







 本文指导读者下载并配置JDK 1.8、Hadoop 2.7.7、Spark 2.4.7,包括Python 3.7环境,以及Hadoop on Windows的设置。详细讲解了环境变量配置、PySpark应用和文件操作,确保用户能够成功运行Spark示例代码处理电信客户流失数据。
本文指导读者下载并配置JDK 1.8、Hadoop 2.7.7、Spark 2.4.7,包括Python 3.7环境,以及Hadoop on Windows的设置。详细讲解了环境变量配置、PySpark应用和文件操作,确保用户能够成功运行Spark示例代码处理电信客户流失数据。
1.下载jdk1.8并配置环境变量
2.下载hadoop-2.7.7并配置环境变量
3.下载spark-2.4.7-bin-hadoop2.7并配置环境变量
4.下载python3.7的解释器并配置环境
上述环境变量的配置看文末。
5.下载hadooponwindows-master并且按照这篇文章配置
6.找到下载的spark-2.4.7-bin-hadoop2.7下的pyspark文件夹(比如我的在E:\environment\spark-2.4.7-bin-hadoop2.7\python下)拷贝到下载的Python37文件夹下的site-packages(E:\environment\Python37\Lib\site-packages)
7.安装py4j库,用管理员模式启动cmd命令窗口并进入Python37文件夹下的Scripts文件夹(比如我的在E:\environment\Python37\Scripts下),输入pip install py4j进行下载,如果下载失败参考我的这篇文章
8.检查Hadoop的bin目录下有无winutils.exe文件,若没有则将winutils.exe文件放到Hadoop的bin目录下。需要下载相应版本的winutils.exe
