







基础篇
内连接 , 外连接 , 交叉连接 *2
MySQL 中的连接是通过两个或多个表之间的列进行关联,从而获取相关联的数据。连接分为内连接、外连接、交叉连接。
①、内连接(inner join):返回两个表中连接字段匹配的行。如果一个表中的行在另一个表中没有匹配的行,则这些行不会出现在查询结果中。
②、外连接(outer join):不仅返回两个表中匹配的行,还返回左表、右表或两者中未匹配的行。
③、交叉连接(cross join):返回第一个表中的每一行与第二个表中的每一行的组合,这种类型的连接通常用于生成笛卡尔积。
左连接,右连接 2
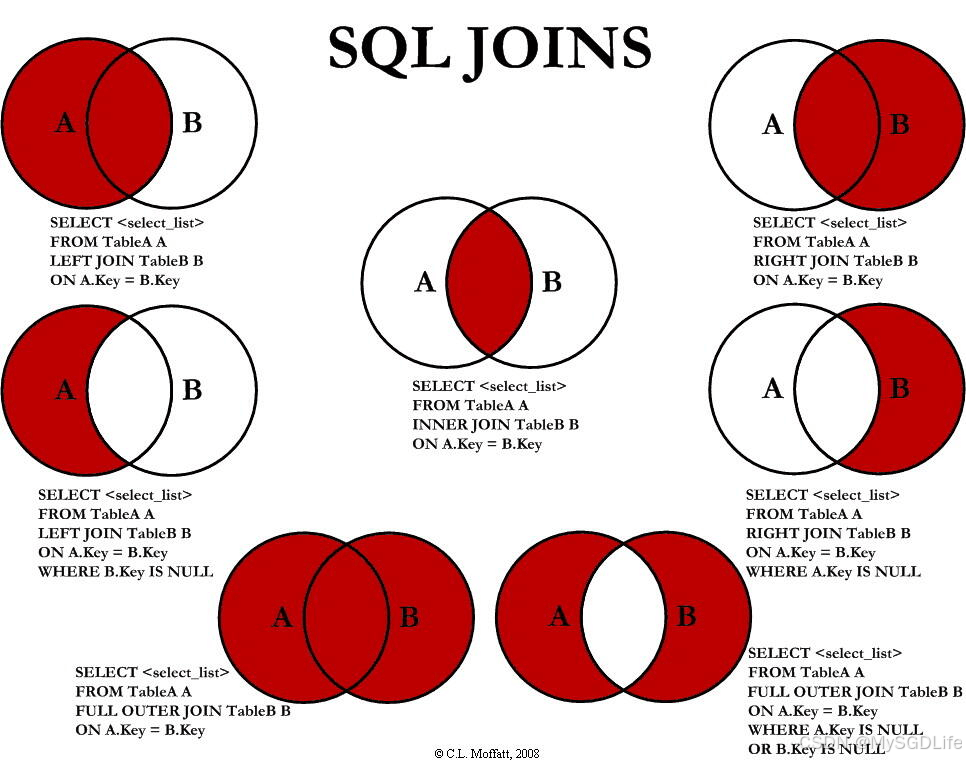
①、inner join 内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集。
只有当两个表中都有匹配的记录时,这些记录才会出现在查询结果中。如果某一方没有匹配的记录,则该记录不会出现在结果集中。
内联可以用来找出两个表中共同的记录,相当于两个数据集的交集。
②、left join 返回左表(FROM 子句中指定的表)的所有记录,以及右表中匹配记录的记录。如果右表中没有匹配的记录,则结果中右表的部分会以 NULL 填充。
③、right join 刚好与左联相反,返回右表(FROM 子句中指定的表)的所有记录,以及左表中匹配记录的记录。如果左表中没有匹配的记录,则结果中左表的部分会以 NULL 填充。
