







 本文通过对CountedCompleter示例的解读,展示了如何使用它在MapReduce场景下实现并行任务的分发与合并。通过模拟班级收暑假作业的过程,详细阐述了任务的分发、执行与收集,揭示了其在处理多层级任务中的灵活性和效率。
本文通过对CountedCompleter示例的解读,展示了如何使用它在MapReduce场景下实现并行任务的分发与合并。通过模拟班级收暑假作业的过程,详细阐述了任务的分发、执行与收集,揭示了其在处理多层级任务中的灵活性和效率。
在CountedCompleter的类注释中,有个关于CountedCompleter如何应用到MapReduce场景的示例代码,这里稍微理了下思路。
示例如下:
class MapReducer<E> extends CountedCompleter<E>{
final E[] array;
final MyMapper<E> mapper;
final MyReducer<E> reducer;
final int low, high;
MapReducer<E> forks, next;
E result;
public MapReducer(
CountedCompleter<?> completer,
E[] array,
MyMapper<E> mapper,
MyReducer<E> reducer,
int low,
int high,
MapReducer<E> next) {
super(completer);
this.array = array;
this.mapper = mapper;
this.reducer = reducer;
this.low = low;
this.high = high;
this.next = next;
}
@Override
public void compute() {
int l = low, h = high;
while (h - l > 1){
int mid = (l + h) >>> 1; //向右移一位 等效 除以2
addToPendingCount(1);
forks = new MapReducer<>(this, array, mapper, reducer, mid, h, forks);
forks.fork();
h = mid;
}
if (h > l){
result = mapper.apply(array[l]);
}
for (CountedCompleter<?> c = firstComplete(); c != null; c = c.nextComplete()){
for (MapReducer<E> t = (MapReducer) c, s = t.forks; s != null; s = t.forks = s.next){
E tr = t.result;
E sr = s.result;
t.result = reducer.apply(tr, sr);
}
}
}
@Override
public E getRawResult() {
return result;
}
public static <E> E mapReduce(E[] array, MyMapper<E> mapper, MyReducer<E> reducer){
return new MapReducer<>(null, array, mapper, reducer, 0, array.length, null).invoke();
}
}示例解读:
在本示例中,主要通过二分的方式fork线程来执行map操作,然后再有父线程来执行reduce操作对map的结果进行合并。在这里要注意的是,每次fork新线程需要由父线程管理一个挂起数(pending),当父线程管理的pending为0时,该父线程执行完成。这里相比于ForkJoin,可以通过addToPendingCount更精确的管理fork出的线程。
扩展示例:
下面是根据这个示例设计的一个扩展示例,一个班级收集暑假作业为例来解释,这个例子比官方提供的DEMO稍微复杂一点,目的是为了扩展对官方DEMO的理解。
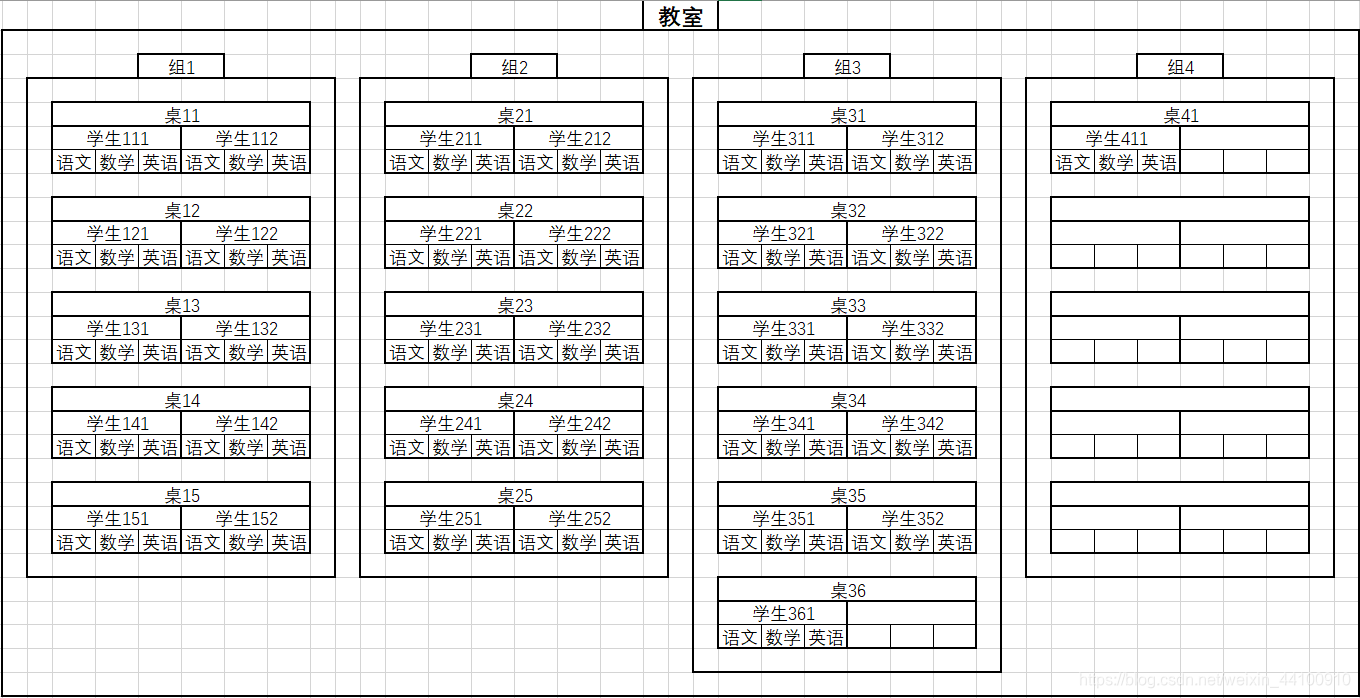
例子前提:一个班级有四个组,每个组有N桌,每桌人数不同,具体如图所示(目的是为了演示DEMO中的分支流程),现在班主任要每科的课代表来每科的暑假作业,共三个学科:语文,数学,英语。这里模拟的收作业的任务是返回作业数量即可。
