







一、 Combiner合并器
概念:
键ReduceTask需要做的汇总计算的任务,让MapTask端先执行一遍
作用:
例如:你是个幼儿园园长,现在要统计幼儿园中来自各个城市的小朋友各多少人,在以前就是每个班主任给你一份名单:张三:北京、李四上海、小明:北京、小红:北京…。然后你拿到了全院每一个学生的地址,然后在把全院的学生再过一遍,一个一个统计北京的有张三、小红、小明,上海的有李四…
那么想一个问题:既然你各个班的班主任都统计每个学生的信息了。那院长想要的是各个城市的学生的个数,你们每个班主任在统计的时候统计完给我 :北京:105人、上海:90人。。。院长拿到一班、二班、三班的信息 只用做个加法把各个地方的人数 加一下就得到了最终结果,是不是院长就轻松了许多呢。
院长就像是ReduceTask,各个班主任就是MapTask。班主任最终生成的结果如果只是(北京:105人、上海:90人。。。。)这样的文件大小一定要比张三:(北京、李四上海、小明:北京、小红:北京…)这样的小了很多,减少了文件 大小提高传输到ReduceTask的效率,又可以提高ReduceTask的工作效率,这就是Combiner合并器的作用
实现:
只用在 public int run(String[] strings) throws Exception {}中加入如下代码即可:
job.setCombinerClass(XxxReducerClass.class);
应用场景:
提前在MapTask进行汇总计算,减少ReduceTask的计算压力,可以减少MapTask生成结果的文件大小。适用于求和计算,不适用于平均值等工作
二、ReduceTask并行度
引入:
在之前做数据清洗的时候在run方法中设置了这样一行代码:
job.setNumReduceTasks( 0)
作用是设置ReduceTasks的个数为0,而一般我们不设置的时候他的默认值是1个 ,也可以自定义他的个数为多个
概念:
Reduce阶段ReduceTask程序可以设置多个。
ReduceTask的默认并行度是1,如果设置为0,代表没有汇总操作,多用于数据清洗
ReduceTask的默认并行度 > 1 ,目的是为了减少一个ReduceTask的并行度的压力。
特点 :
提高Reduce 端的程序个数,并行执行,提高执行 速度
每个ReduceTask生成一个对应的文件
实现:
在run方法中添加如下代码:
job.setNumReduceTasks(reduce数量);
详解:
在run方法中 加入了如上代码后底层会干什么事是 需要了解清楚地。
首先先看一下在不加这个代码 的时候执行流程是怎样的:
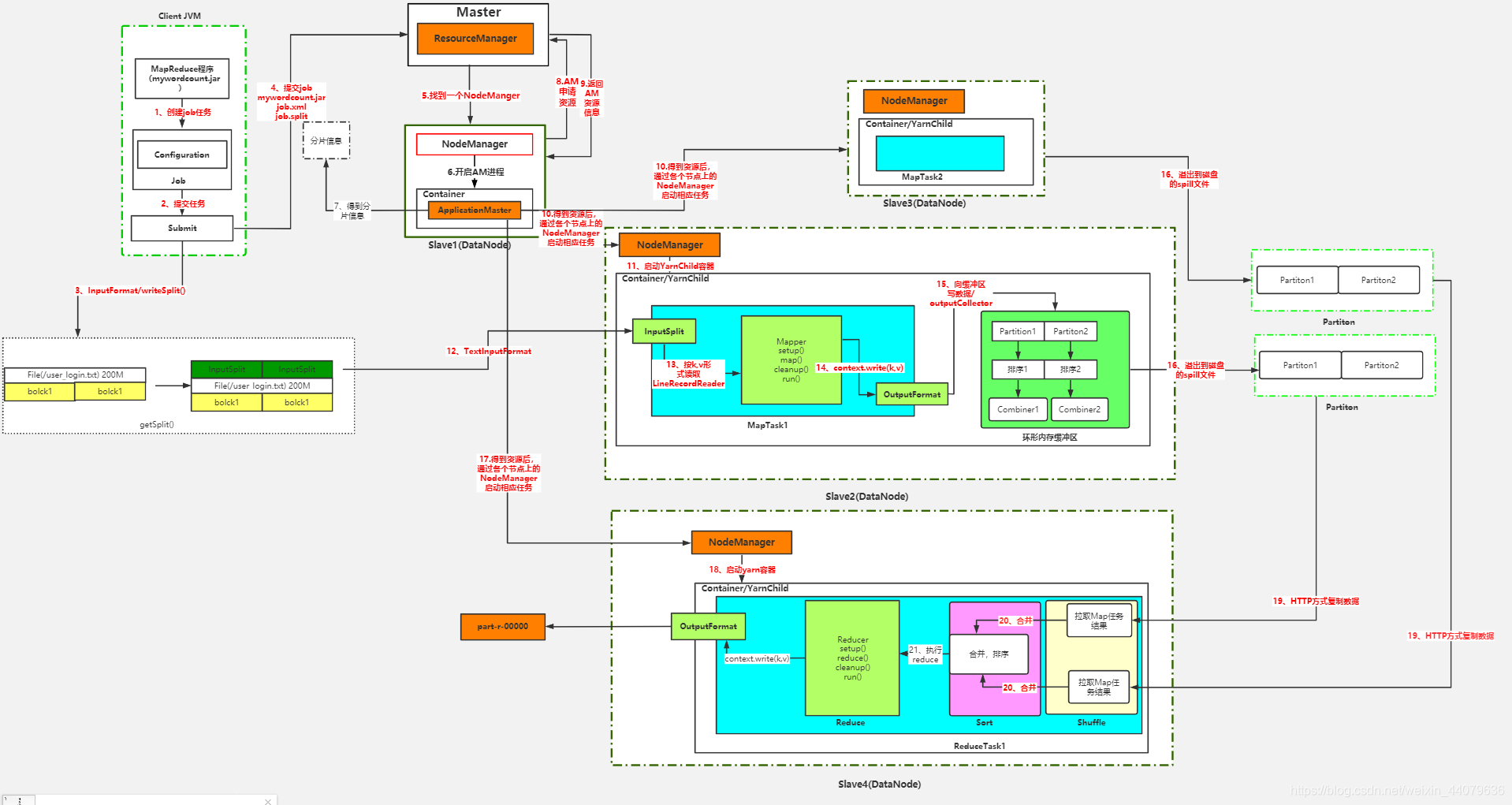
简单看一下在之前的流程中在MapTask会生成一个对应的文件,然后将多个局部计算的结果给reduce Task 汇总计算:
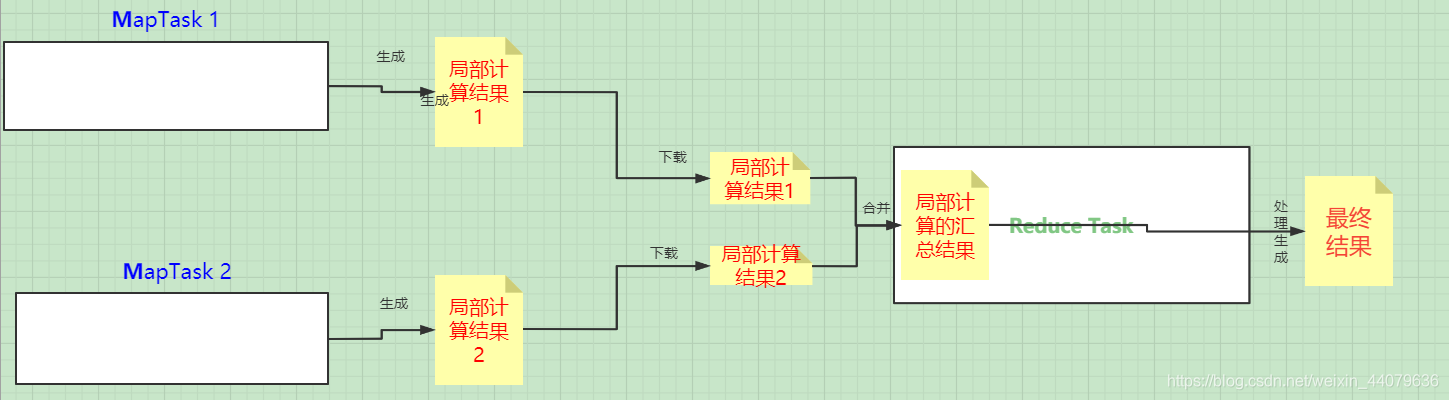
然后再看一下加入该行代码之后会做些什么:
- reduce的 个数 变为两个
