模型在总检索精度方面取得了令人满意的结果。
2 Related Work
2.1 Supervised Hashing Methods
2.2 Unsupervised Hashing Methods
3 Problem Formulation
m m m 个图像-文本对,数据结构定义为 O = { o i } i = 1 m O = \{o_i\}_{i=1}^m O={oi}i=1m
-
I i I_i Ii 表示第 i i i 个图像, T j T_j Tj 表示第 j j j 个文本
-
每个图像文本对实例表示为: o k = { I k , T k } o_k = \{I_k, T_k\} ok={Ik,Tk}
-
特征维度表示为 F F F
- 由视觉特征编码器提取的语义特征表示为
F
I
∈
R
m
×
D
I
F_I \in R^{m \times D_I}
FI∈Rm×DI
- D I D_I DI 是将原始视觉通过图像编码器传递得到的图像的高维特征表示
- 将本文编码器后的文本特征表示为
F
T
∈
R
m
×
D
T
F_T \in R^{m \times D_T}
FT∈Rm×DT
- D T D_T DT 表示文本的高级特征维度表示
- 由视觉特征编码器提取的语义特征表示为
F
I
∈
R
m
×
D
I
F_I \in R^{m \times D_I}
FI∈Rm×DI
-
哈希码表示为 B ∗ ∈ { − 1 , + 1 } m × c B_* \in \{-1,+1\}^{m \times c} B∗∈{−1,+1}m×c, ∗ ∈ { I , T } * \in \{I,T\} ∗∈{I,T}
- c c c 表示哈希码的长度
- B ∗ B_* B∗ 中第 i i i 个原始数据的哈希码记为 b ∗ , i b_{*,i} b∗,i
此外,使用图像文本对的余弦相似度 c o s ( ⋅ ) cos(\cdot) cos(⋅) 作为损失函数,并使用 s i g n ( ⋅ ) sign(\sdot) sign(⋅) 函数作为元素级符号函数:
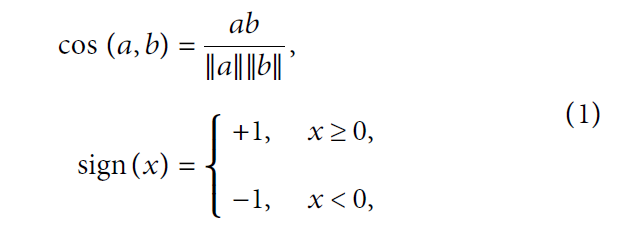
3.2 Model
图网络 将节点信息表示为一个图,通过聚合节点-节点间的关联,将 图拓扑 转换成 一个构造好的邻接矩阵,将 每个节点及其邻居的信息融合成一个新的节点。
随着注意力在NLP和CV中显示出优秀执行力,注意力机制被引入到图网络中,而不是简单的融合。注意力算法给每个节点一个注意力分数,然后融合不同的节点来获取信息。 关联度较低的特征词得分较低,关联度较高的特征词得分较高。在融合这些信息的过程中,增强了不同特征词在节点上的影响,可以提取出更好的语义信息。
由于我们的文本是一个1386维的向量表示,我们 将这些特征视为节点数据,每个文本都可以表示为 f i ∈ R 1386 f_i \in R^{1386} fi∈R1386。
为了获得将 输入特征 转换为 更高级特征 的强大表示能力,经过 可学习的加权矩阵 W ∈ R f × f W \in R^{f \times f} W∈Rf×f 变换后,对节点进行 自注意力。
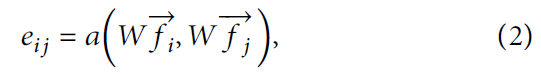
- a a a 为注意力计算因子
- e i j e_{ij} eij 表示节点 j j j 对节点 i i i 的重要性
我们计算节点 i i i 的每个相邻节点。为了使不同节点之间的系数易于比较,我们使用 s o f t m a x softmax softmax 函数对所有相邻节点进行归一化。

通过对所有的节点这样做,将 邻接矩阵的节点信息 转化为 包含每个相邻节点的注意力特征的 新的节点向量 ,这是最容易加权融合文本模态中缺乏语义信息的方法,从而使文本模态的模态表示更强大。
图注意力网络(graph attention network) 是 用注意力 将 与某一特征词相关联的特征词 与 其关联的特征词 进行融合。采用注意力机制的加权融合可以获得包含相邻节点信息的新的语义特征表示。
3.2.1 Deep Feature Extraction 深度特征提取
为了提取模态的高级语义表示的更丰富的信息,我们为不同的模态数据设计了不同的模态编码器。
由于图像模态比文本模态包含更丰富的语义信息,并且单流模型(例如:ViLT)无法跨越模态之间固有的模态差距,无法对每种模态进行最优特征提取,并且挖掘异构数据语义一致性信息的能力有限,因此我们采用 双流模型 提取不同模态数据信息的语义特征,并在整个训练阶段显示出出色的结果。
Image Feature Extraction
使用CLIP预训练模型作为我们模型中图像模态的特征提取器。
在使用CLIP的图像编码器(encode-image)的图像部分,我们将原始图像输入CLIP图像编码器(图3),提取后,我们得到一个1024维的高级语义向量,我们将其定义为
F
I
∈
R
m
×
1024
F_I \in R^{m \times 1024}
FI∈Rm×1024.

Text Feature Extraction
我们认为文本模态数据不包含像图像数据那样多的高级语义信息,但文本语义是上下文相关的。
我们将文本的特征视为图的节点,并使用 图注意网络(GAT) 从文本中提取聚合的语义信息。GAT将文本特征作为节点,将输入特征转换为更高级的特征以获得更强大的表达,引入注意力机制,对节点进行自注意力,并在节点之间确定注意力权重系数,通过对周围相邻节点进行加权求和,可以得到聚集所有周围节点的信息,使文本信息的连接更加真实(图4)。
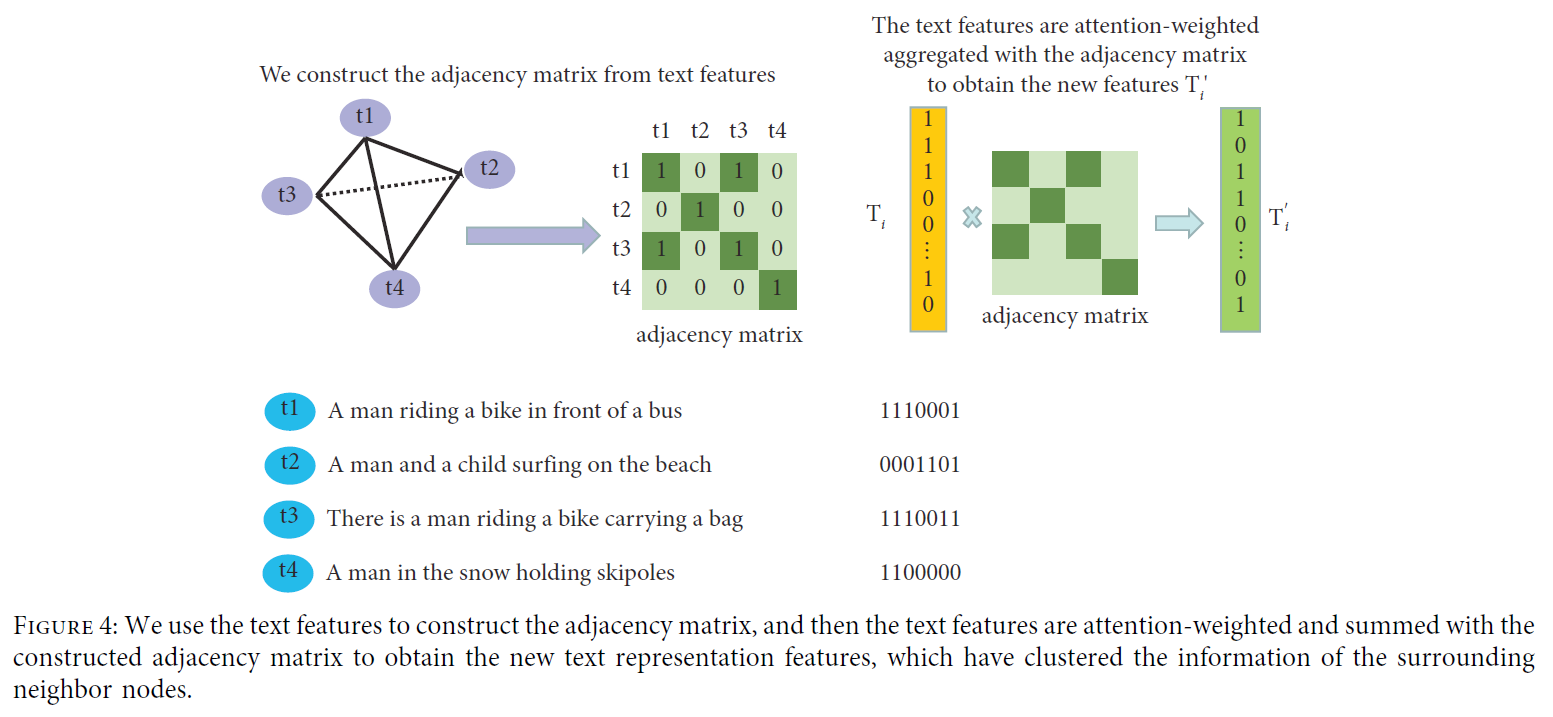
