









Redis应用简说与python Windows下操作Redis
什么Redis?和MySQL,nosql的关系
在这之前我知道mysql ,sqlite3,Sql 等等这种数据库,使用起来的感觉的就是在数据库里面创建多个表,然后按照表的结构定义字段来记录信息。每个表之间能通过某些字段的信息连接起来,比如uid,name等。这类数据库称为关系型数据库。
nosql,指的是非关系型数据库 not only sql ,他们之间有什么不同呢?下面重点接受nosql 中的代表Redis.
最大的不同:redis存在的RAM里面,其它数据库存在ROM里面,那么在程序运行的时候,读取速度肯定是RAM快,这是redis的一个特点 Redis能读的速度是110000次/s,写的速度是81000次/s 。
那么我们再想想某些时候在操作数据库的时候有很多个操作,如果我们老是对数据库打开关闭,打开关闭,那会比较耗时。这个时候我们引入redis记录当前的数据,并且取数据从redis里面读取,执行结束后再从redis 保存数据至mysql 里面结束。那么操作起来会快很多。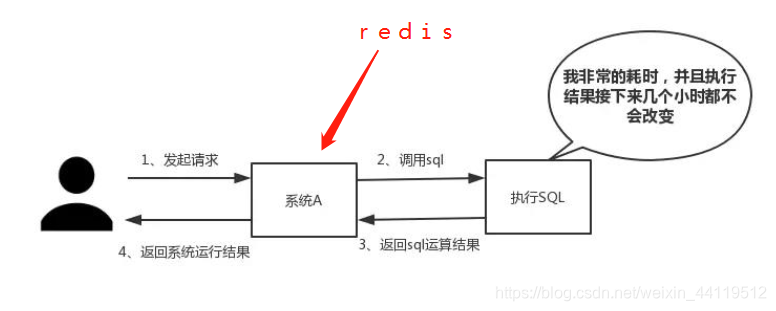
以上的情况只是一个redis的一个用法。还有其他应用晚点更。
咳咳,接下啦讲redis的使用了。
Redis安装和结构命令简介
windows:安装和使用这位前辈已经说的很清晰了,亲测有效:
https://www.jianshu.com/p/7d8c736bca7a,在这里就不多说了
Redis本质上就是一个数据库 和mysql类似的一个东西,只不过它是存在RAM 里面的。它没有字定义的结构,只有五种结构,了解它的结构的curd是学习Redis的重点内容。我先简单介绍redis的使用,然后重点介绍Python连接Redis‘
打开redis
win+R 后 输入 telnet 127.0.0.1 6379即可开始输入命令
String、List、Set、Zset、hash五种数据结构简单介绍**
String
命令体 set + key+ content
set 是字符串的设置命令,key表示这个字符串的名字,content是这个字符串的内容。
set hhh hhh#写入字符串
get hhh#获取字符串命令
结果:hhh
List
收到python的影响我们自然会联想到列表的结构,其实不然,我认为更像数据结构里面的栈,因为它的命令就很像栈,加上它的索引就是LIFO的机制。可以对list查询,删除,修改,更改,匹配等操作
命令体:
lpush + key + content
压栈
lpop + key
#出栈
看一下代码可以知道是栈的结构 last in first out
lpush yun 999
:1
lpush yun 999999
:2
lrange yun 0 -1
*2
$6
999999
$3
999
lpop yun
$6
999999list 的其它功能命令,简要说明:
索引查询 :
lrange + key + firstPlace+stopPlace
其中的firstPlace,stopPlace 表示索引,第几个的意思这里的第0个就是最后压栈的那个,不懂的要看一下栈的结构。神奇的是redis的List支持反向索引,因此,要查看所有的List就是:
lrange key 0 -1Hash
hash ,这就有点像mysql的样子了 有自己的字段和内容,可以对字段增减查询删除
创建hash 命令体
hmset +key+ field0 +“content0”+field1+“content1”…
查看结构以及内容命令体:
HGETALL +key
查看结构命令体:
Hkeys +key
查看值命令体:
hvals +key
分别对应一下四句命令
HNSET zzz name "zzz" age "18" sex "boy"
HGETALL zzz
HKEYS zzz
HVALS zzzSet
就是一个集合的结构,每个集合都是去重的,是唯一的,在集合里的单位称之为成员member,可以对集合做添加,查看求两个集合的差集,并集,匹配集合成员等操作
创建并添加集合命令体:
sadd +key + member0,menber1…
查询集合命令体:
Smembers + key
SADD dog "erha","lala"
Smember dogZset(sorted Set)
是一个有序的set, 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。Zset支持集合的创建索引查询,修改,删除,升序降序查询,范围内的升序降序查询等操作。
创建命令体:
ZADD + key + score0+ member0 + score1 + member01
其中score表示联合的分数。
查询命令体:
ZRANGE + key + startPlace + stopPlace
ZADD test "100" "xiaoming" "90" "xiaohong"本部分结语:命令是大小写通用的 建议用大写,有时候小写不行不知道为什么。
这里只是对这个结构做简单介绍详细的命令建议去菜鸟教程里面看一下命令,但是我认为实际应用中的命令是不常用的 重点看其它语言怎么连接redis。
Python连接和使用Redis
首先必须先引入redis库文件:
- 打开WIN +R 切换到安装的python带scripts的路径后输入
- pip install redis 好了之后先打开redis,这里不同于mysql 必须要先打开redis才能连接成功。
- 创建连接
r = redis.StrictRedis(host="127.0.0.1",port= 6379,db = 1)这里是不是很眼熟了 ,和python pymysql非常像。一个程序可以同时建立多个连接。
好了差不多就说到这里了,关于python连接redis 并操作结构的用法都在我下面的程序注释里面了,每一部分用分割线分开了 ,相信聪明的你看这个代码不会费力的。
import redis
#安装直接pip install redis
#写在前面:redis 是在ram里面的一个数据库 ,本质上是数据库,当程序运行一次写操作,结束后redis并没有擦除这个key的信息,
#因此连续运行写入的程序的话
#例如lpush("key",111),lrange("key",0,-1)运行了一次之后继续运行一次代码,则redis 的key会记录两次111,
# 因此有必要在这之前注释一部分写入的代码或者其它方案避免
r = redis.StrictRedis(host="127.0.0.1",port= 6379,db = 1)
