







大数据之路系列之hive(05)
hive
一、什么是Hive?
Hive中包含的有SQL解析引擎,它会将SQL语句转译成M/R Job,然后在Hadoop中执行
二、Hive的数据存储
Hive的数据存储基于Hadoop的 HDFS
Hive没有专门的数据存储格式
Hive默认可以直接加载文本文件(TextFile),还支持SequenceFile、RCFile等文件格式
针对普通文本数据,我们在创建表时,只需要指定数据的列分隔符与行分隔符,Hive即解析里面的数据
三、Hive的系统架构
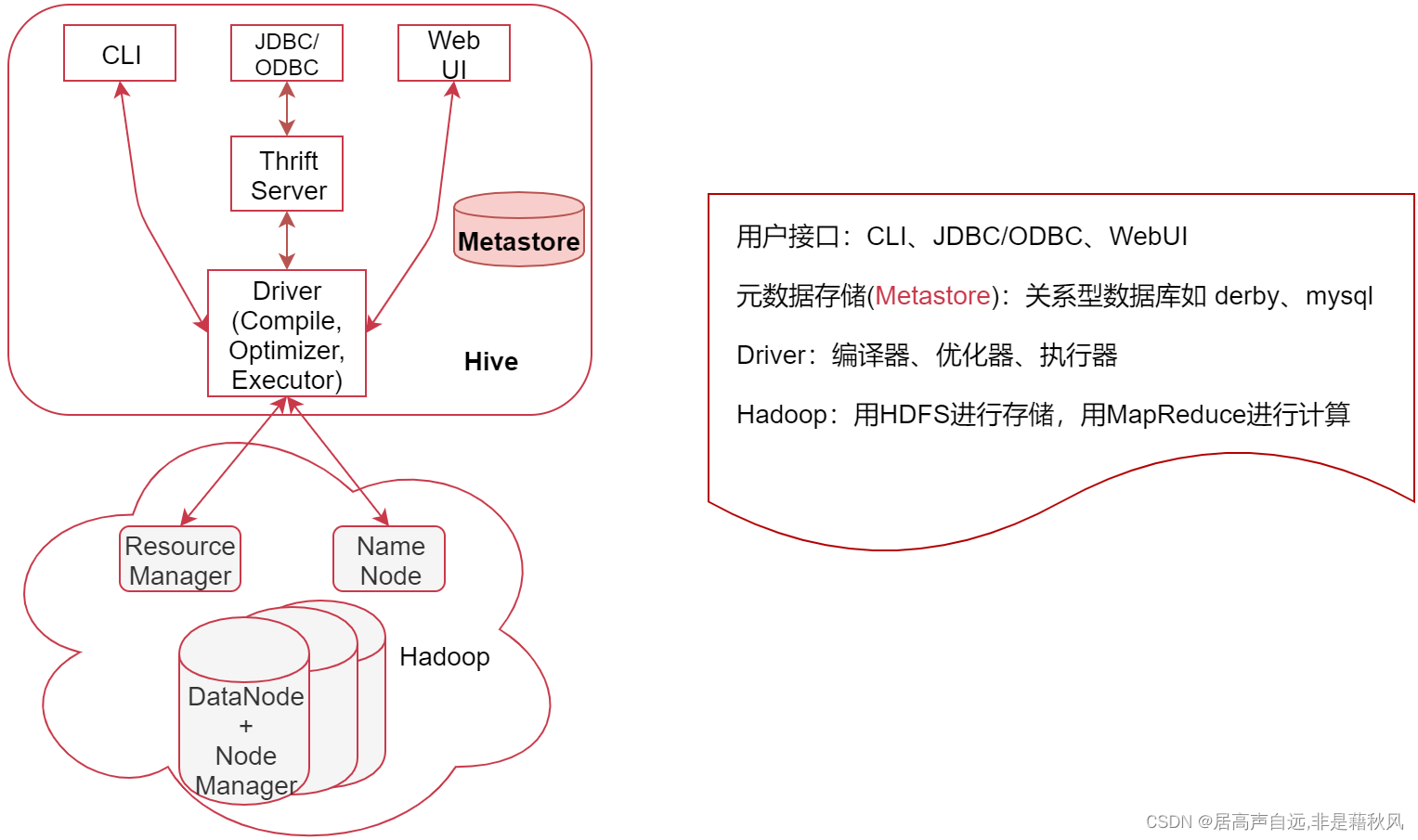
- 用户接口,包括 CLI、JDBC/ODBC、WebGUI
CLI,即Shell命令行,表示我们可以通过shell命令行操作Hive
JDBC/ODBC 是 Hive 的Java操作方式,与使用传统数据库JDBC的方式类似
WebUI是通过浏览器访问 Hive - 元数据存储(Metastore),注意:这里的存储是名词,Metastore表示是一个存储系统
Hive中的元数据包括表的相关信息,Hive会将这些元数据存储在Metastore中,目前Metastore只支持 mysql、derby。 - Driver:包含:编译器、优化器、执行器
编译器、优化器、执行器可以完成 Hive的 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划最终存储在 HDFS 中,并在随后由 MapReduce 调用执行 - Hadoop:Hive会使用 HDFS 进行存储,利用 MapReduce 进行计算
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(特例 select * from table 不会生成 MapRedcue 任务,如果在SQL语句后面再增加where过滤条件就会生成MapReduce任务了。
从hive2开始官方就不建议使用MapReduce作为数据引擎了,但是截至到hive3默认的数据引擎依然是MapReduce,只是建议数据引擎更换成spark或者是flink
四、Metastore
Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在的hdfs目录等
Metastore默认使用内嵌的derby数据库,Derby数据库的缺点:在同一个目录下一次只能打开一个会话
不建议使用默认的Derby,推荐使用MySQL作为外置存储引擎,可以支持多用户同时访问以及元数据共享。
五、Hive VS Mysql
HIVE MySQL
数据存储位置 HDFS 本地磁盘
数据格式 用户定义 系统决定
数据更新 不支持(不支持修改和删除) 支持(支持增删改查)
索引 有,但较弱,一般很少用 有,经常使用的
执行 MapReduce Executor
执行延迟 高 低
可扩展性 高 低
数据规模 大 小
六、数据库 VS 数据仓库
数据库:传统的关系型数据库(MySQL、Oracle)主要应用在基本的事务处理,数据库支持增删改查这些常见的操作,属于OLTP。
数据仓库:主要做一些复杂的分析操作,侧重决策支持,相对数据库而言,数据仓库分析的数据规模要大得多。但是数据仓库只支持查询操作,不支持修改和删除,属于OLAP。
七、OLTP VS OLAP
