







提示:持续更新中。。。。。。
文章目录
JVM基础知识
分析工具
Heap Dump分析工具
https://heaphero.io/
GC log分析工具
https://gceasy.io/
一、收集器
1、收集器搭配
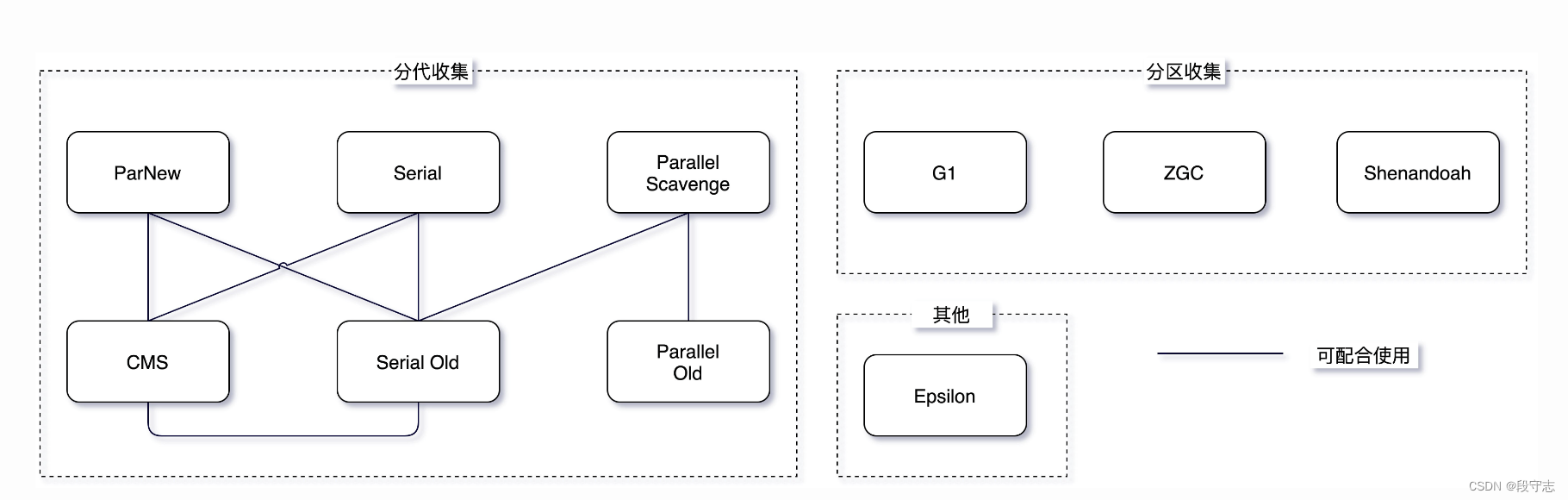
- UseSerialGC = Serial + Serial Old
- UseParNewGC = ParNew +Serial Old
- UseConcMarkSweepGC = ParNew + CMS + Serial Old
- UseParallelGC = ParallelSeavenge + ParallelOld
- UseParallelOldGC = ParallelSeavenge + ParallelOld
分代收集器
ParNew: 一款多线程的收集器,采用复制算法,主要工作在 Young 区,可以通过 -XX:ParallelGCThreads 参数来控制收集的线程数,整个过程都是 STW 的,常与 CMS 组合使用。
CMS: 以获取最短回收停顿时间为目标,采用“标记-清除”算法,分 4 大步进行垃圾收集,其中初始标记和重新标记会 STW ,多数应用于互联网站或者 B/S 系统的服务器端上,JDK9 被标记弃用,JDK14 被删除,详情可见 JEP 363。
分区收集器
G1: 一种服务器端的垃圾收集器,应用在多处理器和大容量内存环境中,在实现高吞吐量的同时,尽可能地满足垃圾收集暂停时间的要求。
ZGC: JDK11 中推出的一款低延迟垃圾回收器,适用于大内存低延迟服务的内存管理和回收,SPECjbb 2015 基准测试,在 128G 的大堆下,最大停顿时间才 1.68 ms,停顿时间远胜于 G1 和 CMS。
2、默认收集器
- JDK1.7 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
- JDK1.8 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
- JDK1.9-11 默认垃圾收集器G1
3、查看收集器
java -XX:+PrintCommandLineFlags -version
-XX:G1ConcRefinementThreads=15 -XX:GCDrainStackTargetSize=64 -XX:InitialHeapSize=530435264 -XX:MaxHeapSize=8486964224 -XX:+PrintCommandLineFlags -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC -XX:-UseLargePagesIndividualAllocation
- -XX:+UseG1GC : 使用了G1收集器
二、JVM参数
1、全局参数
打印出JVM系统所有参数列表
java -XX:+PrintFlagsFinal -version
2、进程运行参数
jinfo -flags 16140
VM Flags:
-XX:-BytecodeVerificationLocal -XX:-BytecodeVerificationRemote -XX:CICompilerCount=12 -XX:ConcGCThreads=4 -XX:G1ConcRefinementThreads=15 -XX:G1HeapRegionSize=2097152 -XX:GCDrainStackTargetSize=64 -XX:InitialHeapSize=530579456 -XX:+ManagementServer -XX:MarkStackSize=4194304 -XX:MaxHeapSize=8487174144 -XX:MaxNewSize=5091885056 -XX:MinHeapDeltaBytes=2097152 -XX:NonNMethodCodeHeapSize=12163472 -XX:NonProfiledCodeHeapSize=239494768 -XX:ProfiledCodeHeapSize=0 -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:TieredStopAtLevel=1 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC -XX:-UseLargePagesIndividualAllocation