文本特征构造为邻接矩阵,邻接矩阵中的信息代表文本模态的联系,通过对特征进行加权可以更好地处理文本的语义表示。
原始文本信息表示为 F T ∈ R m × 1386 F_T \in R^{m \times 1386} FT∈Rm×1386。
为了简单起见,将特征提取器简化为 F F F。每个模态特征提取器的符号如下:
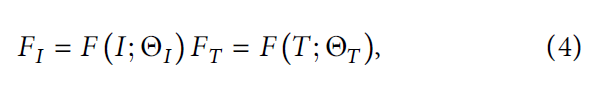
- I I I 和 T T T 表示原始图像和文本
- Θ I \Theta_I ΘI 和 Θ T \Theta_T ΘT 表示特征提取器的参数
为此,我们可以为每个模态提取语义丰富的高级表示特征,用于充分探索数据之间的语义关系,进一步指导模态对齐和哈希码学习。
3.2.2 Cycle Alignment 循环对齐
为了促进模态内语义特征对齐和保持跨模态数据语义交互,我们提出使用循环语义对齐方法。
语义相似的视觉-文本之间的距离在公共表示空间中被拉近,反之则在公共表示空间中被拉远。
为了进一步对齐文本和图像,我们使用了模态内和模态间损失度量。
我们 使用自编码器将高级语义信息压缩为低级语义表示,并将该底层语义特征重构回异构数据的特征。 将压缩高级语义表示的函数定义如下:
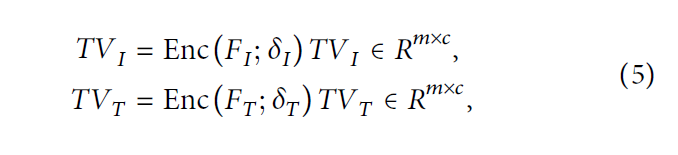
- F ∗ F_* F∗ 表示图像和文本的原始特征
- δ ∗ \delta_* δ∗ 被定义为每个模态通过 E n c ( ∗ ) Enc(*) Enc(∗) 下的参数
- ∗ ∈ { I , T } * \in \{I,T\} ∗∈{I,T}
由特征提取器提取的高级语义特征 由编码器编码和压缩,以获得具有强大表示能力和高度包含语义特征的 真值语义(true-value semantics),然后我们通过解码器将其重构回异构数据的表示,如下所示:
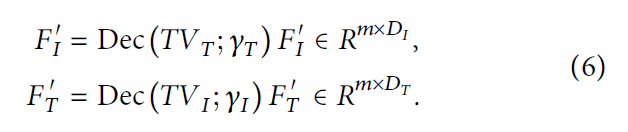
我们将图像(文本)的特征输入到解码器中,然后解码器将获得的语义信息映射到文本(图像)的特征空间,以实现模态之间的语义对齐。获得重构后的异构数据特征后,便于跨模态信息交互。
我们将原始图像特征与解码器重建的文本在语义上对齐。为了确保得到的压缩特征向量表示原始的高维特征表示,我们还将高维特征与编码特征对齐一次,实现了模态内语义对齐。
Intermodal 模态间
为了促进不同数据之间的信息交互,实现跨模态语义交互,我们使用一种模态的特征提取器获得的语义特征,经过自动编码器解码后,映射到另一种模态对应的语义空间。
- F T , I F_{T,I} FT,I 表示将文本特征映射到图像特征空间后的矢量表示
- F I , T F_{I,T} FI,T 表示将图像特征映射到文本特征空间后的矢量表示
我们构造了 跨模态语义特征矩阵 S F T , I S_{F_{T,I}} SFT,I 和 S F I , T S_{F_{I,T}} SFI,T。
通过最小化 跨模态语义损失 来实现不同模态类型的对齐,损失函数如下:
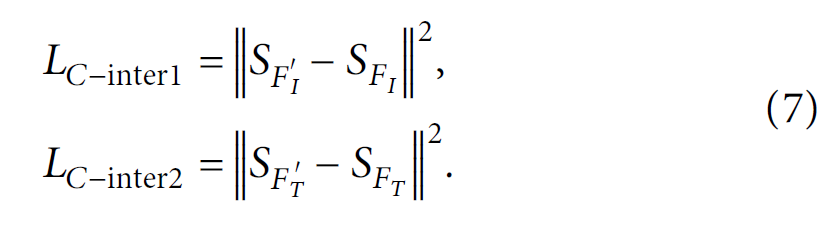
总的模态间损失:
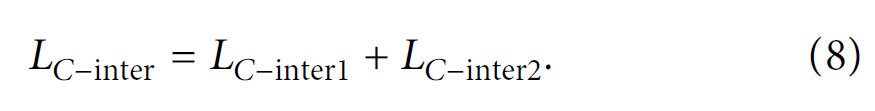
Intramodal 模态内
为了 确保模态内语义信息的代表性 并 减少语义特征损失,我们还在同一模态内执行模态内约束,并将 从原始图像中提取的特征 与 自动编码器编码的高级语义表示 对齐。
通过最小化 L C − i n t r a L_{C-intra} LC−intra 来确保高级语义信息的可表示性和完整性。
在自动编码器后将 图像模态特征矩阵 构造为 S F I , I S_{F_{I,I}} SFI,I 以获得隐藏状态的特征,用 S E n c − I S_{Enc-I} SEnc−I 表示。
文本特征也用 S F T , T S_{F_{T,T}} SFT,T 表示原始提取的特征,用 S E n c − T S_{Enc-T} SEnc−T 表示自动编码器解码的特征。
定义 模态内损失:
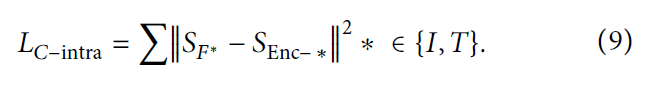
因此,我们构建了模态内对齐和模态间对齐方法,通过将 视觉编码器和文本编码器提取的高级语义表示 与 特征自动编码后压缩的语义特征 对齐,实现模态内语义对齐,保证少量高级特征即可还原高纬度模态数据。
通过 解码器的映射 将 异构数据 与 原始模态特征 对齐,实现跨模态数据的信息交互,并实现模态内和模态间对齐。
我们将 循环对齐的损失 定义如下:

Hash Encoding Learning
经过特征提取和循环语义对齐后,可以高质量地提取文本和视觉数据的语义信息并进行关联。在跨模态检索领域,我们的目标是通过根据设计的相似性度量,从数据集中的一个模态的查询点中提取语义上相关的数据样本,从而使语义上更相似的异构数据更加紧密相关。
通过将查询点转换为哈希码,可以更快地检索相应的模态信息,通过 AE(auto-encoder)映射,我们可以在训练阶段充分提取每个模态对应的高维度编码特征编码。
通过AE生成的特征向量对哈希码进行映射,由于特征提取和重构语义操作,使用真实值构造哈希编码,并通过 t a n h tanh tanh 函数生成哈希码。
我们通过将它们设计为 S x y B S_{xy}^B SxyB 来计算这个成对余弦相似矩阵,它用于表示生成的哈希矩阵。
特征生成哈希码的可视化如图5所示。
文本模态的哈希矩阵 记为 S T T B S_{TT}^B STTB,图像部分的哈希矩阵 记为 S I I B S_{II}^B SIIB.