OLTP(On-Line Transaction Processing):操作型处理,称为联机事务处理,也可以称为面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性等问题
OLAP(On-Line Analytical Processing):分析型处理,称为联机分析处理,一般针对某些主题历史数据进行分析,支持管理决策。
八、hive的安装
略
九、hive的使用
启动命令
nohup hive --service metastore >> /export/servers/hive/log/metastore.log 2>&1 &
nohup hive --service hiveserver2 >> /export/servers/hive/log/hiveserver2.log 2>&1 &
bin/beeline -u jdbc:hive2://localhost:10000
十、Hive中数据库的操作
默认的存储位置是 /user/hive/warehouse
十一、Hive指定列和行的分隔符
默认的列分隔符是\001
默认的行的分隔符是\n
#指定分隔符
create external table stu
(
stu_id int,
stu_name string,
stu_birthday date,
online boolean
)row format delimited
fields terminated by '\t'
lines terminated by '\n'
;
十二、Hive的数据类型
- 一类是基本数据类型
数据类型 开始支持版本
TINYINT ~
SMALLINT ~
INT/INTEGER ~
BIGINT ~
FLOAT ~
DOUBLE ~
DECIMAL 0.11.0
TIMESTAMP 0.8.0
DATE 0.12.0
STRING ~
VARCHAR 0.12.0
CHAR 0.13.0
BOOLEAN ~
- 一类是复合数据类型
数据类型 开始支持版本 格式
ARRAY 0.14.0 ARRAY<data_type>
MAP 0.14.0 MAP<primitive_type, data_type>
STRUCT ~ STRUCT<col_name : data_type, ...>
1.array
适合场景:数组结构,适合存储不固定个数的字段。
创建array字段
#创建array字段的表
create table stu4(
stu_id int,
stu_name string,
stu_favors array<string>
) row format delimited
fields terminated by '\t'
#collection 要放在中间,放fields前面会报错
collection items terminated by ','
lines terminated by '\n';
#加载数据到测试表中
load data inpath '/test4/stu3.txt' into table test_db.stu4;
#使用角标的形式获取数据 角标从0开始
select stu_id,stu_favors[1] from test_db.stu4;
2.map
适合场景:某个字段包含多个key-value的键值对形式
#创建mapy字段的表
