







1.搭建 ogg for bigdata kafka
1.1. 创建 oracle测试表
-- t_test_03
create table t_test_03(
ID NUMBER(10) NOT NULL,
NAME VARCHAR2(100),
TYPE VARCHAR2(10)
);
COMMENT ON TABLE t_test_01 IS '测试表03';
COMMENT on COLUMN t_test_01.ID is '主键';
COMMENT on COLUMN t_test_01.NAME is '名称';
COMMENT on COLUMN t_test_01.TYPE is '类型';
-- t_test_04
create table t_test_04(
ID NUMBER(10) NOT NULL,
NAME VARCHAR2(100),
TYPE VARCHAR2(10)
);
COMMENT ON TABLE t_test_01 IS '测试表04';
COMMENT on COLUMN t_test_01.ID is '主键';
COMMENT on COLUMN t_test_01.NAME is '名称';
COMMENT on COLUMN t_test_01.TYPE is '类型';
1.2 ogg基本操作命令介绍
# 查看所有进程
info all
# 查看进程状态
info <进程名称>
# 查看进程状态详细信息
info <进程名称>,detail
# 查看进程抽数状态
stats <进程名称>
# 启动进程
start <进程名称>
# 关闭进程
stop <进程名称>
# 查看当前进程的报错信息
view report <进程名称>
# 新增、编辑进程文件
edit params <进程名称>
# 查看进程文件内容
view params <进程名称>
# 删除进程
delete <进程名称>
1.3 添加全字段附加日志
# 连接数据库
dblogin USERID admin@orcl PASSWORD "admin"
-- 添加全字段附加日志
add trandata test.t_test03 allcols
add trandata test.t_test04 allcols
-- 查看
info trandata test.t_test04 allcols
info trandata test.t_test04 allcols
1.4 kafka 创建主题