#String
print("----------string---------------")
r.set('usrname',"yq")
print(r.client_getname())
print(r.get("usrname"))
#Hash
print("----------hash---------------------------------------")
r.hmset("yuquan",{"name":"yuq","sex":"man","age":"18"})
print(r.hgetall("yuquan"))#查询哈希结构和值
print(r.hkeys("yuquan"))#返回list 结构
print(r.hvals("yuquan"))#返回list 结构
print(r.hdel("yuquan","name"))#删除字段name
print(r.hgetall("yuquan"))
print(r.hlen("yuquan"))#查询长度
print(r.hget("yuquan","age"))#获取某一个字段的大小
print(r.hincrby("yuquan","age","19"))#这个操作是属于增减操作,19 是一个向量而不是19替代了18 不是替换修改的的操作
print(r.hset("yuquan","age","19"))#这个才是修改操作,这就是hmset 和set的区别,hmset 是hash创建的时候用的
#而hset 是用在修改字段信息的时候用的
r1 = redis.StrictRedis(host="127.0.0.1",port= 6379,db = 2)
r1.hmset("zyq",{"name":"zyq","age":11})
print(r1.hgetall("zyq"))
print("---------list-----------------------------")
print(r1.lpush("yuquan",1,2,3,4,5))#运行一次后注释掉,也可以试试不注释掉看结果,然后重启redis
#list其实这个应该说是一个栈的结构,LIFO,last in first out 机制
print(r1.lpop("yuquan"))
print(r1.llen("yuquan"))#查看这个List的长度
print(r1.lrange("yuquan",0,-1))#查看整个list的内容
print(r1.lindex("yuquan",-1))#索引list
print(r1.linsert("yuquan","before",1,10000))#插入,在内容之前插入
print(r1.linsert("yuquan","after",1,6666))
print(r1.lrange("yuquan",0,-1))
#set
#如果觉得乱请注释掉以上的代码 我没关系,随意
print("------set--------------------------------------")
r3 = redis.StrictRedis(host="127.0.0.1",port= 6379,db = 3)
r3.sadd("dog","erha")#加入集合dog,erha
r3.sadd("dog","labuladuo")#加入集合dog,labuladuo
print(r3.smembers("dog"))#{b'erha', b'labuladuo'}
r3.sadd("dog","bianMu")#加入边牧近狗及
print(r3.scard("dog"))#查看集合里面有多少成员,只有 拉布拉多和二哈所以是2
#为了做一些集合的操作必须再建一个集合
r3.sadd("smartDog","labuladuo","bianMu")#这个集合是聪明的dog
print(r3.smembers("smartDog"))
print(r3.sdiff("dog","smartDog"))#两个集合的差集,明显是二哈
print(r3.sunion("dog","smartDog"))#返回两个集合的并集
print(r3.sismember("dog","erha"))#判断子集是否在集合里面 布尔型
print(r3.srem("dog","erha"))#移除成员 ,二哈不干了
print(r3.smembers("dog"))
#sorted Set
print("-------------sorted Set---------------------")
'''Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
'''
dogIntelligence = "dogIntelligence"
print(r3.zadd(dogIntelligence,{"bianMu":100,"erha":60,"lala":90}))
#zadd(key,mapping),mapping就是映射关系的意思所以写的应该是字典结构的才对哦
print(r3.zcard(dogIntelligence))
print(r3.zcount(dogIntelligence,max=70,min = 50))#查看这个有序集合中的70,50之间有多少个,显然只有二哈
print(r3.zrange(dogIntelligence,start=0,end=-1,desc = True))#[b'bianMu', b'lala', b'erha']
# 降序,默认是升序,去掉desc后 就是升序
print(r3.zrange(dogIntelligence,start=0,end=-1,desc=True,withscores= True ))
#withscores= True在结果中加入分数[(),()] [(b'bianMu', 100.0), (b'lala', 90.0), (b'erha', 60.0)]
print(r3.zscore(dogIntelligence,"bianMu"))#查看成员的得分
print(r3.zrem(dogIntelligence,"erha"))#删除一个成员
print(r3.zrange(dogIntelligence,start=0,end=-1,desc = True))#感谢观看,有兴趣关注下。

















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