create table stu6(
stu_id int,
stu_name string,
stu_scores map<string,int>
) row format delimited
fields terminated by '\t'
#需要加两行,字段分割已经mapkey-value的分隔
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
#导入数据
load data inpath '/test4/stu6.txt' into table test_db.stu6;
#通过key进行查询
select stu_id,stu_scores['chinese'] from test_db.stu6;
3.struct
适合场景:储存一个对象数据
#创建structy字段的表
create table stu7(
stu_id int,
stu_name string,
stu_favors struct<first_favor:string,second_favor:string,three_favor:string>
) row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
load data inpath '/test4/stu3.txt' into table test_db.stu7;
#使用.属性的形式获取
select stu_id,stu_favors.three_favor from test_db.stu7;
4.map和struct的区别
Struct和Map的区别
如果从建表语句上来分析,其实这个Struct和Map还是有一些相似之处的
来总结一下:
map中可以随意增加k-v对的个数
struct中的k-v个数是固定的
map在建表语句中需要指定k-v的类型
struct在建表语句中需要指定好所有的属性名称和类型
map中通过[]取值
struct中通过.取值,类似java中的对象属性引用
map的源数据中需要带有k-v
struct的源数据中只需要有v即可
总体而言还是map比较灵活,但是会额外占用磁盘空间,因为他比struct多存储了数据的key
struct只需要存储value,比较节省空间,但是灵活性有限,后期无法动态增加k-v
十三、Hive中的表类型
内部表、外部表、分区表、桶表
1.内部表
默认的表类型,实际存储在warehouse目录下;
load加载数据的时候数据会移动到warehouse目录下;
删除数据的时候数据也会删除
一般不用这个类型的表
2.外部表
建表语句中包含external;
#建表语句
create external table student2
(
stu_id int,
stu_name string,
favors array<string>,
scores map<String,int>,
address struct<home_addr:string,office_addr:string>
)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n' location '/test4/external'
;
外部表删除不会将数据同时删除;
外部表可以直接读取它location下的文件内容无须load 打他 input加载;