# T_TEST03 表
kafka-topics --bootstrap-server kafkal:9092 --creare --topic TY_TEST_T_TEST03_OGG_SR replaction-factor 3 --partitions 3 --command-config Config.properties
# T_TEST04 表
kafka-topics --bootstrap-server kafkal:9092 --creare --topic TY_TEST_T_TEST04_OGG_SR replaction-factor 3 --partitions 3 --command-config Config.properties
1.5 源端ogg进程配置
1.5.1 创建抽取进程文件
# 执行命令创建文件:
edit params EXT_HY1
# 添加以下内容:
EXTRACT EXT_HY1
SETENV (NLS_LONG="AMERICAN_AMERICA.ZHS16GBK")
USERID <用户名>@,<实例名>,PASSWORD "<密码>"
DISCARDFILE ./dirrpt/EXT HY1.dSC,APPEND,MEGABYTES 500
TEANLOGOPTIONS dblogreader
DBOPTIONS ALLOWUNUSEDCOLUHN
WARNLONGTRANS 2h,CHECKINTERVAL 300S
FETCHOPTIONS NOUSESNAPSHOT
LOGALLSUPCOLS
UPDATERECORDFORMAT FULL
EXTTRAIL ./dirdat/tz
TABLE TEST.T_TEST03,keycols(ID);
TABLE TEST.T_TEST04,kevcols(ID);
1.5.2 创建投递进程文件
# 执行命令创建文件:
edit params PM_HY1
# 添加以下内容:
EXTRACT PM_HY1
PASSTHRU
RMTHOST <目标端ip>,MGRPORT <目标端端口>
RMTTRAIL ./dirdat/tz
DYNAMICRESOLUTION
GETTRUNCATES
TABLE TEST.T TESTO3;
TABLE TEST.T TESTO4;
1.5.3 抽取、投递添加进程
# 抽取添加进程
ADD EXTRACT EXT_HY1,TRANLOG,BEGIN NOW -- 添加进程
ADD EXTTRAIL ./dirdat/tz,EXTRACT EXT_HY1,MEGABYTES 500 -- 绑定trai1文件