三大范式 2
①、第一范式:确保表的每一列都是不可分割的基本数据单元
②、第二范式:要求表中的每一列都和主键直接相关,而不能只与主键的某一部分相关。
③、第三范式:非主键列应该只依赖于主键列,不依赖于其他非主键列。
MySQL 的存储引擎有哪些?为什么常用InnoDB? *
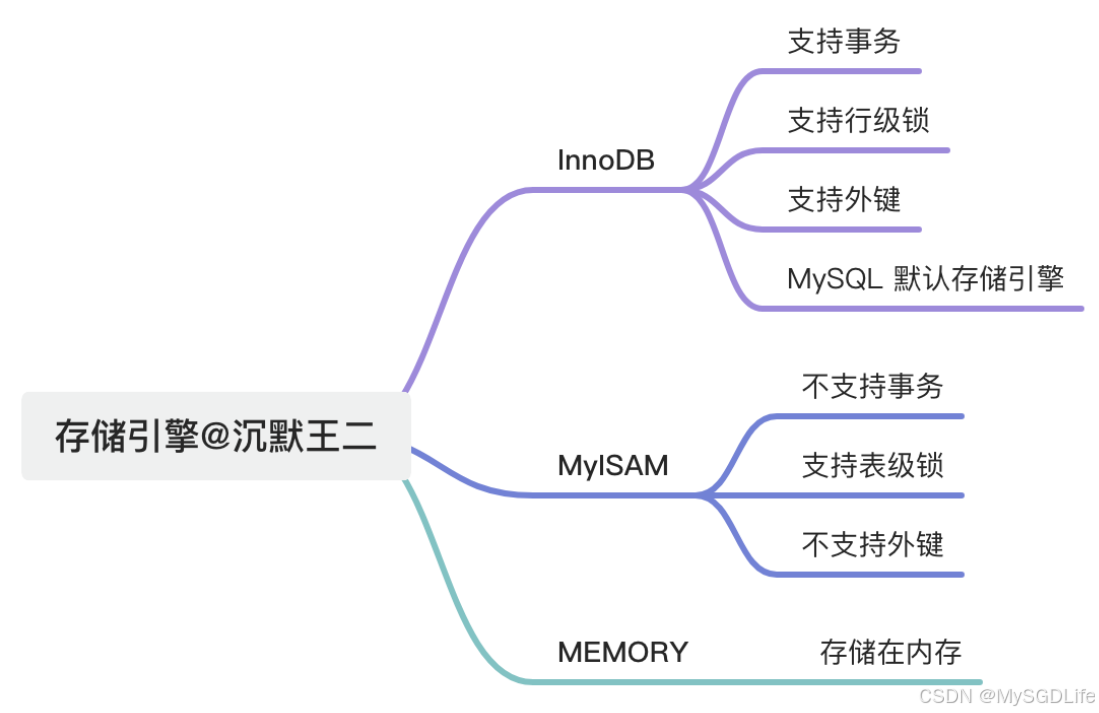
MySQL的存储引擎常用的主要有3个:
● InnoDB存储引擎: 支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有 很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit) 和回滚(rollback)。
● MyISAM存储引擎:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比较低,也可以使用。如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率。
● MEMORY存储引擎: 所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引|擎作为临时表,存放查询的中间结果
常用InnoDB的原因是支持事务,且最小锁的粒度是行级锁。
如何选择引擎?