对于矩阵元素,我们使用下面的 余弦相似度 来计算:
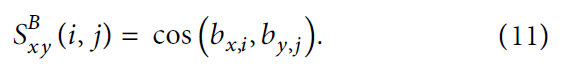
此外,受到启发,为了更充分地利用 图像文本对共同描述的语义信息,我们构建了 跨模态哈希码相似矩阵,其中共线性图像文本对 与 其他模态数据 相比具有最相似的标签或类别,对角线上的元素应该更接近1,从而更好地将其分解为图像文本对的哈希码,并最小化 共线性实例的损失 如下:
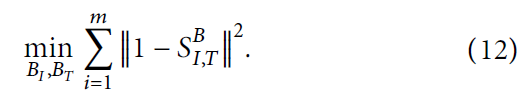
对于其他元素,我们使用 对角线相似性损失 来连接不同模式之间的连接,例如,同一对图像文本相似度应该独立于位置信息,只与特征信息相关,通过最小化对角线损失将图像文本对的语义桥接在一起,我们定义如下:
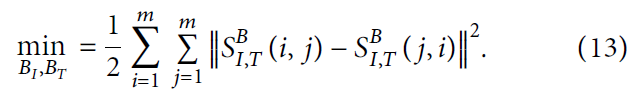
在
S
I
,
T
B
S_{I,T}^B
SI,TB 上总的损失如下:
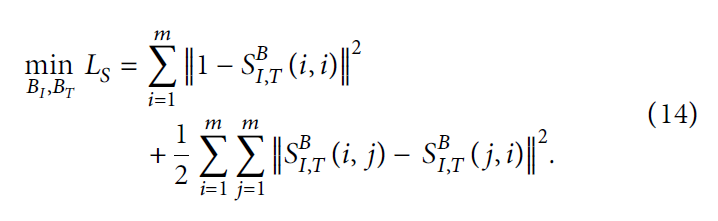
在自动编码器编码后,我们通过哈希函数将得到的特征映射到我们的哈希码上,并使用这些哈希码构造相似矩阵 S I , I B S_{I,I}^B SI,IB 和 S T , T B S_{T,T}^B ST,TB。
此外,我们引入了一个新的相似矩阵,通过映射哈希函数
S
I
,
T
B
S_{I,T}^B
SI,TB 得到,它是由 图像-文本标签 构造的。
在训练阶段,我们不使用标签进行引导,而是主要引入标签信息来计算哈希损失。
虽然哈希方法可以加快检索过程,但 将真值特征映射到哈希码仍然会导致一些信息缺失,从而导致检索的次优解决方案。在哈希编码学习中,我们 还需要关注不同模态数据之间的语义关系,而跨模态的相似信息是跨模态检索的核心任务。
在此基础上,我们将 单个模态中的特征与生成的哈希码对齐,以确保生成的哈希码更真实地表示原始数据信息。
k
k
k 是模态调整参数,它允许更大的灵活性来确保我们的语义相似性。
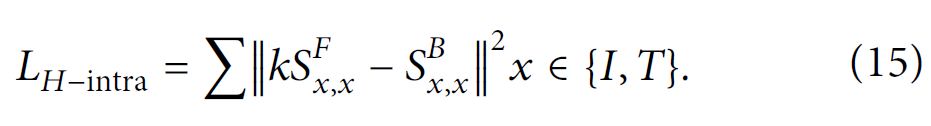
我们正在构建一个联合特征矩阵,将 文本特征矩阵 与 图像特征矩阵 以加权的方式整合,该联合特征矩阵仅由一个公共矩阵
S
I
,
T
F
S_{I,T}^F
SI,TF 表示。
α
\alpha
α 是一个超参数,可以用来对图像和文本的特征矩阵进行加权。
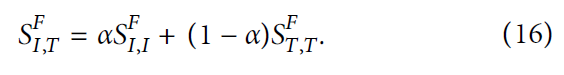
在优化我们的哈希码时基于矩阵对齐。
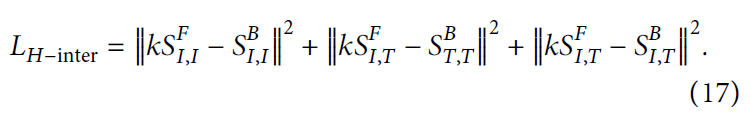
模态间总损失如下:
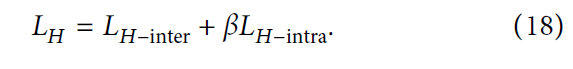
Optimisation 优化
我们将这些损失组合起来,构造出如下所示的总损失函数:

而且,在训练过程中,循环语义交互模块使用真值码,在训练过程中如果将真值码转换为哈希码会丢失一些信息,而真值特征更有利于模型的训练,多模态交互后生成的真值码更接近哈希码。
然而,生成的真值码并不是梯度可导的,因为它们是离散值。为了解决这个问题,受到 lim η → ∞ t a n h ( η x ) = s i g n ( x ) \lim_{\eta \to \infty} tanh(\eta x) = sign(x) limη→∞tanh(ηx)=sign(x) 的启发,我们通过 t a n h ( ⋅ ) tanh(\cdot) tanh(⋅) 将它们转换为二值码,并使用以下函数定义:
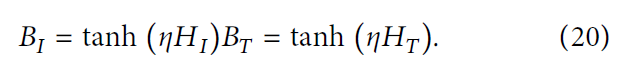
提出的CCAH算法如算法1所示:

4 Experiment
Datasets数据集
-
MIRFlickr-25K
- 包含从Flickr网站收集的25,000对图像-文本对。每个图像文本对都保存为一个实例。
- 对于文本模式,经过DJSRH后,对每个文本进行排序并标记出现特征,转化为BOW (bag-of-words)向量。
-
NUS-WIDE
- 由269,648对多模态数据组成,包含81个类别,每个多模态实例包含一个图像和相应的标签。
- 为了简单的处理,我们从最初的81个类别中选择了10个最常见的类别,并在所有对中选择了186,577个标记实例。
- 将每个实例的文本表示为500维词袋(BOW)向量。我们整理了最常见的1000个文本标签的索引向量。
-
MS COCO
- 最初是为图像理解任务收集的,包含123,287张图像。对于每个图像,给出了一个文本描述和一个91维语义标签。
- 我们的实验包含87,081张带有类别信息的图像,并使用一个2000维的词袋向量来表示文本信息。其中,随机选择5000个图像-文本对作为查询集,剩余的图像-文本对作为检索集。对于训练集,从检索集中随机抽取10,000对。
4.1 Implementation Details
- CLIP作为图像模态的特征提取器
- GAT作为文本模态的特征提取器
- 使用循环模态交互 实现模态内部和模态之间的语义对齐
- 使用一个模态的隐藏特征 来重构 另一个模态的特征,并仔细设置一些超参数 α 、 β 、 k \alpha、\beta、k α、β、k 来辅助学习。
在实验的基础上分析了这些参数的灵敏度,最后选择 α = 0.8 \alpha=0.8 α=0.8, β = 0.2 \beta=0.2 β=0.2, k = 1.5 k=1.5 k=1.5, b a t c h − s i z e = 16 batch-size=16 batch−size=16,图像和文本模式的学习率为 0.005 0.005 0.005,使用SGD优化策略,权重衰减设置为 5 × 1 0 − 4 5 \times 10^{-4} 5×10−4.