# 投递添加进程
ADD EXTRACT PM_HY,EXTTRAILSOURCE ./dirdat/tz
ADD RMTTRAIL ./dirdat/tz,EXTRACT PH_HY1, MEGABYTES 500
# 如果不从当前开始 可以设置读取的位置设置一个`seq序列` 和 `偏移值` 的位置开始读取
alter replicat SR_HY1,extseqno *,extrba *
1.6 目标端ogg进程配置
1.6.1 复制进程
# 执行命令创建文件:
edit params SR_HY1
# 添加以下内容:
REPLICAT SR_HY1
TARGETDB LIBFIlE libggjava.so SET property=dirprm/sr_test.props
REPLACEBADCHAR SKIP
GETUPDATEBEFORES
DISCARDFILE ./dirrpt/SR_HY1.dsc, append
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 2000
MAP test.T TEST03 TARGET test.T TEST03:
MAP test.T TEST04 TARGET test.T TEST04;
1.6.2 ogg2kafka 配置文件(如上1.6.1中的:sr_test.props)
# ogg配置文件 我是放在 dirprm 目录中
gg.handlerlist=kafkaconnect
# The handler properties
gg.handler.kafkaconnect.type=kafkaconnect
gg.handler.kafkaconnect.kafkaProducerConfigFile=custom_kafka_producer_sr.properties
gg.handler.kafkaconnect.mode=op
# The following selects the topic name based on the fully qualified table name
gg.handler.kafkaconnect.topicMappingTemplate=TY_test_${tableName}_0GG_SR
