







大数据之路系列之mapreduce核心理论(04)
提示:包含yarn
mapreduce核心理论
一、MapReduce是什么?
MapReduce是分布式计算框架,map进行局部计算,reduce对局部数据进行汇总。
二、数据iO
磁盘io
网络io(更容易导致延迟)
三、计算方式
移动计算(MapReduce使用这个方式)
移动数据
四、核心内容
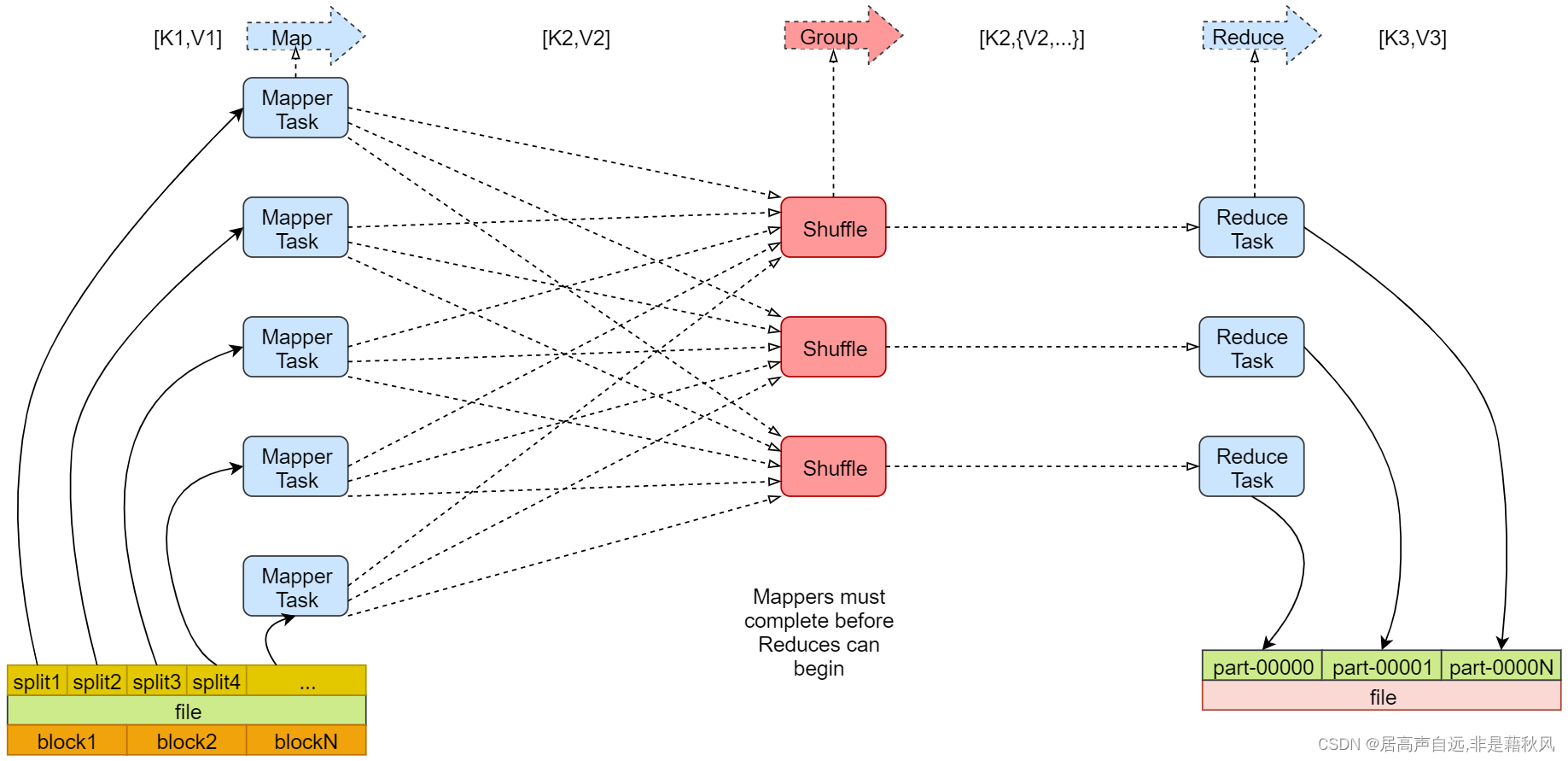
1.map阶段
block文件在hdfs上的物理划分,split是文件的逻辑划分,默认两者都是128M。所以spilit数量=block数量=map任务数量。等式的前提是block的大小没有被改变。
2.reduce阶段
几个reduce任务就会产生几个文件。
3.Shuffle阶段
shuffer是一个网络拷贝的过程,是指通过网络把数据从map端拷贝到reduce端的过程。将不同map任务中的相同分区数据拷贝到统一reduce中。
4.序列化机制
Java原本的序列化会将父类超类都进行序列化,比较大。Hadoop自己实现了一套数据类型。
Java类型 Writable 序列化大小(字节)
布尔型(boolean) BooleanWritable 1
字节型(byte) ByteWritable 1
整型(int) IntWritable 4
VIntWritable 1~5
浮点型(float) FloatWritable 4
长整型(long) LongWritable 8
VLongWritable 1~9
双精度浮点型(double) DoubleWritable 8
String TEXT
null NullWritable
5.小文件问题
SequenceFile 和 MapFile;SequenceFile 是一种二进制文件,缺点是文件比较大,查看不方便。就是相当于小文件压缩成压缩包了。
mapfile:两部分组成index和data,index保存索引,检索能力强,但是需要一部分内存来存储index。
6.数据倾斜问题
问题:一个或者几个reduce的任务时间过长,耽误整个计算进度。
解决方式:1.增加reduce个数2.将倾斜的数据打散。
五、YARN详解
yarn负责资源的管理和调度;