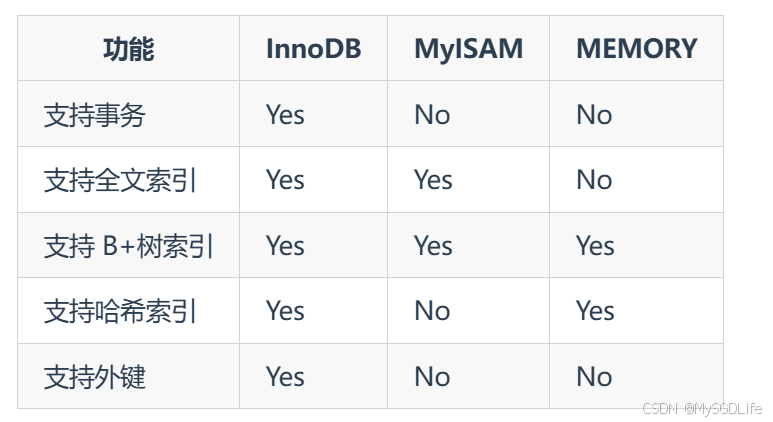
大多数情况下,使用默认的 InnoDB 就对了,InnoDB 可以提供事务、行级锁、外键、B+ 树索引、哈希索引、全文索引等能力。
MyISAM 适合读更多的场景。
MEMORY 适合临时表,数据量不大的情况。由于数据都存放在内存,所以速度非常快。
MyISAM与InnoDB的区别 2 *
存储结构、事务、索引、表(最小锁粒度、主键、外键、具体行数)
①、存储结构:
MyISAM:用三种格式的文件来存储,.frm 文件存储表的定义;.MYD 存储数据;.MYI 存储索引。
InnoDB:用两种格式的文件来存储,.frm 文件存储表的定义;.ibd 存储数据和索引。
②、事务支持:
MyISAM:不支持事务。
InnoDB:支持事务。
③、最小锁粒度:
MyISAM:表级锁,高并发中写操作存在性能瓶颈。
InnoDB:行级锁,并发写入性能高。
④、索引类型:
MyISAM 为非聚簇索引,索引和数据分开存储,索引保存的是数据文件的指针。
InnoDB 为聚簇索引,索引和数据不分开。
⑤、外键支持:MyISAM 不支持外键;InnoDB 支持外键。
⑥、主键必需:MyISAM 表可以没有主键;InnoDB 表必须有主键。
⑦、表的具体行数:MyISAM 表的具体行数存储在表的属性中,查询时直接返回;InnoDB 表的具体行数需要扫描整个表才能返回。
InnoDB BufferPool 1
Buffer Pool 是 InnoDB 存储引擎中的一个内存缓冲区,它会将数据以页(page)的单位保存在内存中,当查询请求需要读取数据时,优先从 Buffer Pool 获取数据,避免直接访问磁盘。
即便我们只访问了一行数据的一个字段,InnoDB 也会将整个数据页加载到 Buffer Pool 中,以便后续的查询。
修改数据时,也会先在缓存页面中修改。当数据页被修改后,会在 Buffer Pool 中变为脏页。脏页不会立刻写回到磁盘。InnoDB 会定期将这些脏页刷新到磁盘,保证数据的一致性。
通常采用改良的 LRU 算法来管理缓存页,也就是将最近最少使用的数据移出缓存,为新数据腾出空间。
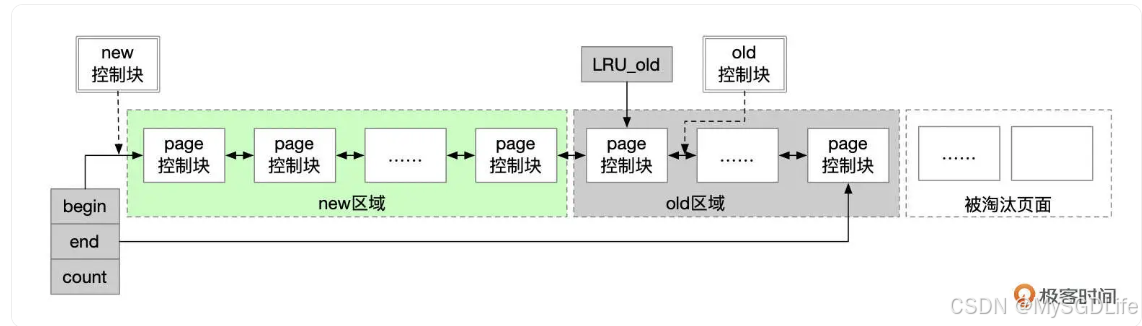
Buffer Pool 能够显著减少对磁盘的访问,从而提升数据库的读写性能。
在调优方面,我们可以设置合理的 Buffer Pool 大小(通常为物理内存的 70%),并配置多个 Buffer Pool 实例(通过 innodb_buffer_pool_instances)来提升并发能力。此外,还可以通过调整刷新策略参数,比如 innodb_flush_log_at_trx_commit,来平衡性能和数据持久性。
B+ 树和 B 树的比较* 2
B 树和 B+ 都是通过多叉树的方式,会将树的高度变矮,所以这两个数据结构非常适合检索存于磁盘中的数据。 但是 MySQL 默认的存储引擎 InnoDB 采用的是 B+ 作为索引的数据结构,原因有:
- B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
- B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
- B+ 树叶子节点之间用链表连接了起来,有利于范围查询,而 B 树要实现范围查询,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
为什么用B+树不用B树/二叉树/AVL/哈希表/跳表 * 2
-
IO次数少,B+树中间节点只存放索引,数据都在叶子节点中,中间节点可以存放更多索引项,因此在相同节点容量下,B+ 树的层级更少,树的高度更低,索引树更加矮胖