操作流程:
- 班主任将收作业的任务分给每科的课代表,由课代表收相应学科的作业;如果只有一个学科,则直接将任务交给组长;
- 课代表将收作业的任务交给组的组长,负责收集该组的相应学科的作业;如果该组只有一桌,直接将任务交给这桌的最左边同学;
- 组长将收作业的任务交给每桌的最左边的同学,负责收集该桌的相应学科的作业;如果该桌只有一个同学,直接将任务交给该同学;
- 每个同学收集完自己的作业,交给负责收作业的人;
- 每桌最左边的同学将该桌的作业收好后交给该组的组长;
- 组长将该组的所有所有作业收完之后交给课代表;
- 课代表收完每个组的作业之后交给班主任;
- 班主任汇总所有的作业。
具体实现逻辑:
- 班主任根据三个学科将任务分给三个课代表(fork三个收作业的任务),此时记录挂起数(pending)为3,由于fork了新线程,所以,该任务不会直接结束。
- 课代表将任务分给每个组的组长(每个课代表fork四个收作业任务给组长),此时,该课代表记录的挂起数(pending)为4,由于fork了新线程,所以也不会结束。
- 而组长也将任务分到每桌最左边的人,每桌fork一个新线程;
- 每桌最左边的人fork一个新任务给同桌,由同桌负责整理自己的作业。
- 同桌将作业做完之后,因为该同学没有fork新任务,所以检查负责收作业的同桌是否完成作业的整理,如果整理完成,则作业交给负责收作业的同桌整理到一起;如果负责收作业的同学没有整理好,那么该任务直接标记完成,等负责收作业的同学自己来收。
- 当该桌的两个同学的作业都收集完成后,由负责收作业的同学通知该组的组长,等待收作业,如果组长收到该组的每桌负责收作业的同学的完成信号,那么组长从最后一个人开始依次收完该组的每一桌的作业,该组长的任务完成;否则等待最后一桌收集完成,再来让组长收一组的作业。
- 当组长完成收集任务后,通知课代表,等待收作业,如果课代表收到每一组的组长的完成信号,那么课代表从最后一组开始收作业;否则等待最后一组组长收集完成,再来让课代表收集每一组的作业。
- 课代表收集完作业后,通知班主任,等待收作业,如果班主任收到每科课代表的完成信号,那么班主任从分配的最后一科开始收集;否则等待最后一个课代表的收集任务完成,再来收集所有科的作业。
- 完成收集任务。
代码如下:
class HomeworkCollectWork extends CountedCompleter<Integer>{
private int count;
private int type;// 1、按学科;2、按组;3、按桌,4、按人
private List students;
private HomeworkCollectWork forks, next;
public HomeworkCollectWork(CountedCompleter<?> completer, int type, List students, HomeworkCollectWork next) {
super(completer);
this.type = type;
this.students = students;
this.next = next;
}
@Override
public void compute() {
if (type == 1 && students.size() == 1){
//如果只有一个学科,按组分
type = 2;
students = (List) students.get(0);
}
if (type == 2 && students.size() == 1){
//如果只有一个组,按桌分
type = 3;
students = (List) students.get(0);
}
if (type == 3 && students.size() == 1){
//如果只有一桌,按人分
type = 4;
students = (List) students.get(0);
}
if (students.size() > 1){
addToPendingCount(students.size());
for (int i = 0; i < students.size(); i++) {
List list;
Object obj = students.get(i);
if (obj instanceof String){
list = new ArrayList();
list.add(obj);