日常更多的是先有数据进入到hdfs,然后根据目录创建hive表,不需要进行加载数据自动进入,同时删除不影响数据
几乎都是使用外部表
3.分区表
使用partitioned by指定区分字段
通过类型进行分区,查询的时候可以避免全表扫描;
创建表: partitioned by (dt string) location ‘/test4/external/partition’
数据落地:/test4/external/partition/dt=2022-01-03
加载分区数据: alter table partition_1 add partition (dt=‘2020-01-02’);
数据落地目录的时候规划好目录,建立外部分区表只需要加载分区即可载入数据
几乎都是使用外部表分区
4.分桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储
create table bucket_tb(
id int
) clustered by (id) into 4 buckets;
加载数据只能使用其他表的数据进行加载
insert into table … select … from …;
查询分桶的数据 select * from bucket_tb tablesample(bucket 1 out of 4 on id);
优势:1.适合抽样 2.适合join 两个分桶表相同的ID会分到同一桶中,所以效率会高
缺点:只能使用insert的形式新增
使用少
十四、Hive高级函数应用
1.行转列
COLLECT_SET() 、COLLECT_LIST() 可以将多行数据合并成一行数组,set是去重后的
CONCAT_WS() 可以将数据进行切分
2.列转行
SPLIT()、EXPLODE()和LATERAL VIEW
split切分成数组 EXPLODE可以将数组转成多行 LATERAL VIEW 如果需要加入其它字段需要使用到这个
select name,favor_new from student_favors_2 lateral view explode(split(favorlist, ‘,’)) table1 as favor_new ;
十四、Hive排序相关函数
1.ORDER BY
全局排序
2.SORT BY
set mapreduce.job.reduces = 2;
reduce端进行排序,局部有序
3.DISTRIBUTE BY
分区排序,结合sort by 使用;类似通过名称分区然后分数排序
4.CLUSTER BY
cluster by id 等于 distribute by id sort by id 但是只能升序
十五、数据倾斜处理
#可以对明确知道数据量大的值打散后再进行处理
select owner_id,sum(cut) from (
select owner_id, count(1) cut
from ods_zjzb_object_h3d5 group by owner_id,case when owner_id='617256440bbe2f7f1ee00f61' then hash(rand())%5 else 0 end
) a group by owner_id;
十六、数据压缩格式
默认的格式是textfile格式。
这种格式的数据在存储层面占用的空间比较大,影响存储能力,也影响计算效率