4.2 Baseline and Validation
使用三个跨模态通用数据集来验证我们的模型。
对于MIRFlickr-25K和NUS-WIDE,将2000个实例作为查询点,其余作为查询数据库。
由于MIRFlickr-25K和NUS-WIDE中的数据量非常大,我们从数据库集中的一个数据集中随机抽样进行训练。为了训练的公平性,我们在第一轮训练中从每个类中抽取一些实例,并在剩下的阶段随机抽样。
在MS COCO数据集中,我们取10000个实例作为检索集,剩余的实例组成数据库集。在我们的实验中,我们以 MAP 和 precision @ top-curves 作为模型的判断标准。
为了验证我们的CCAH模型,我们将其与一些常见的跨模态方法进行比较。
- Shallow cross-modal Hashing
- CVH
- IMH
- LCMH
- CMFH
- LSSH
- RFDH
- FSH
- STMH
- Deep cross-modal Hashing
- DBRC
- UDCMH
- DJSRH
- DSAH
- JDSH
- MGAH
- JIMRH
- HNH
- DUCH
CCAH与其他模型的对比结果如图6所示。
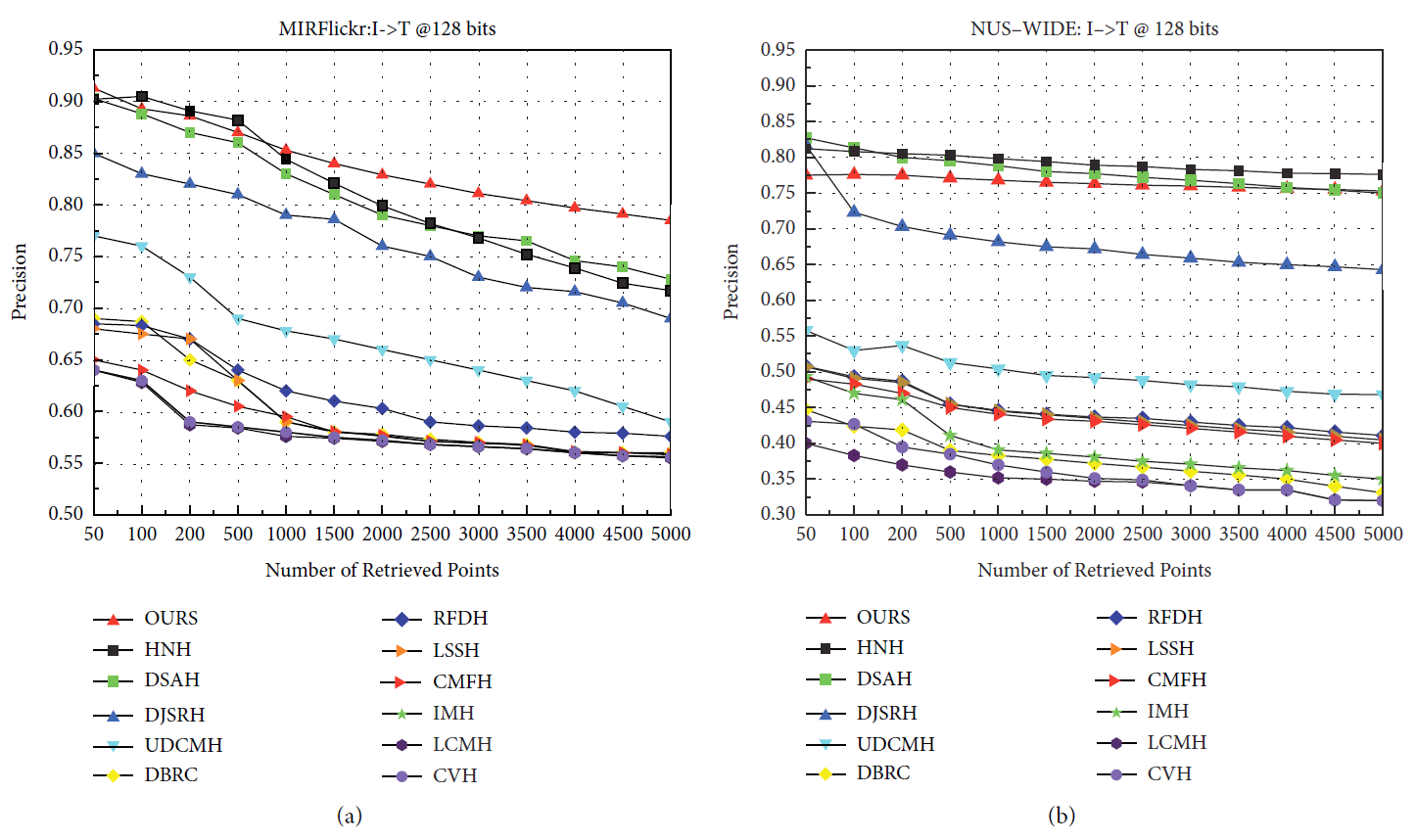