ResourceManager:是主节点,主要负责集群资源的分配和管理
NodeManager:是从节点,主要负责当前机器资源管理
六、YARN中的调度器
YARN中支持三种调度器
1:FIFO Scheduler:先进先出(first in, first out)调度策略
2:Capacity Scheduler:FIFO Scheduler的多队列版本
3:FairScheduler:多队列,多用户共享资源
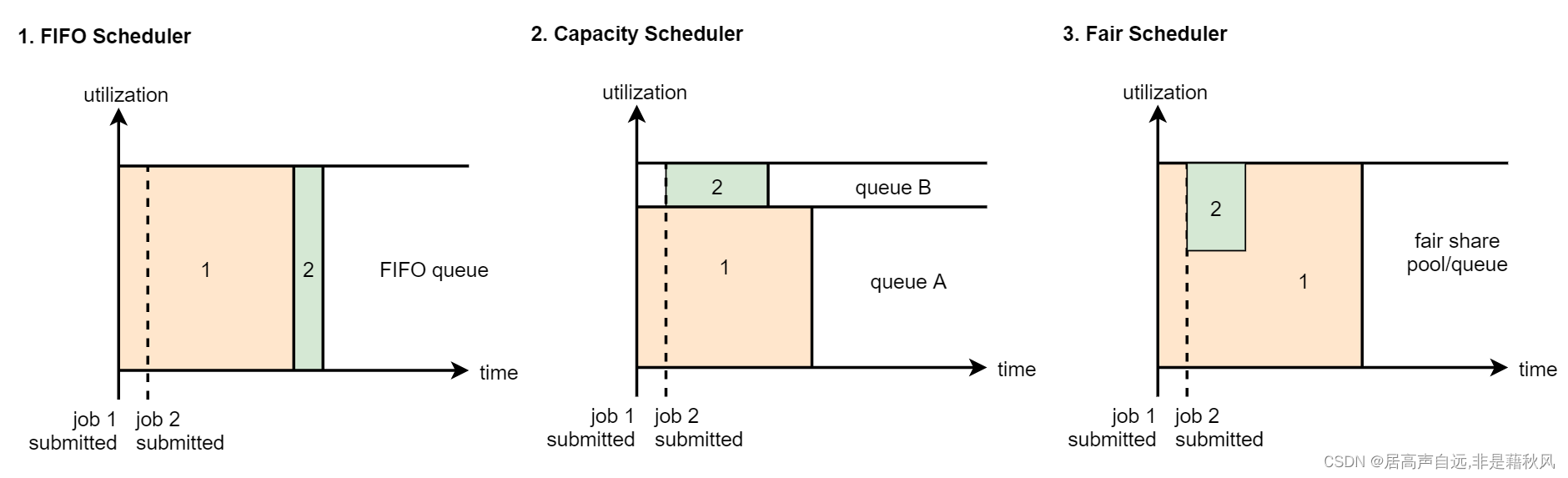
FIFO Scheduler:是先进先出的,大家都是排队的,如果你的任务申请不到足够的资源,那你就等着,等前面的任务执行结束释放了资源之后你再执行。这种在有些时候是不合理的,因为我们有一些任务的优先级比较高,我们希望任务提交上去立刻就开始执行,这个就实现不了了。
CapacityScheduler:它是FifoScheduler的多队列版本,就是我们先把集群中的整块资源划分成多份,我们可以人为的给这些资源定义使用场景,例如图里面的queue A里面运行普通的任务,queueB中运行优先级比较高的任务。这两个队列的资源是相互对立的。Hadoop2起默认使用这个,推荐使用这个。
但是注意一点,队列内部还是按照先进先出的规则。
FairScheduler:支持多个队列,每个队列可以配置一定的资源,每个队列中的任务共享其所在队列的所有资源,不需要排队等待资源
具体是这样的,假设我们向一个队列中提交了一个任务,这个任务刚开始会占用整个队列的资源,当你再提交第二个任务的时候,第一个任务会把他的资源释放出来一部分给第二个任务使用
七、YARN杀进程
yarn地址:http://node01:8088
yarn application -kill application_1587713567839_0003
总结
脑图:https://naotu.baidu.com/file/bfa6ed8ca220aa5c2f1307655797306b?token=2d80ab5931824fa4



















 8662
8662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