-
范围查询效率高,B树需要遍历整个树,B+树只需要遍历叶子节点中的链表
-
查询效率更稳定,每次查询从根节点到叶节点路径长度相同
-
有大量的冗余节点,插入删除效率更高
-
哈希索引只支持精确查找,不支持部分和范围查找,无法用于排序和分组,并且遇到大量哈希值相等的情况后查找效率会降低
-
普通二叉树存在退化的情况,如果它退化成链表,就相当于全表扫描。
-
虽然 AVL 树是平衡二叉树,但因为只有 2 叉,高度会比较高,磁盘 I/O 次数就会非常多。而 B+ 树是 N 叉,每一层可以存储更多的节点数据,树的高度就会降低,因此读取磁盘的次数就会下降,查询效率就快。
-
跳表基于链表,节点分布不连续,会频繁触发随机磁盘访问,性能较差。
跳表需要逐节点遍历链表,范围查询性能不如 B+ 树。
B+树一般几层 *
假如我们的主键 ID 是 bigint 类型,长度为 8 个字节。指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节。所以非叶子节点(一页16k)可以存储 16384/14=1170 个这样的单元(键值+指针)。
一个指针指向一个存放记录的页,一页可以放 16 条数据,树深度为 2 的时候,可以存放 1170*16=18720 条数据。
同理,树深度为 3 的时候,可以存储的数据为 1170117016=21902400条记录。
理论上,在 InnoDB 存储引擎中,B+树的高度一般为 2-4 层,就可以满足千万级数据的存储。查找数据的时候,一次页的查找代表一次 IO,当我们通过主键索引查询的时候,最多只需要 2-4 次 IO 就可以了。
B+树的范围查找怎么做的?* 2
B+ 树索引的范围查找主要依赖叶子节点之间的双向链表来完成。
第一步,从 B+ 树的根节点开始,通过索引键值逐层向下,找到第一个满足条件的叶子节点。
第二步,利用叶子节点之间的双向链表,从起始节点开始,依次向后遍历每个节点。当索引值超过查询范围,或者遍历到链表末尾时,终止查询。
关系型数据库和非关系型数据库的区别 * 2
前者高度组织化结构化数据;后者存储的数据结构不固定更加灵活,可以减少一些空间和时间的开销,后者更加容易水平扩展
前者支持结构化查询语言,支持复杂的查询功能和表关联。后者只能进行简单的查询
前者支持事务,具有ACID特性。后者则是BASE,最终一致性
MySQL解析过程,执行过程 * 2
1、**连接器;**连接到 MySQL 服务器:客户端与 MySQL 服务器建立TCP连接。
2、**解析器;**解析查询语句:MySQL 服务器接收到客户端发送的查询请求后,首先进行语法解析和词法解析,确保查询语句的正确性。
3、查询缓存:MySQL 服务器检查查询缓存,如果之前执行过相同的查询,并且查询结果在缓存中,则直接返回缓存结果,省去了后续步骤的执行。
4、优化器生成执行计划:对于未命中查询缓存的查询,MySQL 服务器使用查询优化器根据查询条件、表结构、索引等信息生成查询的执行计划。优化器会尝试选择最优的执行计划,以提高查询性能。
5、执行查询:MySQL 执行器根据优化器生成的执行计划执行查询操作。这包括从磁盘加载数据、执行排序和过滤、计算聚合等操作。
6、返回结果:执行完成后,MySQL 服务器将查询结果返回给客户端。
7、断开连接:客户端与 MySQL 服务器断开连接,释放资源。
如何优化数据库 *
Sql语句优化:分析慢查询日志,通过日志去找出IO大的SQL以及未命中索引的SQL;
避免使用SELECT*, 而是指定需要的列,尽量减少在WHERE子句中使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









