







 本文探讨了xgboost为何使用二阶展开优化损失函数,以及在损失函数无二阶导数时的处理方式。同时,对比了GBDT和xgboost的目标函数差异。文章还介绍了LSTM与Transformer在序列建模上的区别,以及RNN、LSTM和GRU在处理长期依赖问题上的优劣。此外,还讨论了k-means聚类算法的选择和调优方法,包括初始点选择、k值确定和优化策略。
本文探讨了xgboost为何使用二阶展开优化损失函数,以及在损失函数无二阶导数时的处理方式。同时,对比了GBDT和xgboost的目标函数差异。文章还介绍了LSTM与Transformer在序列建模上的区别,以及RNN、LSTM和GRU在处理长期依赖问题上的优劣。此外,还讨论了k-means聚类算法的选择和调优方法,包括初始点选择、k值确定和优化策略。
351为什么xgboost要二阶展开
- xgboost是以mse为基础推导出来的,在mse的情况下,xgboost的目标函数展开就是一阶项+二阶项的形式,而其他类似log loss这样的目标函数不能表示成这种形式。为了后续推导的统一,所以将目标函数进行二阶泰勒展开,就可以直接自定义损失函数了,只要二阶可导即可,增强了模型的扩展性。
- 二阶信息能够让梯度收敛的更快,类似牛顿法比SGD收敛更快。一阶信息描述梯度变化方向,二阶信息可以描述梯度变化方向是如何变化的。
352泰勒公式求e的近似值
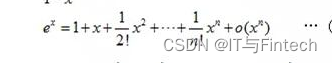 1+1/1!+1/2!+⋯+1/n!+⋯
1+1/1!+1/2!+⋯+1/n!+⋯
353XGBoost 如果损失函数没有二阶导,该怎么办
gbdt的目标函数与xgboost区别就是带不带正则项(算法内容上)。
gbdt对损失函数的优化是直接使用了损失函数的负梯度,沿着梯度下降的方向来减小损失,其是也就是一阶泰勒展开。
而xgboost在这里使用了二阶泰勒展开,因为包含了损失函数的二阶信息,其优化的速度大大加快。但如果loss没有二阶导数,就使用一阶导数优化
354GBDT的G梯度的向量长度为多少
样本数
355LSTM与Transformer的区别
- Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成,前后没有“时序”,可以实现并行计算,更高效;而LSTM是传统的RNN改进结构,有时序的概念,不能并行计算。
- LSTM引入三个控制门,拥有了长期记忆,更好的解决了RNN的梯度消失和梯度爆炸的问题;而Transformers依然存在顶层梯度消失的问题。
- LSTM的输入具备时序;而Transformers还需要利用positional encoding加入词序信息,但效果不好,而且无法捕获长距离的信息
- LSTM针对长序列依然计算有效;而Transformers针对长序列低效,计算量太大,self.attention的复杂度是n的2次方
- CNN和RNN结构的可解释性并不强,LSTM也一样;而Transfor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