# gg.handler.kafkaconnect.topicMappingTemplate=${tableName}
# The following selects the message key using the concatenated primary keys
gg.handler.kafkaconnect.keyMappingTemplate=${primaryKeys}
gg.handler.kafkaconnect.MetaHeaderTemplate=${alltokens}
gg.handler.kafkaconnect.includelsMissingFields=true
# The formatter properties
gg.handler.kafkaconnect.messageFormatting=op
gg.handler.kafkaconnect.insertOpKey=I
gg.handler.kafkaconnect.updateOpKey=U
gg.handler.kafkaconnect.deleteOpKey=D
gg.handler.kafkaconnect.truncateOpKey=T
gg.handler.kafkaconnect.treatAllColumnsAsStrings=false
gg.handler.kafkaconnect.iso8601Format=false
gg.handler.kafkaconnect.pkUpdateHandling=update
gg.handler.kafkaconnect.includeTableName=true
gg.handler.kafkaconnect.includeOpType=true
gg.handler.kafkaconnect.includeOpTimestamp=true
gg.handler.kafkaconnect.includeCurrentTimestamp=true
gg.handler.kafkaconnect.includePosition=true
gg.handler.kafkaconnect.includePrimaryKeys=false
gg.handler.kafkaconnect.includeTokens=false
goldengate.userexit.writers=javawriter
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
gg.log=log4j
gg.log.level=INFO
gg.report.time=30sec