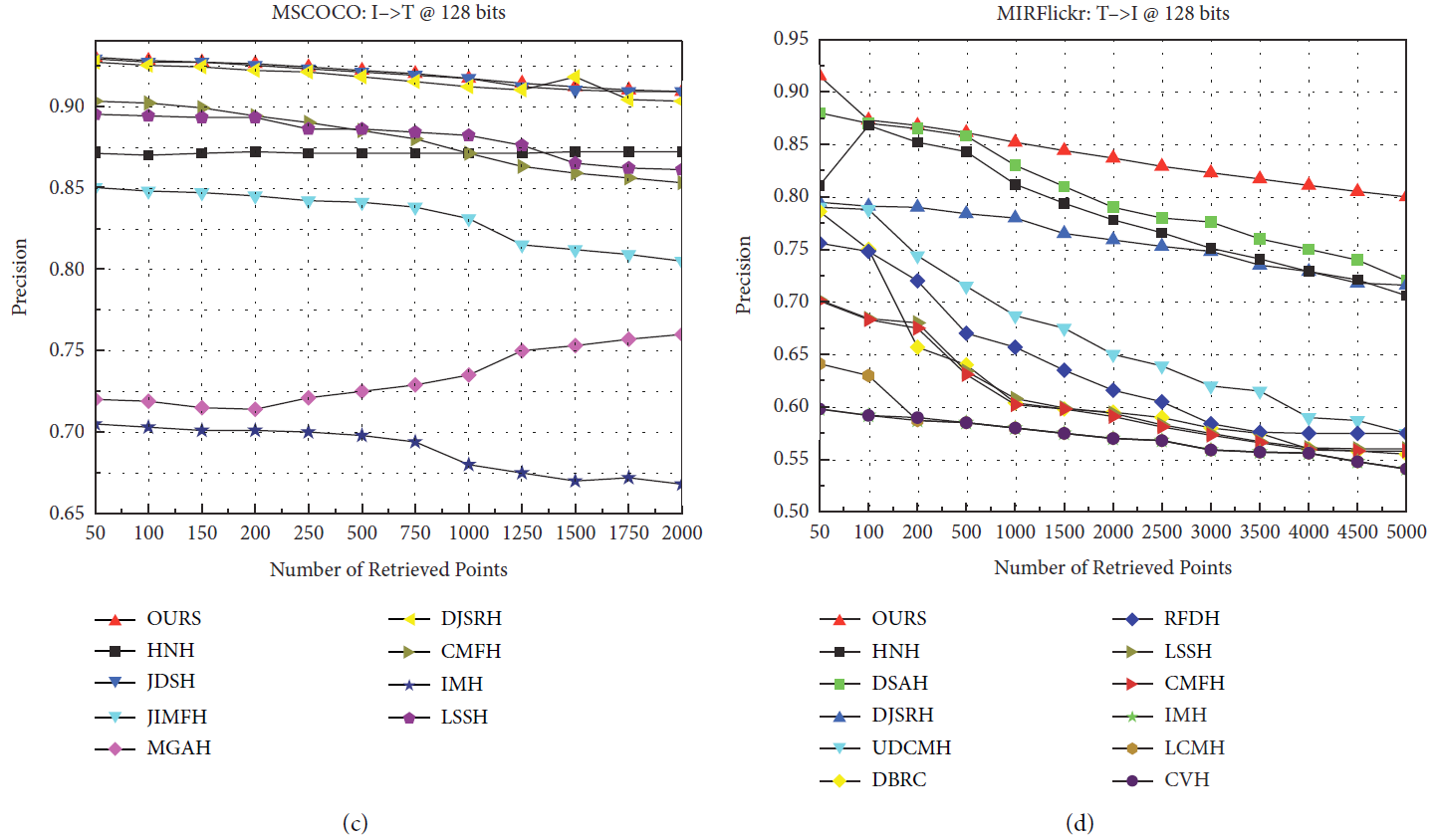
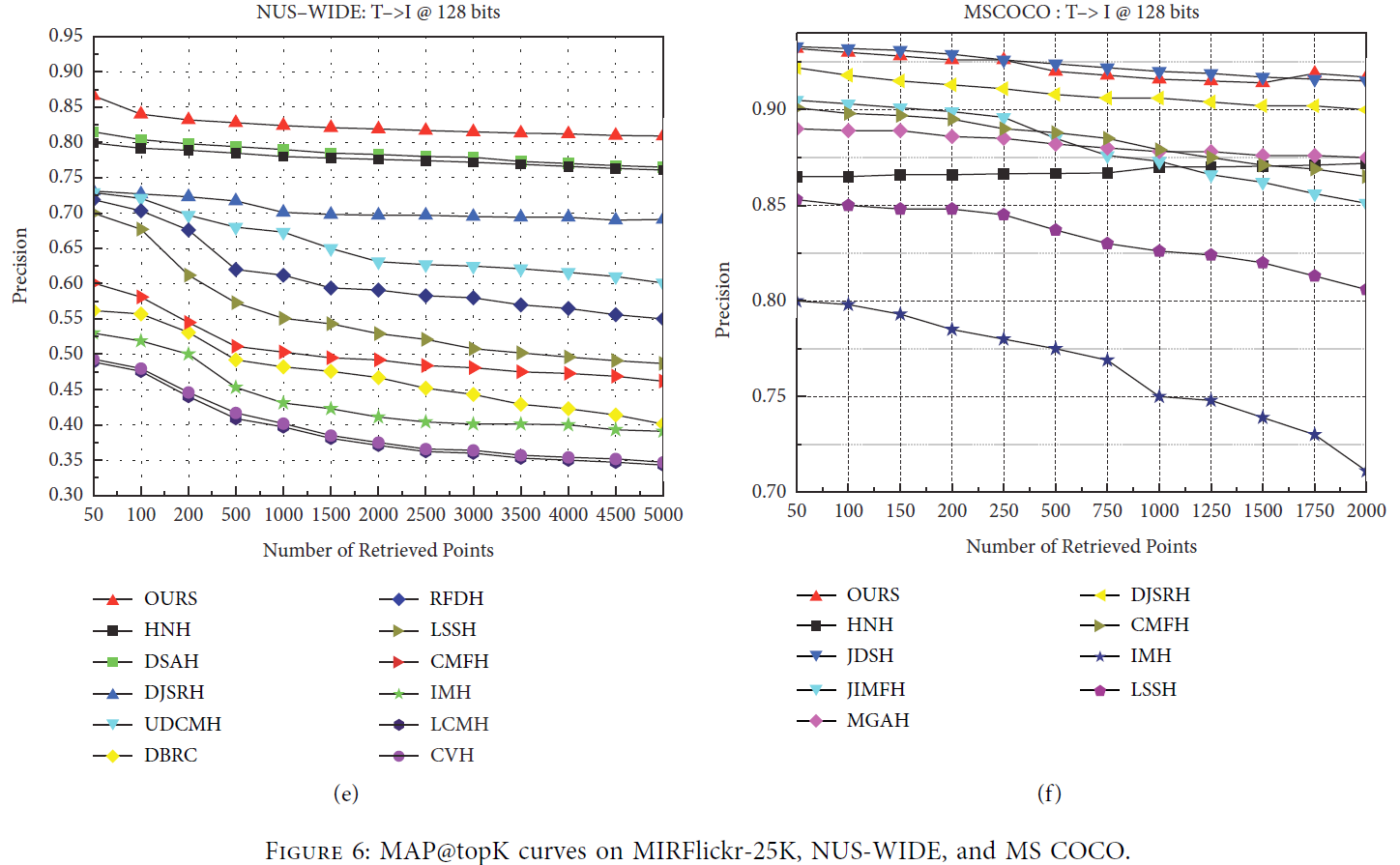
我们与之前在MIRFlickr-25K和NUS-WIDE数据集上的工作进行了比较,我们使用了MAP@50的基准。我们的CCAH模型在不同编码长度下的总检索精度优于以往的工作,如表1所示。
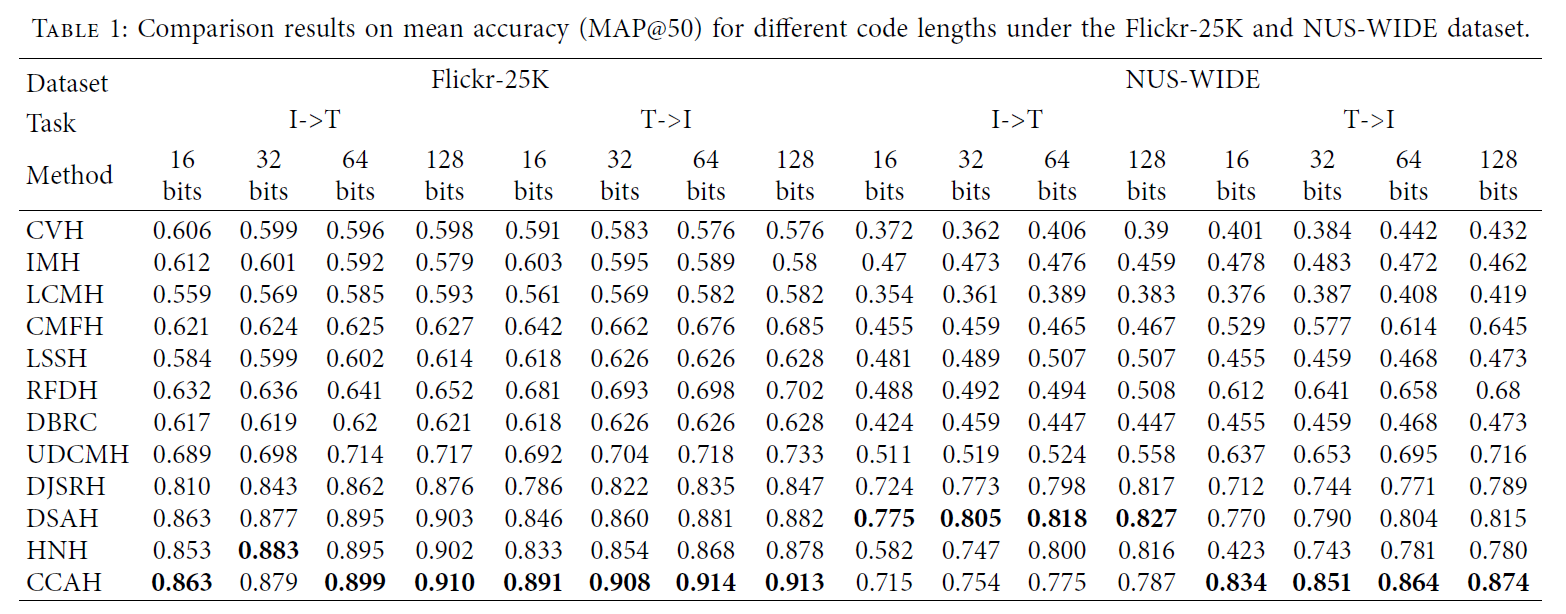
可以看到,我们的实验数据在两个广泛使用的数据集上显示出优异的结果,在MIRFlickr-25K上图像检索文本和文本检索图像都有显著的提高,而在NUS-WIDE数据集上图像检索文本的结果稍差,但在文本检索图像精度和整体检索精度上都有显著的提高。
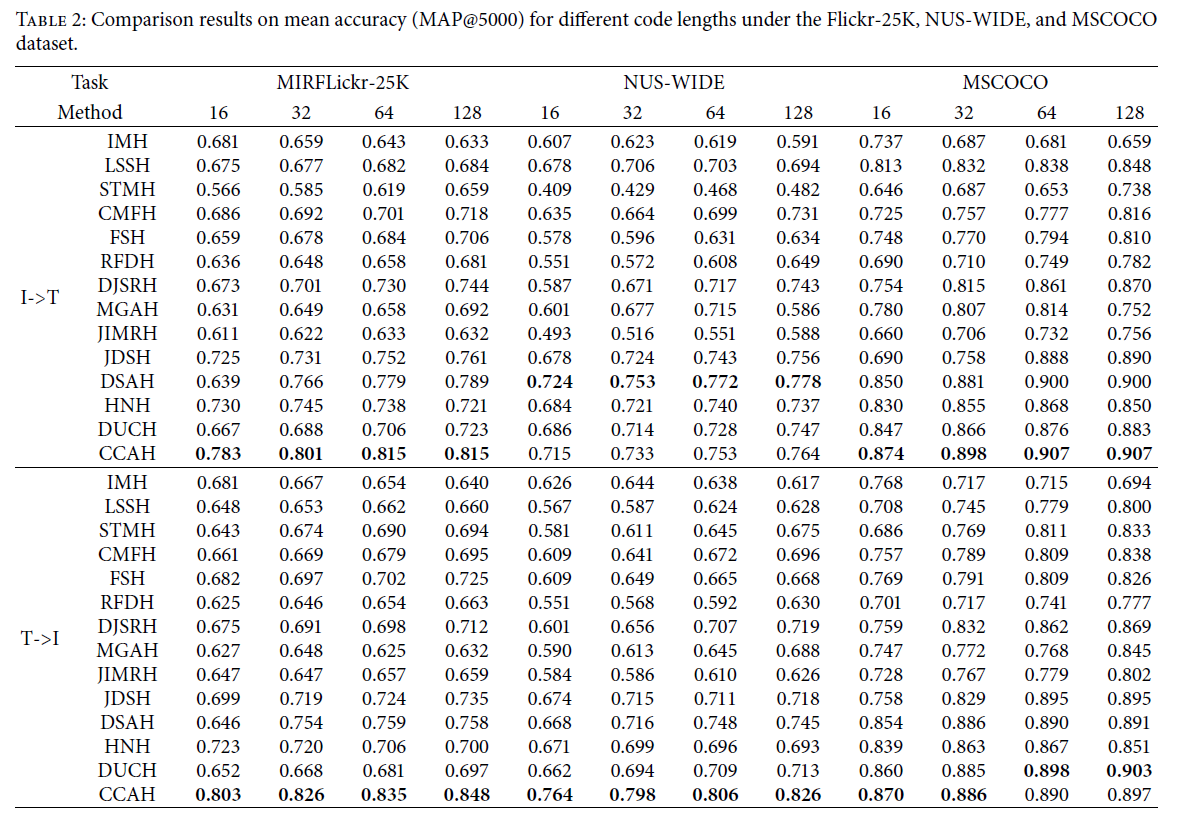
使用NUS-WIDE (tc-10)数据集,以最常见的10类作为数据集的组成。由于NUS-WIDE数据集比较大,在对样本点进行采样时,无法保证所取样本点的类别相等,并且在构造邻接矩阵时,数据更加稀疏,导致文本图像检索的效率降低。为了验证我们的理论,在DAEH的指导下,我们再次在MS COCO数据集上进行了测试,该数据集使用了81类。我们使用MAP@5000来评估我们的模型,结果如表2所示。
