







 本文档详细介绍了如何在Deepstream 5.1上顺利部署CenterFace人脸识别模型,包括解决官方代码的小错误,提供从ONNX到TRT的转换方法,以及具体的操作步骤。博主提醒注意5.1版本的环境配置,并分享了踩坑经验,帮助开发者避免常见问题。此外,还给出了优化推理速度的建议。
本文档详细介绍了如何在Deepstream 5.1上顺利部署CenterFace人脸识别模型,包括解决官方代码的小错误,提供从ONNX到TRT的转换方法,以及具体的操作步骤。博主提醒注意5.1版本的环境配置,并分享了踩坑经验,帮助开发者避免常见问题。此外,还给出了优化推理速度的建议。
Deepstream_CenterFace
最近身心巨累,算法篇一直没更,分享点工程把。原因是没怎么学习新知识且transformer系列更新产出之快,主要还是都在工程任务上,今天分享下deepstream5.1 适配centerface 丝滑版本部署, 无需踩坑,我把这个工程添加进了我的deepstream git. 喜欢给star谢谢,任何部署问题随时交流!肝了两天麻烦给个🌟
my github:Deepstream_CenterFace
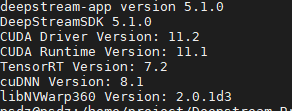
Deepstream5.1 友情提示:
5.1版本加了一些文件,一切环境问题大多都是补充软链接和环境变量和编译路径等等!!!!!!!只要你按官网要求步骤一步步来都能按好,编译注意环境路径即可,相信一名合格的工程师这点根本不是问题,不多赘述。
opencv=4.5.0(ippciV这个自己手动加进目录就行了)

一、CenterFace 结构
由于模型需要从ONNX到trt转换,我们在原作者GIT上直接可以获取原始的模型权重,我的代码里给力下载命令,我可以自己进行转换工作,当然也可以直接修改网络继续训练,这里直接说明坑在哪里,对于CenterFace是基于CenterNet的anchorfree变体检测人脸版本,我们在做部署的时候,最关键的是我们需要明白一个模型的输入和输入形态,这里一般是两个输入维度640x640和640x480,两种可以任意选择,当然网络输出后4倍降采样就是160和120,自己心里知道就好了。
二、nvidia官方代码有个小错误
在解析代码中,这个取法是错误的,别问我怎么知道,踩了两天坑模型没输出,以为是模型,玩命花式转换,最后打印了解码部分,才发现!
int fea_h = heatmap->inferDims.d[2]; //#heatmap.size[2];
int fea_w = heatmap->inferDims.d[3]; //heatmap.size[3]; #这里是0,所以后面全是会得0,就没有BOX的输出了。。。
改下下标就好了 …
int fea_h = heatmap->inferDims.d[1]; // 120
int fea_w = heatmap->inferDims.d[2]; //160
``
暗叹到,细节决定成败… 按照官方给的代码那里输出是0,然后就全都没了,在deepstream中非常容易误导开发者认为是自己的模型有问题,因为tensorrt和别的C版本是需要图片Demo推理的,和deepstream的逻辑架构不一样,deepstream的解析属于纯解码。
三.按照我的git Readme直接操作
my github:Deepstream_CenterFace,麻烦star!
cd Deeepstream_CenterFace
cd Centerface
wget https://github.com/Star-Clouds/CenterFace/raw/master/models/onnx/centerface.onnx //下载作者的ONNX
python export_onnx.py //得到属于你要的维度的模型ONNX
mkdir build
cd build
cmake ..
make
./CenterFace_trt ../config.yaml ../samples //得到TRT,这里config调好了
mv centerface.trt ../
2.run deepstream_CenterFace
cd nvdsinfer_custom_impl_CenterFace/
make //编译解析CPP
cd ..
wget https://developer.nvidia.com/blog/wp-content/uploads/2020/02/Redaction-A_1.mp4 // download 测试视频
deepstream-app -c deepstream_app_config_centerface.txt
输出LOG如下,然后生成一个MP4文件。
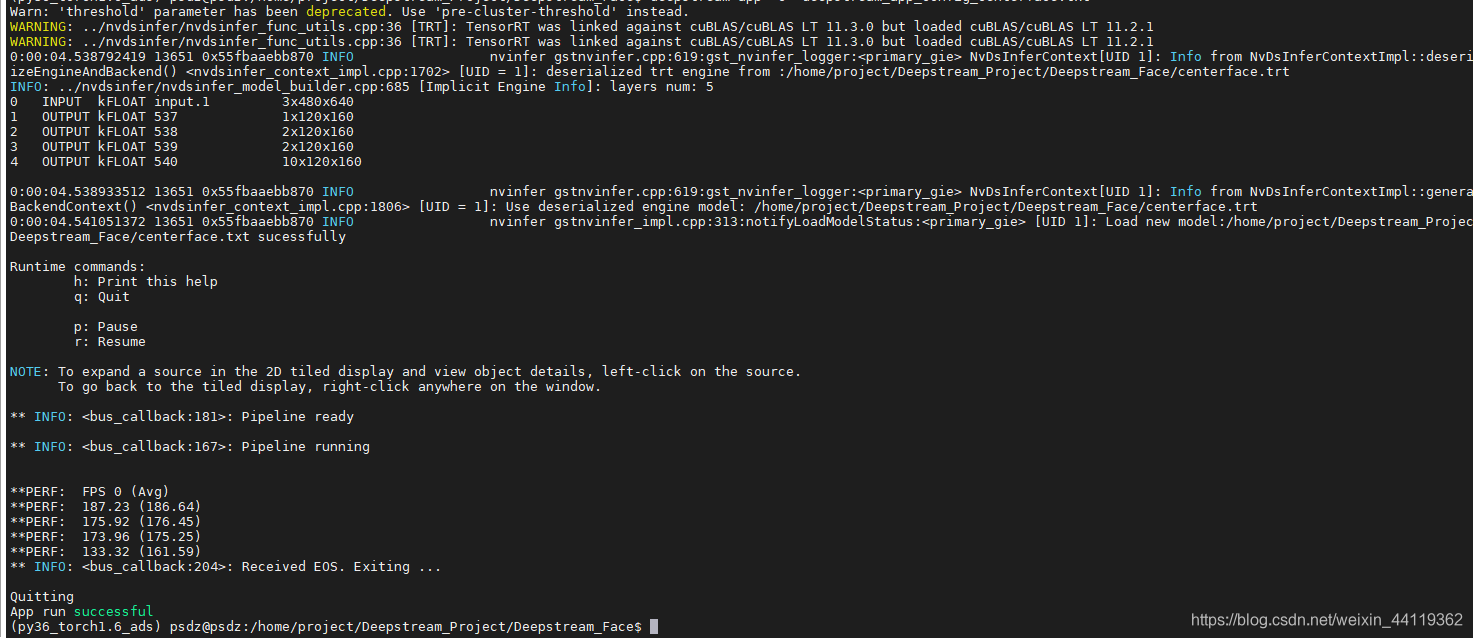
如果你的后续任务是不需要关键点的,在推理中,把关键点Landmarks的数据结构全部删掉就行,能提升推理速度!
关于利用trt转换模型,在cpp转换并使用推理的代码中没有BOX输出的问题,其实不是模型的问题,如果改成640X640就可以输出和deepstream部署没有关系。
总结
简单演示下,麻烦Star下,后续开源各种deepstream部署,关于这个我会把人脸对齐和识别级联起来,后续更新,而算法理解篇最近实在累但是肯定会更。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