gg.classpath=dirprm/:/opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/1ib/kafka/libs/*:/goldengate_test/confluent-6.0.1/share/iava/kafka-serde-tools/*:/goldengate_test/confluent-6.0.1/share/java/kafka/*:/goldengate_test/confluent-6.0.1/share/java/confluent-comon/*
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar
-Djava.security.krb5.conf=/etc/krb5.conf
-Diava.security.auth.login.config=/goldengate_test/ogg4bd19/dirprm/kafka_client_jaas.conf
1.6.3 kafka配置文件(如上1.6.2中custom_kafka_producer_sr.properties)
# kafka 配置文件 我是放在 dirprm 目录中
bootstrap.servers=ip1:9092,ip2:9092,ip3:9092
client.id=0GG
acks=1
#AVRO转换器设置
key.converter=io.confluent.connect.avro.AvroConverter
value.converter=io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url=http://kafkal:8081,http://kafka2:8081,http://kafka3:8081
value.converter.schema.registry.url=http://kafka1:8081,http://kafka2:8081,http://kafka3:8081
converter.type=key
converter.type=value
converter.type=header
#性能调整
buffer.memory=33554432
batch.size=16384
Linger.ms=0
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
security.protocol=SASL_PLAINTEXT
sasl.mechanism=GSSAPI