4.3 Ablation Experiment
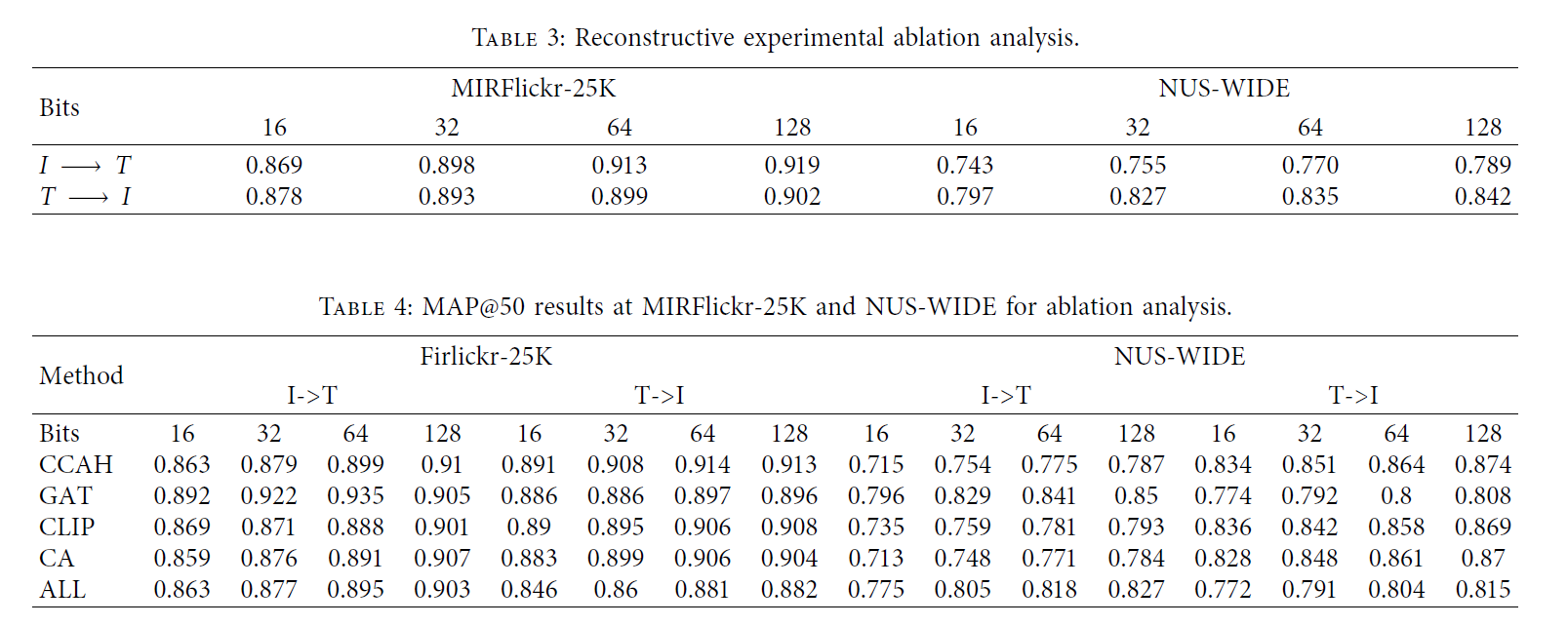
我们通过实验验证了不同模块对精度的影响,并在128位的MIRFlickr数据集上验证了模型。我们也做了其他的尝试。在编码和压缩阶段,我们采用双向模型,压缩向量既重建其原始特征,也重建异构数据的原始特征,而不仅仅是异构数据的特征。
我们在MIRFlickr和NUS-WIDE数据集上验证了这一点。结果表明,加入同质特征重构后,文本的图像检索精度相对提高1%,但图像的文本检索精度下降(表3)。
在表4中,我们对不同的模块进行了消融实验,以证明我们提出的方法的有效性。
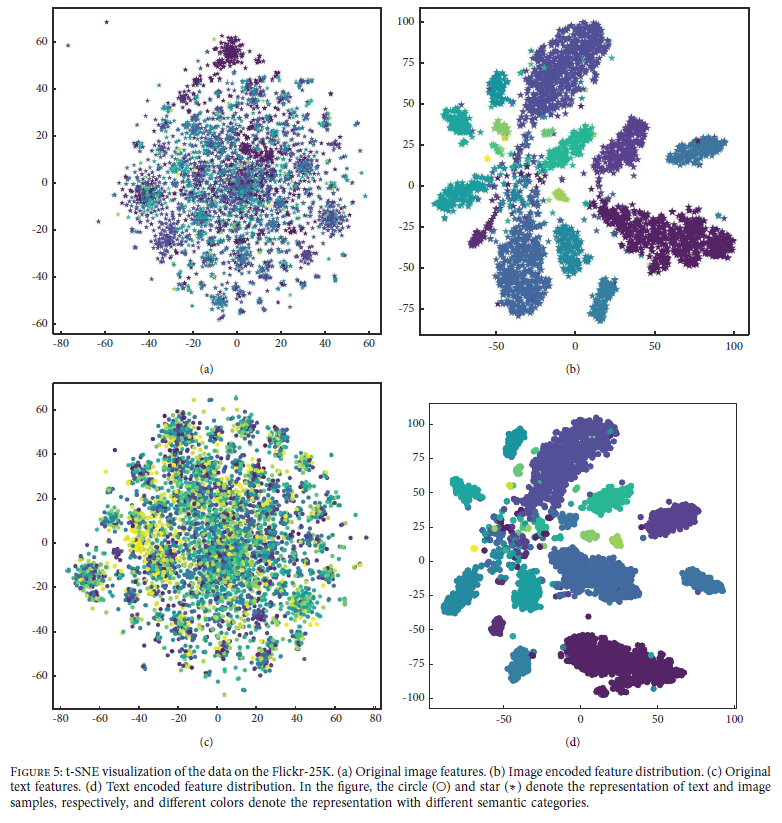
4.4 Visualization of the Learned Representation
为了可视化所提出的CCAH的有效性,我们使用t-SNE将学习到的图像、文本在Flickr-25K数据集上的表示可视化(图5)。
图像和文本的原始特征表示分别如图5(a)和5©所示。可以看出,这些模态的分布差异很大,很难通过原始表示来区分样本。
图5(b)和图5(d)分别给出了图像和文本的学习表征分布。从图中可以看出,所提出的CCAH方法有助于区分具有不同语义类的样本,并且一些聚类具有可区分的区间。