- MapTask 执行完毕后会生成两个文件
- 如果是数字,并且reduce个数为两个的话一个会按照key分组,一个文件中存奇数一个存偶数
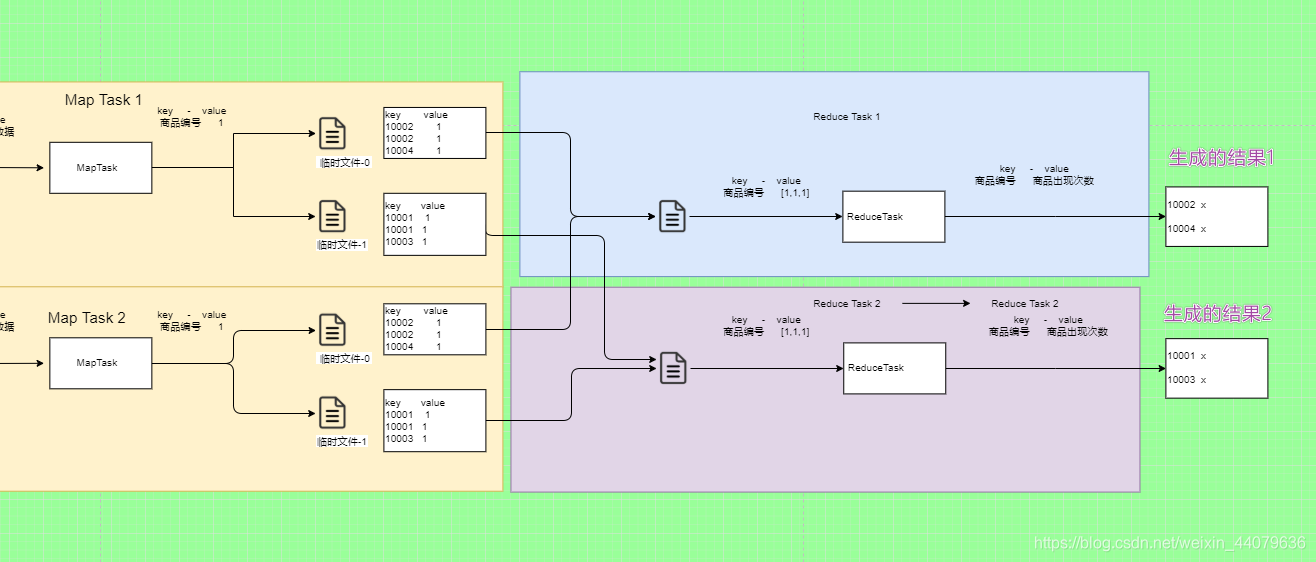
三、MapReduce的分区 (Partition)
引入:
从上图可以看出,每个MapTask生成的两个文件需要按照规定,都把生成的奇数文件交给ReduceTask1处理,把偶数都交给ReduceTask2处理。当然了这是在ReduceTask的个数为2的时候的情况,那么如果我们设置为4.为5或者其他呢,如果我们的key不是数字呢,如果是一个对象那这些MapTask声生成的4、5个文件该分给哪个ReduceTask呢。首先我们弄清楚2个的时候他底层是怎么分的:
概念:
在执行MR程序时我们可能想要将不同的数据放到不同的文件中。 partition是在map阶段完成后执行的。然后将分好区的数据传输到reduce端,也就是由Partitioner来决定每条记录应该送往哪个reducer节点。mapreduce中默认的分区是HashPartition类;
原理
就是说默认不写的话他会在run方法中 有这么一句话:
job.setPartitionerClass(HashPartitioner.class);
点进去这个HashPartitioner后可以看到:
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.classification.InterfaceAudience.Public;
import org.apache.hadoop.classification.InterfaceStability.Stable;
import org.apache.hadoop.mapreduce.Partitioner;
@Public
@Stable
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public HashPartitioner() {
}
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
}
}
在这个getPartition方法中只有这一行 代码,这行代码干了什么事:
- 获取Key的哈希值
- key.hashCode() & 2147483647:实际上就是获取Key的哈希值,有可能是负数,所以做了一个位运算,保证 这个值是正数
- 使用key的哈希值对reduce任务数(numReduceTasks)求模
- 目的是可以把(key,value)对,均匀的分发到各个对应编号的reducetask节点上,达到reducetask节点的负载均衡。
在了解了他的原理之后,就可以对他随意的操作了。
自定义分区:
只需要继承抽象类Partitioner,重写getPartition方法即可,
另外还要给任务设置分区: job.setPartitionerClass(),就可以了。