三、吞吐量与低延时
1、吞吐量
概念
吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)
意义
衡量CPU 用于运行用户代码的时间与 CPU 总消耗时间的比值
比如单位时间10分钟,其中1分钟CPU资源被垃圾回收占用,其余9分钟CPU资源被用户线程占用,那么此时的吞吐连就是90%。用来衡量用户进程占有CPU资源的利用率的高低。
2、低延时
概念
垃圾收集时候停顿的时间短,响应用户请求快。
意义
便于开发B/S高效快速响应系统。
3、二者不可兼得
如果需要一个高吞吐的JVM进程,那么从上面得公式可知在同等的时间内垃圾收集消耗的CPU时间越短,那么吞吐量就越高。极端分析假设垃圾收集永远不会触发,那是不是吞吐量就可以最高了。但是垃圾收集不触发是不现实的,最终都是需要垃圾清理的,只是这样的话会导致后面垃圾清理的任务繁重导致单次GC时长会加大,从而延迟加大。
如果需要一个低延迟的JVM进程,那么就需要频繁或者及时的去清理垃圾触发GC,这样就可以减轻每次GC的负担,从而降低延迟。但是频繁的GC就会占用过多的额外CPU资源,从而导致吞吐量下降。
四、垃圾收集日志
G1日志
Pause Young (Normal) (G1 Evacuation Pause) GC原因,Young GC
Heap before GC invocations=12555 (full 0): GC前对象引用计数
garbage-first heap total 2072576K, used 1874869K [0x0000000741800000, 0x0000000800000000) 使用了G1垃圾收集器,堆总大小2072576K,使用了1874869K
region size 2048K, 759 young (1554432K), 3 survivors (6144K) Region大小为2M,青年代占用了759个(共1554432K),幸存区占用了3个(共6144K)
Metaspace used 85721K, committed 86592K, reserved 344064K 元数据取大小(没有设置MetaspaceSize=MaxMetaspaceSize,则会有committed和reserved)
class space used 8771K, committed 9280K, reserved 212992K
Using 4 workers of 4 for evacuation
Desired survivor size 265289728 bytes, new threshold 15 (max threshold 15)
Pre Evacuate Collection Set: 0.3ms 预处理共耗时0.3ms,包括选择Region,扫描Root,更新添加Region到Collection Set等
Merge Heap Roots: 0.2ms 扫描合并Rset
Evacuate Collection Set: 2.6ms 拷贝存活对象到新region,年龄大于max threshold则进入老年代,并处理引用
Post Evacuate Collection Set: 1.2ms 垃圾处理后操作,包括更新code root 引用,清除card table等
Other: 0.1ms 其他事项共耗时0.1ms,其他事项包括选择CSet,处理已用对象,引用入ReferenceQueues,释放CSet中的Region到free list
Age table with threshold 15 (max threshold 15)
- age 1: 2223472 bytes, 2223472 total
- age 2: 719736 bytes, 2943208 total
- age 3: 60552 bytes, 3003760 total
Eden regions: 756->0(757) 垃圾回收前后Eden区数量(Eden区总数为757)
Used: 0K, Waste: 0K
Survivor regions: 3->2(253) 垃圾回收前后Survivor区数量(Survivor区总数为253)