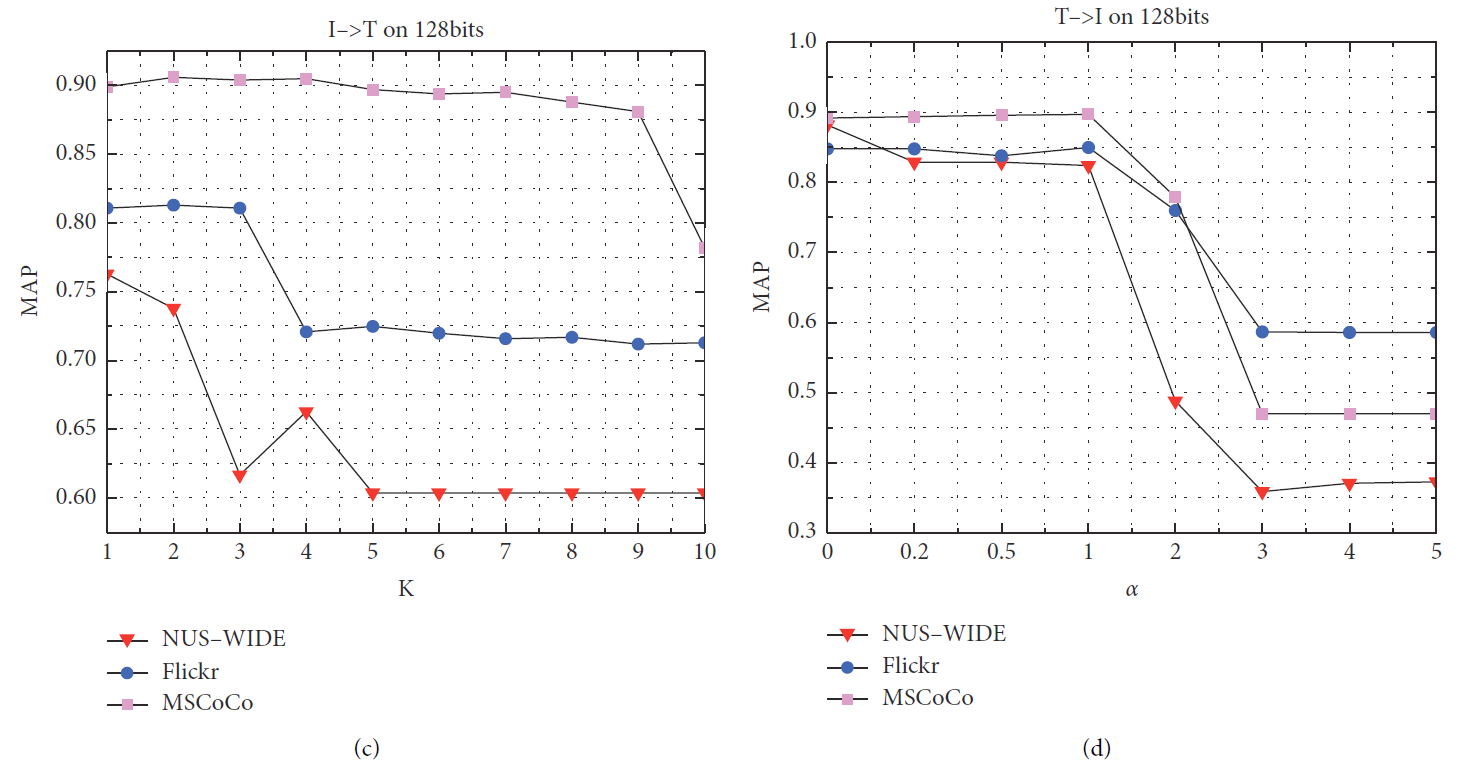
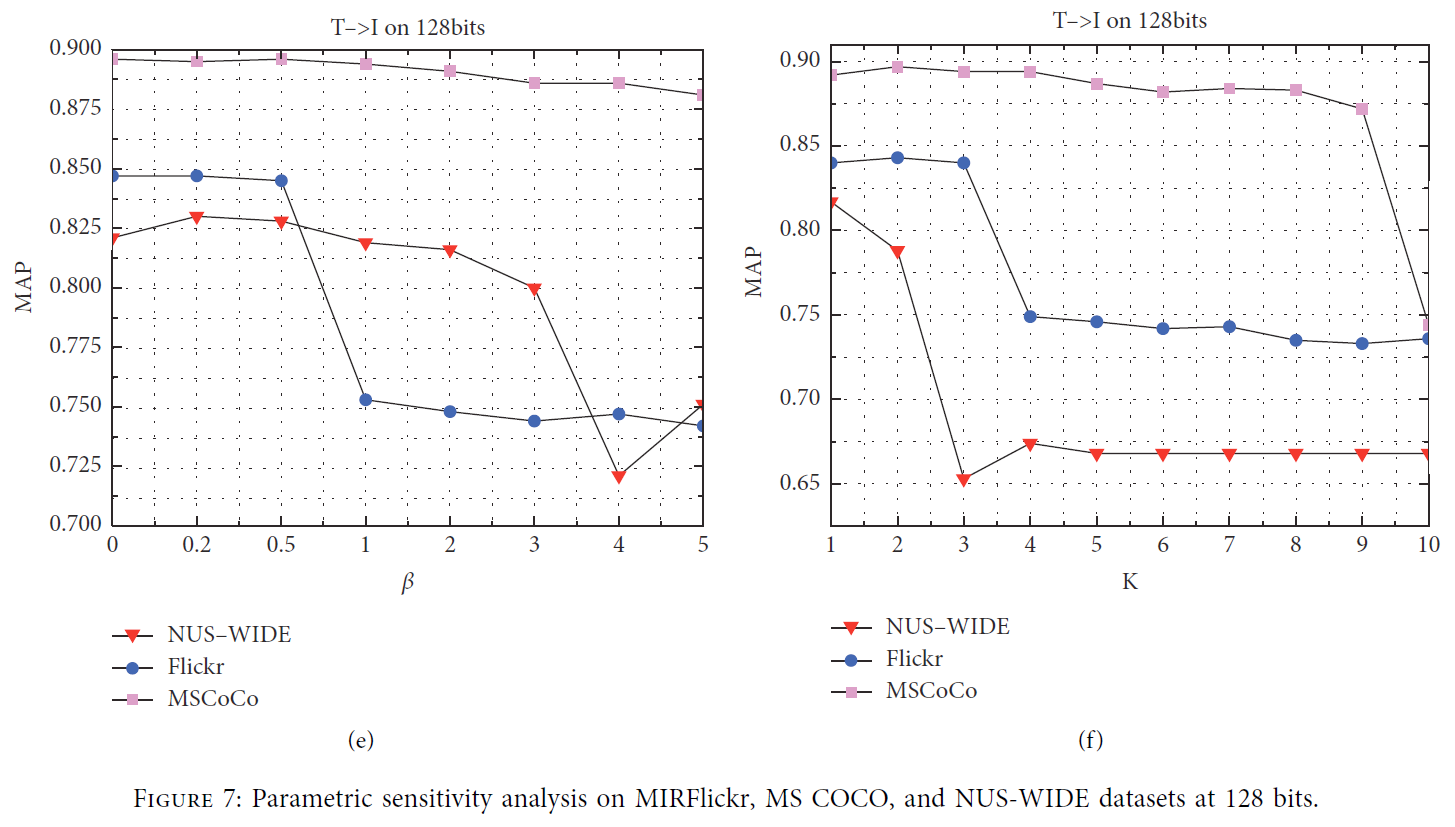
4.5 Hyperparameter Sensitivity
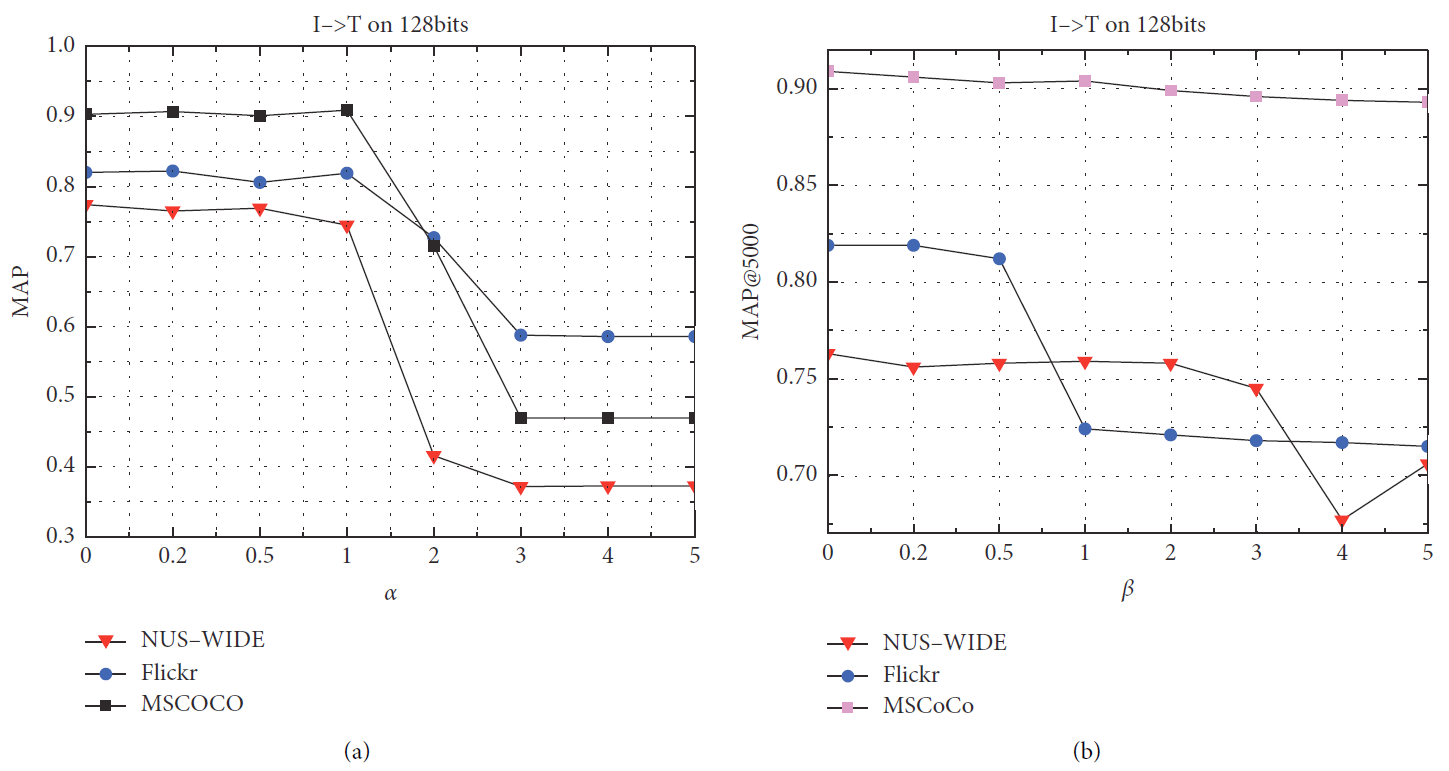
我们使用128位编码长度在三个数据集上进一步验证了参数 k 、 α 、 β k、\alpha、\beta k、α、β。
-
k
k
k 是我们将哈希矩阵与特征值优化成哈希码对齐的影响因子。
- 我们发现当 k = 1.5 k=1.5 k=1.5 时获得最佳结果。
-
α
\alpha
α 是跨模态对齐图像和文本的参数。
- 众所周知,图像模态比文本模态包含更丰富的语义特征,因此当对图像和文本进行加权时,图像的权重大于文本。
- 我们的模型在 α = 0.8 \alpha=0.8 α=0.8 时获得最佳结果。
- β \beta β 是用来平衡哈希编码和原始特征的参数,也可以增强模态内和模态间的系数。
超参数灵敏度可视化结果如图7所示。
4.6 Comparing Other Models
在上述3个跨模态公共数据集上,我们的结果与其他模型相比有了明显的改善,top-k的总检索精度在所有情况下都超过了以前的方法。