sasl.kerberos.service.name=kafka
schema.registry.url=http://kafkal:8081,http://kafka2:8081,http://kafka3:8081
#SR鉴权
key.converter.basic.auth.credentials.source=USER_INFO
kev.converter.basic.auth.user.info=username:password
value.converter.basic.auth.credentials.source=USER_INFO
value.converter.basic.auth.user.info=username:password
1.6.4 复制进程添加
# 复制添加进程 begin now 从默认位置读取
add replicat SR_HY1 EXTTRAIL./dirdat/tz,NODBCHECKPOINT,begin now
# 如果不从当前开始 可以设置读取的位置设置一个`seq序列` 和 `偏移值` 的位置开始读取
alter replicat SR_HY1,extseqno *,extrba *
1.7 启动
1.7.1 源端启动
# 源端进入到ogg目录下
./ggsci
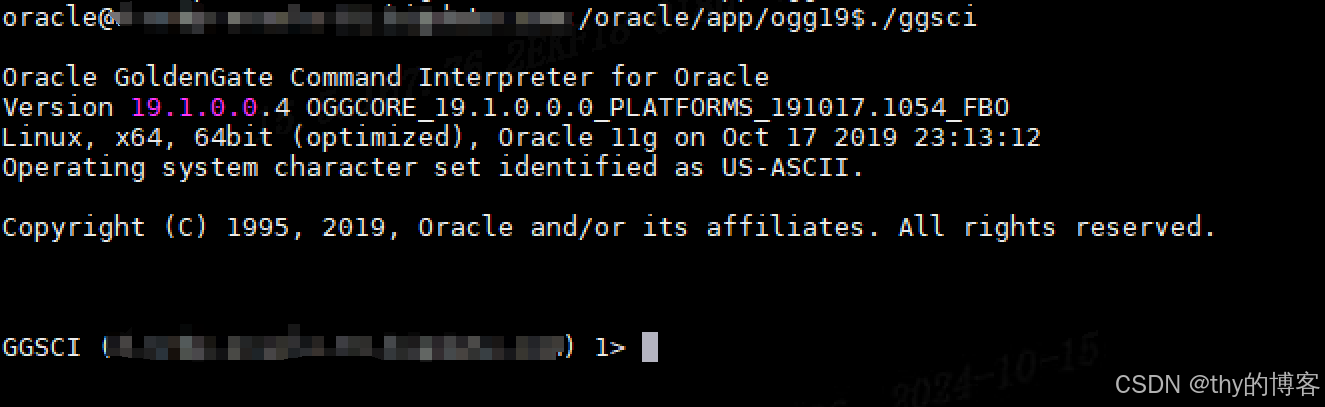
# 启动抽取进程
start EXT_HY1
# 启动投递进程
start PM_HY1
# 查看进程状态
info EXT_HY1
info PM_HY1
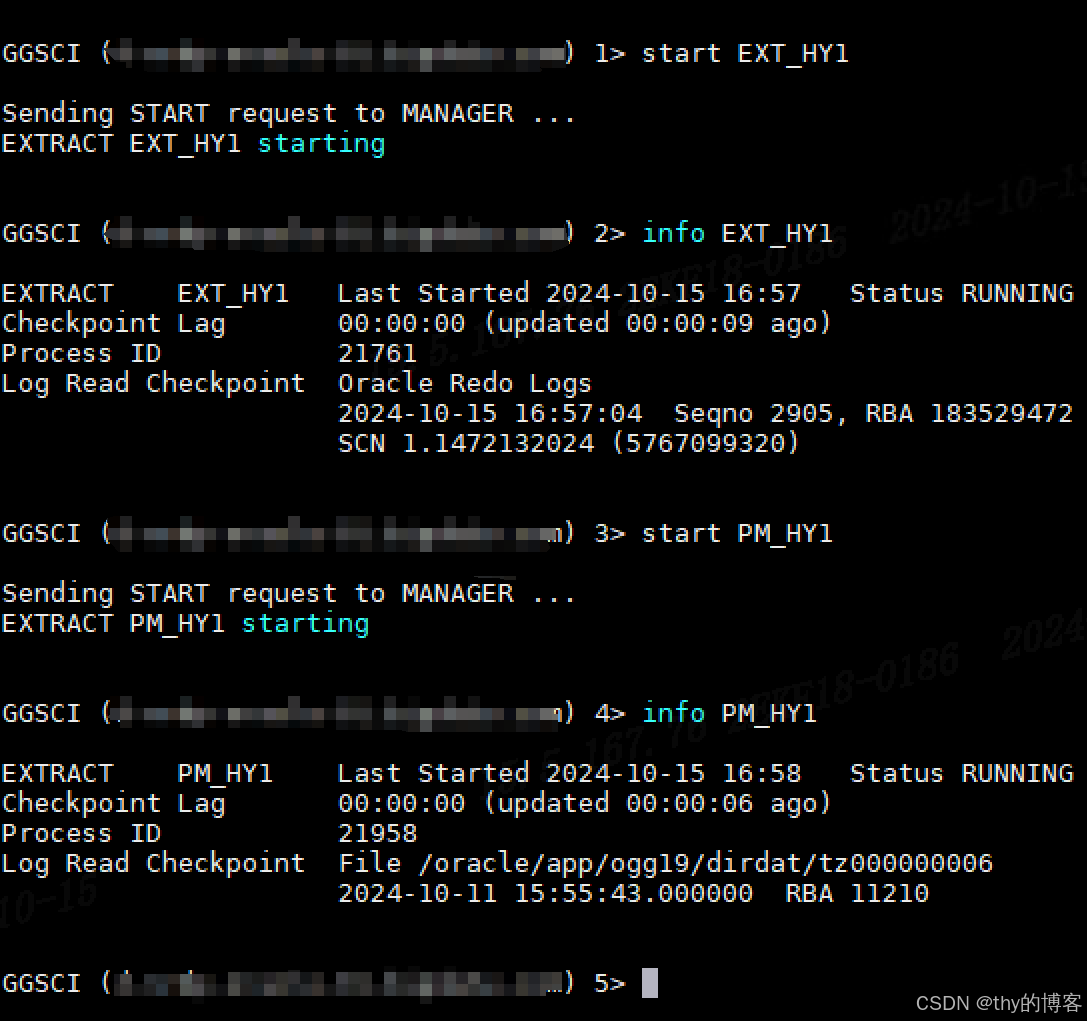
1.7.2 目标端启动
# 目标端进入到ogg目录下
./ggsci
# 启动复制进程
start SR_HY1
# 查看进程状态
info SR_HY1
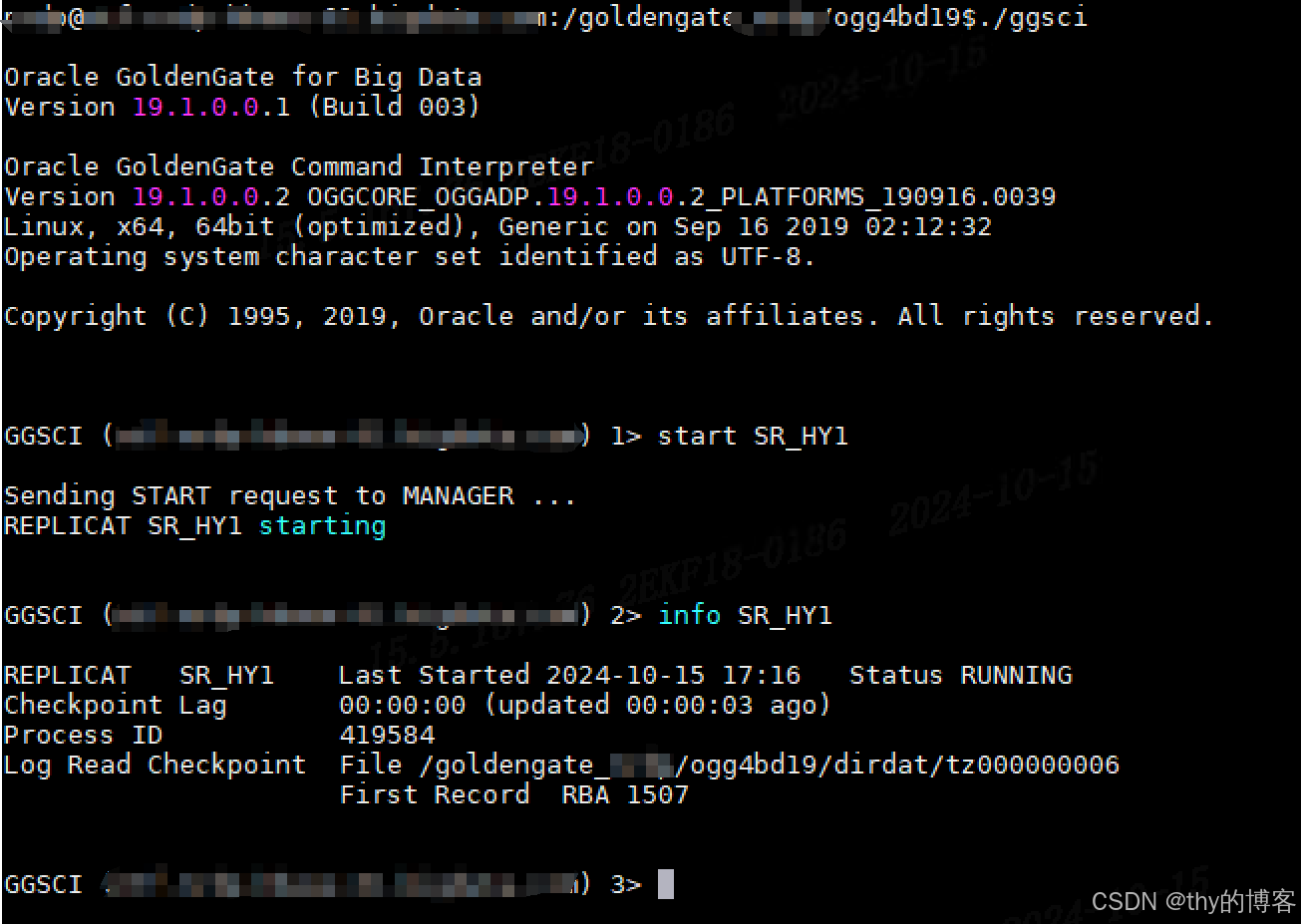
1.7.3 模拟9条数据入库利用java模拟消费者消费数据成功
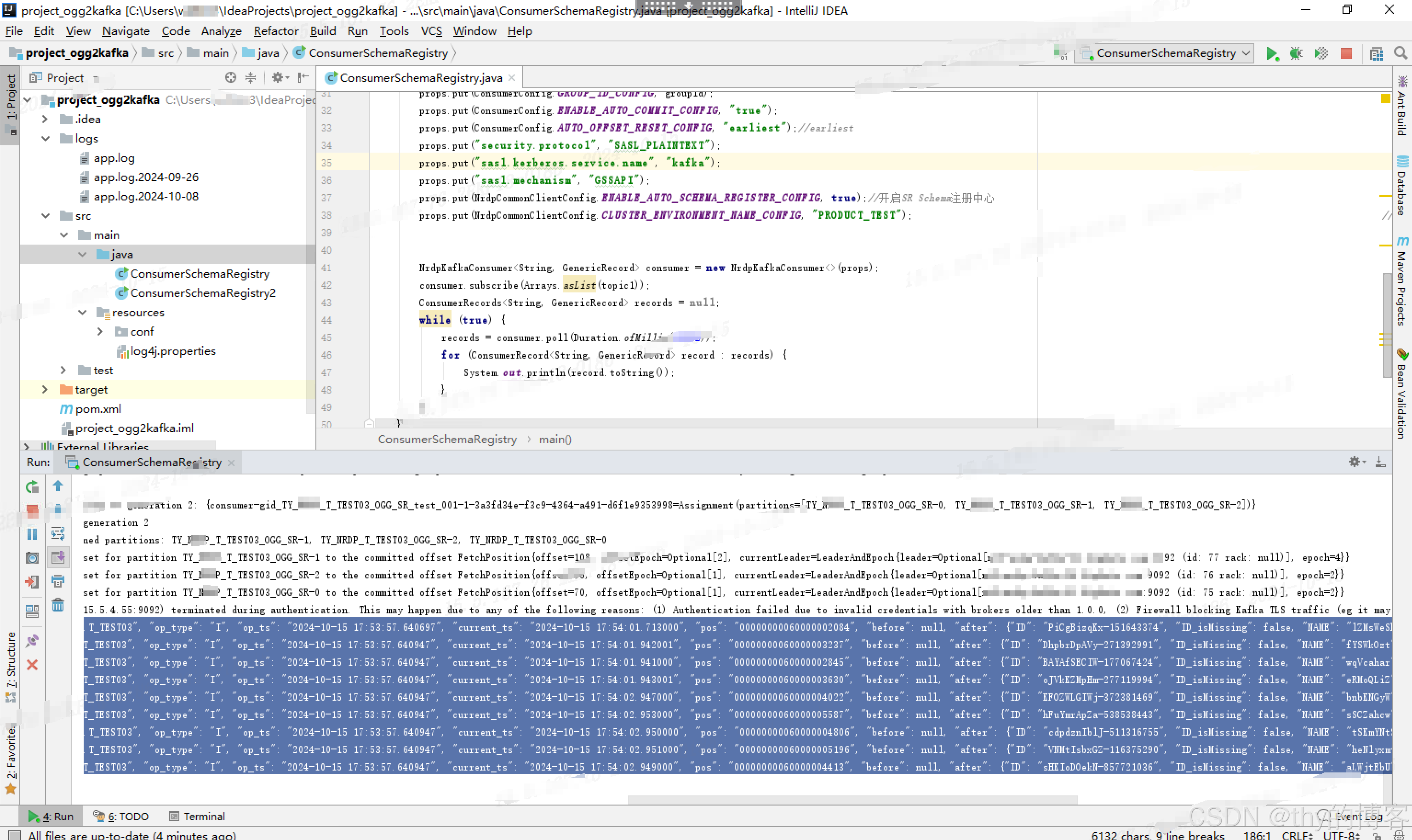
1.7.4 查看进程状态信息(可以看到9条 insert 数据记录)
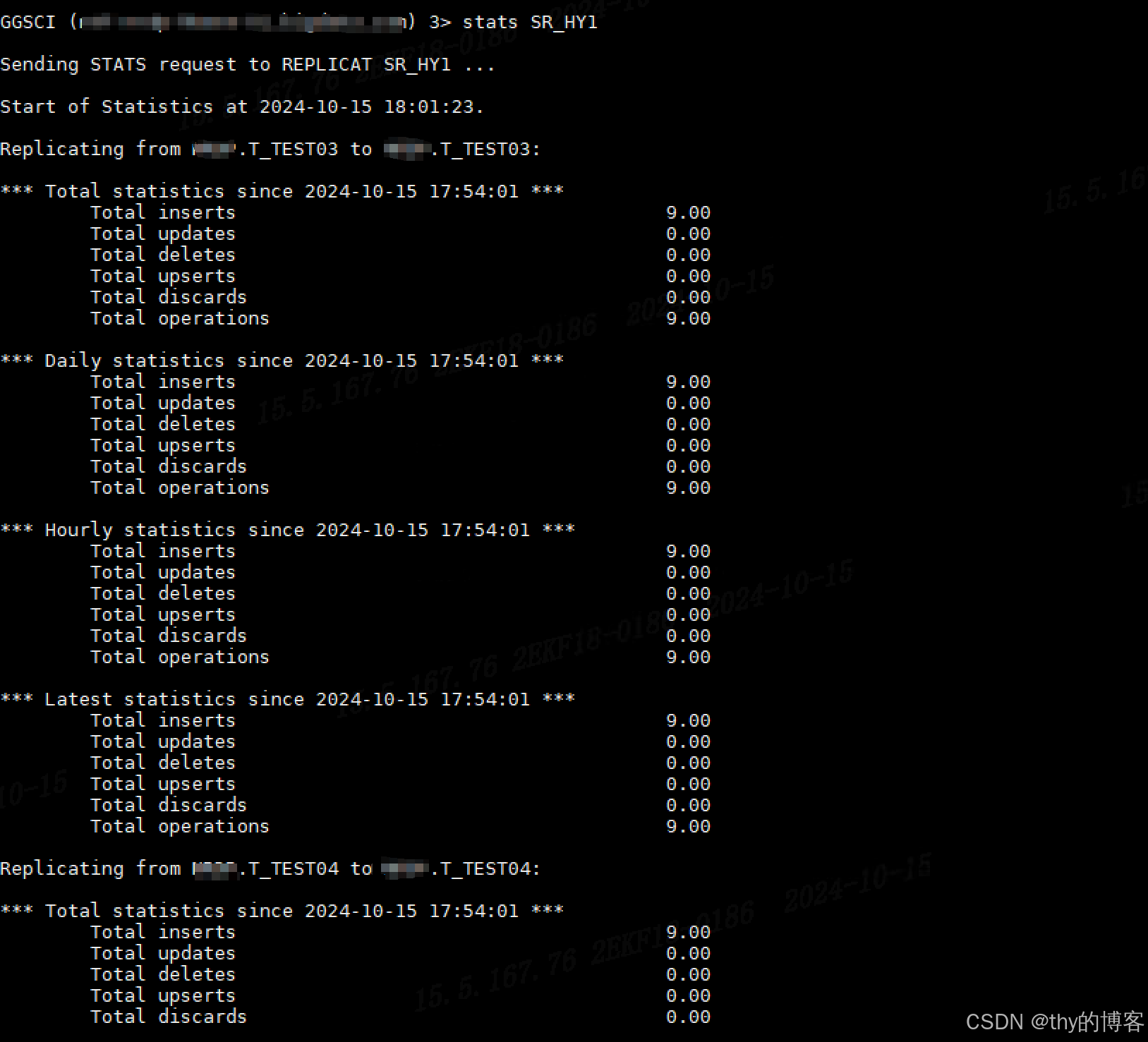


















 2399
2399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