1.自定义一个类Mypart,在类中自定义分区规则,他是 会根据 返回值来 判断自己要交给哪个ReduceTask处理的:
package demo10;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPart extends Partitioner{
public int getPartition(Object key, Object value, int num) {
Student stu=(Student) key;
int result = 0;
if("语文".equals(stu.getKemu())){
result = 0;
}else if("数学".equals(stu.getKemu())){
result = 1;
}else if("英语".equals(stu.getKemu())){
result = 2;
}else{
result = 3;
}
return result;
}
}
2.自定义一个类实现序列化和自定义排序规则:
package demo10;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Student implements WritableComparable<Student> {
private String Kemu;
private String name;
private int score;
//无参构造方法
public Student() {
}
//自定义排序规则为倒叙
public int compareTo(Student o) {
return o.score-this.score;
}
//实现这两个方法,注意顺序要一致
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(Kemu);
dataOutput.writeUTF(name);
dataOutput.writeInt(score);
}
public void readFields(DataInput dataInput) throws IOException {
Kemu=dataInput.readUTF();
name=dataInput.readUTF();
score=dataInput.readInt();
}
//toString方法
@Override
public String toString() {
return name+"\t"+Kemu+"\t"+score;
}
//生成getset方法
public Student(String kemu, String name, int score) {
Kemu = kemu;
this.name = name;
this.score = score;
}
public String getKemu() {
return Kemu;
}
public void setKemu(String kemu) {
Kemu = kemu;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