Used: 4072K, Waste: 23K
Old regions: 73->73
Used: 147878K, Waste: 1625K
Archive regions: 2->2
Used: 2016K, Waste: 2080K
Humongous regions: 85->7
Used: 14336K, Waste: 0K
Metaspace: 85721K(86592K)->85721K(86592K) NonClass: 76949K(77312K)->76949K(77312K) Class: 8771K(9280K)->8771K(9280K)
Heap after GC invocations=12556 (full 0):
garbage-first heap total 2072576K, used 168302K [0x0000000741800000, 0x0000000800000000)
region size 2048K, 2 young (4096K), 2 survivors (4096K)
Metaspace used 85721K, committed 86592K, reserved 344064K
class space used 8771K, committed 9280K, reserved 212992K
Pause Young (Normal) (G1 Evacuation Pause) 1832M->164M(2024M) 4.796ms 此次Young GC从1832M回收至164M,耗时4.796ms
User=0.02s Sys=0.00s Real=0.00s
Safepoint "G1CollectForAllocation", Time since last: 85999229627 ns, Reaching safepoint: 49914 ns, At safepoint: 4898699 ns, Total: 4948613 ns 安全点为G1CollectForAllocation
五、常用参数
nohup java -jar \
#开启jvitualvm远程连接,192.168.10.16为当前机器IP;7098为连接端口
-Djava.rmi.server.hostname=192.168.10.16 \
-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.rmi.port=7098 \
-Dcom.sun.management.jmxremote.port=7099 \
-Dcom.sun.management.jmxremote.authenticate=false \
-Dcom.sun.management.jmxremote.ssl=false \
#jvm OOM时内存快照文件输出,tmp必须提前创建好
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/tmp/gc.hprof \
#jvm相关erro日志,便于后续分析问题
-XX:ErrorFile=java_error_%p.log \
#jvm gc日志,便于后续分析问题。这里适合jdk9以及往后
#需要注意jdk8 gc日志输出配置有所区别可以具体网上搜下
-Xlog:gc*:gc.log:time:filecount=10:filesize=1m \
#-XX:InitialHeapSize=4164069376 \
#-XX:MaxHeapSize=4164069376 \
-Xms512m \
-Xmx512m \
#栈大小设置,线程栈的大小,经测试可以默认设置到600k差不多。一般栈的调用深度3000-5000依据来算的。
#可以写一个递归调用,然后设置一个栈值大小,如果能达到3000-5000深度调用表示一个够用的栈大小。
-Xss600k \
#设置用到的垃圾收集器(CMS、G1等)
-XX:+UseG1GC \
#开启类的卸载日志
-XX:+TraceClassUnloading \
-Xverify:none \
-XX:+PrintCommandLineFlags \
-XX:+PrintFlagsFinal \
jvm.jar > jvm.log 2>&1 &

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