}else {
list = (List) obj;
}
//父线程fork新线程时,forks属性始终指向最近fork出的线程
//每次fork的新线程的next属性执行前一个fork出的线程
//这样就形成了链表,可以通过forks属性和next属性遍历整个链表,root -> forks -> next -> next -> next -> null
forks = new HomeworkCollectWork(this, type + 1, list, forks);
forks.fork();
}
}else if (students.size() == 1){
//此处为模拟业务
this.count = 1;
}else {
return;
}
/**
* 每个线程在此处检查:
* 1、当前线程是否结束,如果已结束,遍历所有它fork出来的所有线程,合并所有线程的结果
* 2、检查当前线程的父线程(这里依赖的是构造新CountedCompleter时,需要将父CountedCompleter传给当前CountedCompleter)
* 如果父线程也执行完成,汇总父线程fork出来的所有线程,合并所有线程的结果,以此类推
* 3、如果找到root线程(父CountedCompleter为空),任务结束
*/
for (HomeworkCollectWork c = (HomeworkCollectWork) firstComplete(); Objects.nonNull(c);
c = (HomeworkCollectWork) c.nextComplete()){
for (HomeworkCollectWork t = c, s = t.forks; Objects.nonNull(s); s = t.forks = s.next){
//此处为模拟业务,统计作业数量
t.count += s.count;
}
}
}
@Override
public Integer getRawResult() {
return count;
}
}继续扩展:
在上面例子的基础上,我们可以看到,忽略任务的层级数,就可以实现统计每个枝干的叶子节点数。
class LeafCountWork extends CountedCompleter<Integer>{
private int count;
private List branches;
private LeafCountWork forks, next;
public LeafCountWork(CountedCompleter<?> completer, List branches, LeafCountWork next) {
super(completer);
this.branches = branches;
this.next = next;
}
@Override
public void compute() {
for (int i = 0; i < branches.size(); i++) {
List list;
Object obj = branches.get(i);
if (obj instanceof String){
//叶子节点
this.count++;
}else {
addToPendingCount(1);
list = (List) obj;
forks = new LeafCountWork(this, list, forks);
forks.fork();
}
}
for (LeafCountWork c = (LeafCountWork) firstComplete(); Objects.nonNull(c);
c = (LeafCountWork) c.nextComplete()){
for (LeafCountWork t = c, s = t.forks; Objects.nonNull(s); s = t.forks = s.next){
//此处为模拟业务,统计数量
t.count += s.count;
}
}
}
@Override
public Integer getRawResult() {
return count;
}
}该示例更加通用,可以用来遍历未知层级的树结构。
###更多笔记请关注公众号,不定期更新###



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