9.用管理员模式启动cmd命令窗口并输入pyspark,若看到welcome to spark字样则配置成功,如果显示没有权限则在cmd下进入到Hadoop的bin目录下,然后执行以下命令:
winutils.exe chmod 777 c:\tmp\Hive
10.打开pycharm新建spark.py输入以下代码:
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local", "Map app")
sqlContext = SQLContext(sc)
df = sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load(r'../data/WA_Fn-UseC_-Telco-Customer-Churn.csv')
df.show(30)
其中WA_Fn-UseC_-Telco-Customer-Churn.csv文件从下面这个网址下载:
csv文件下载
运行结果如图所示:显示前30行的数据。
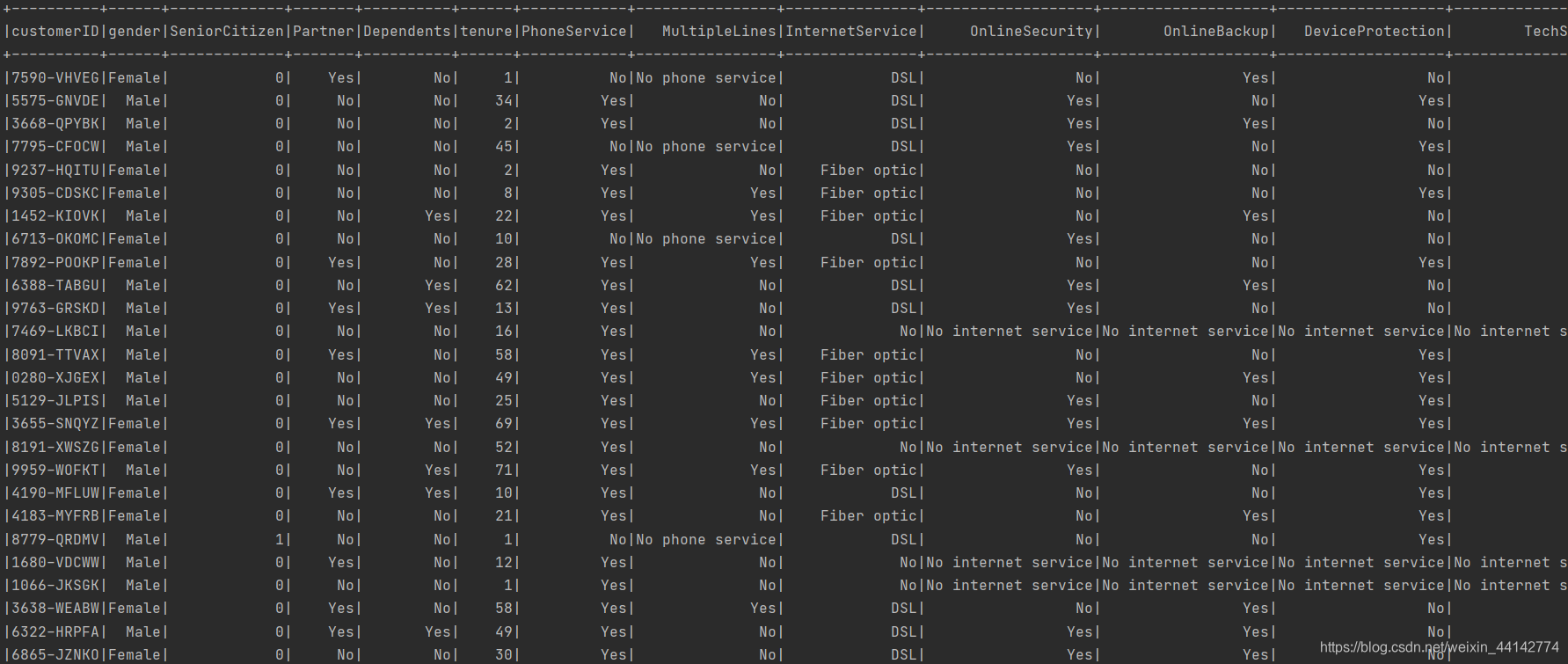
环境变量的配置:
(1)java的:用户变量里添加一个,path里添加一个
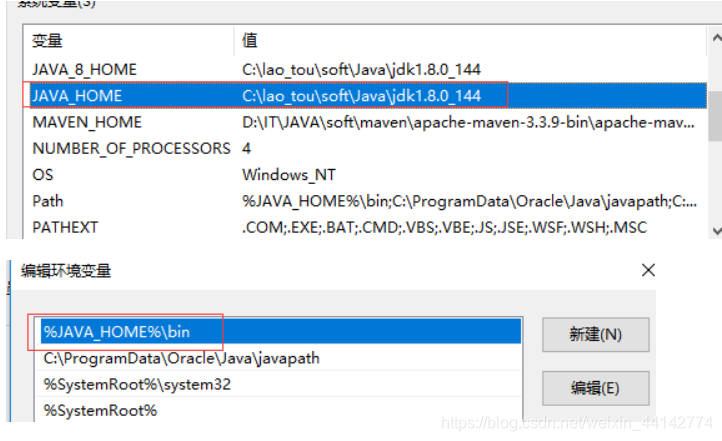 (2)spark的:用户变量里添加一个,path里添加一个
(2)spark的:用户变量里添加一个,path里添加一个
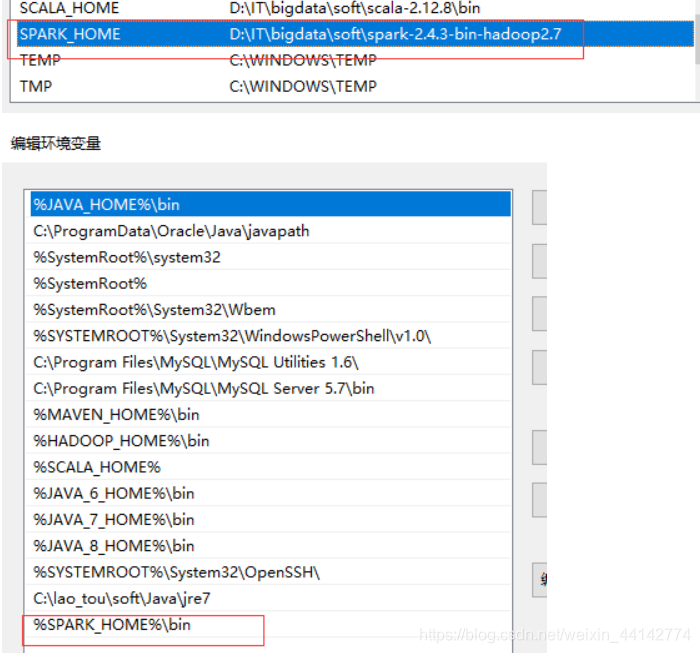
(3)hadoop的:用户变量里添加一个,path里添加一个
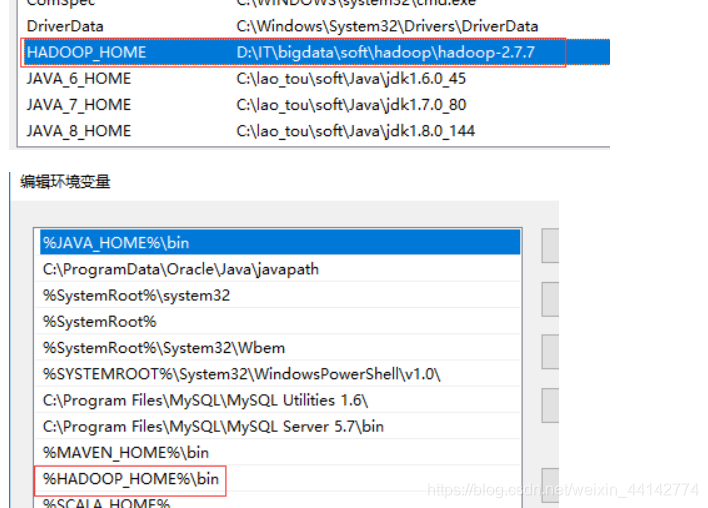
(4)python的:path里两个



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