1.mapreduce中常见的压缩格式
DEFLATE 底层是zlib
Gzip DEFLATE的封装
Bzip2
Lz4
Lzo
Snappy
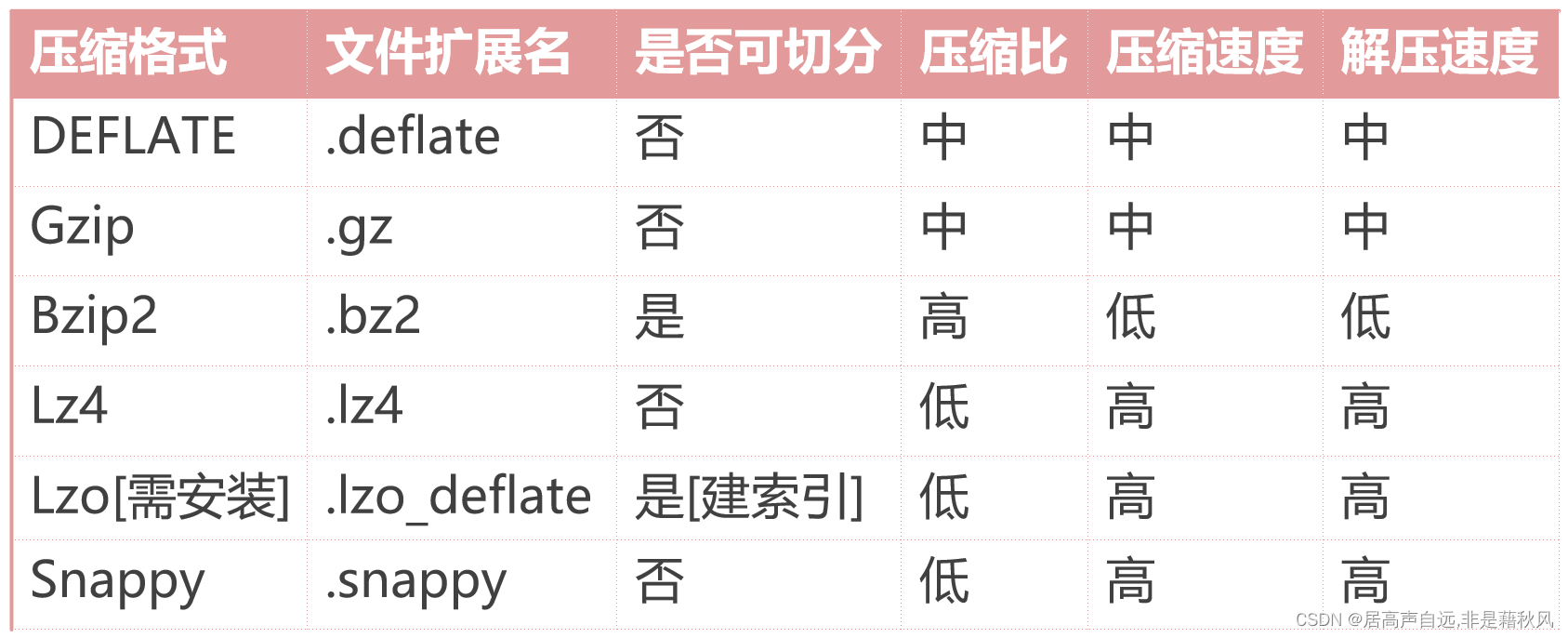
是否可以切分:针对textfile文件来说,如果是否,无论文件多大只能是一个map任务进行处理。对于特殊的文件格式,还是可以实现切分的;这是文件自身决定的,和压缩格式没有关系。非常重要
压缩比:压缩比越高,文件越小
总结 Snappy综合的性能比较高,应用广。
2.数据存储格式
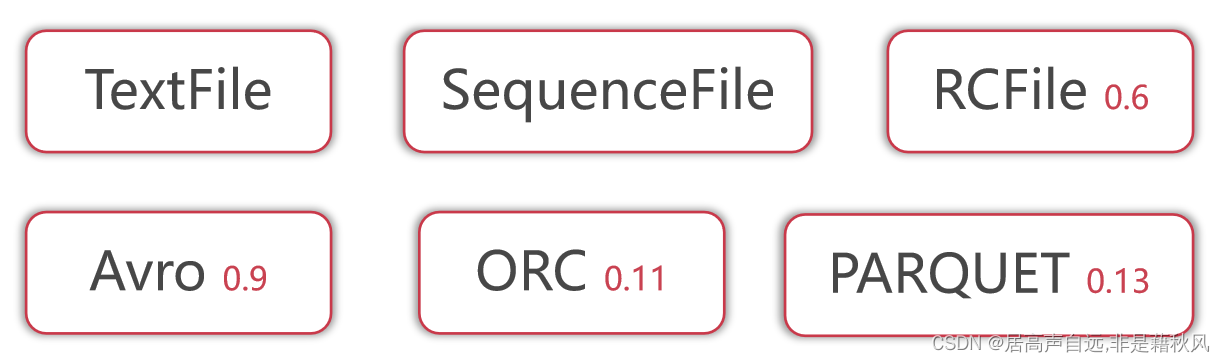
工作中使用最多是TextFile、ORC和Parquet
默认情况下使用TextFile即可,想要提高数据存储和计算效率,可以考虑使用ORC或者Parquet。
3.数据存储格式之ORC
建表语句
create external table stu_orc_snappy_compress(
id int,
name string,
city string
)row format delimited
fields terminated by ‘,’
lines terminated by ‘\n’
stored as orc
location ‘hdfs://bigdata01:9000/stu_orc_snappy_compress’
tblproperties(“orc.compress”=“SNAPPY”);
在创建ORC数据存储格式表的时候,所有关于ORC的参数都在建表语句中的tblproperties中指定,不需要在hive的命令行中使用set命令指定了。
ORC支持的参数主要包括这些:

4.数据存储格式之PARQUET
create external table stu_parquet_snappy_compress(
id int,
name string,
city string
)row format delimited
fields terminated by ‘,’
lines terminated by ‘\n’
stored as parquet
location ‘hdfs://bigdata01:9000/stu_parquet_snappy_compress’
tblproperties(“parquet.compression”=“snappy”);
5.数据存储格式总结
所以最终建议,在工作中选择ORC+Snappy。
但是有时候在选择数据存储格式的时候还需要考虑它的兼容度,是否支持多种计算引擎。
假设我希望这一份数据,既可以在Hive中使用,还希望在Impala中使用,这个时候就需要重点考虑这个数据格式是否能满足多平台同时使用。
Impala很早就开始支持Parquet数据格式了,但是不支持ORC数据格式,不过从Impala 3.x版本开始也支持ORC了。
如果你们使用的是Impala2.x版本,还想要支持Hive和Impala查询同一份数据,这个时候就需要选择Parquet了。
相对来说,Parquet存储格式在大数据生态圈中的兼容度是最高的。
Parquet官网上有一句话,说的是Parquet可以应用于Hadoop生态圈中的任何项目中。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