我们添加了GAT网络,该网络成功地利用图邻居构建邻接矩阵,与传统的词袋特征相比,可以提高语义特征差的文本模式的准确率。
利用CLIP提取图像特征,CLIP大规模预训练模型可以在更精细的层次上提取图像特征。
利用自编码器中各模态的隐藏状态向量,构造了一个循环语义比对模块来构造异构模态的语义特征,与使用二值编码构造特征相比,真实值信息更能代表模式特征,而使用二值编码丢失了大量有用信息。
我们在MS COCO数据集上对我们的模型进行验证,并用手动区域标记检测到的图像。
在文本检索图像中,用红色标记的文本为该文本的特征词(对应于图像标记区域);在图像检索文本中,标记为红色的文本表示检索结果与图像描述不太匹配(图8)。

5 Conclusion
本文提出了一种新的深度无监督跨模态哈希方法——基于CLIP的循环对齐哈希(CCAH),用于无监督视觉文本检索。
我们构建了一个循环对齐模块,允许更灵活地利用模态内部和模态之间的高级语义信息。
为了进一步弥合两种模态之间的差距,我们使用一种模态的隐藏状态向量来重建另一种模态的特征,使跨模态数据能够相互表征。
在三个基准数据集上的大量实验表明,CCAH在多模态数据检索任务中优于几种最先进的方法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