}
3.分组的概念
job.setGroupingComparatorClass(xxx.class);
底层 会默认调用自定义的类重写的CompareTo方法进行分组
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
}
如果两条数据的字一样在分组的时候就会重合成一条数据,所以这里了需要处理一下。自定义一个类extends WritableComparator 。重写compare方法,使用自定义分组,就不会把两条数据当成 一条数据处理了
package demo10;
import org.apache.hadoop.io.WritableComparator;
public class MyGroupComparator extends WritableComparator {
public MyGroupComparator() {
super(Student.class,true);
}
@Override
public int compare(Object a, Object b) {
Student s1 = (Student) a;
Student s2 = (Student) b;
return s1.getName().compareTo(s2.getName()); //设置分组依据
}
}
在主方法中使用我们的自定义分组规则的类:
job.setGroupingComparatorClass(MyGroupComparator.class);
3.然后写自己的主方法

package demo10;
import demo.WordCountJob;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class ParttionerJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new ParttionerJob(),args);
}
public int run(String[] strings) throws Exception {
//1.创建配置类对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://hadoop10:9000");
//2.创建Job对象
Job job = Job.getInstance(conf);
job.setJarByClass(ParttionerJob.class);//调用这个方法会在执行主方法的时候使用配置文件去执行
//3.设置要读取和输出的方式和路径
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job,new Path("/mapreduce/demo10/definePartition.txt"));
//这个文件就是我们要计算的文件。目录路径写成hdfs文件系统的路径在测试前我们需要写一个这样的文件并上传到hdfs的根目录下
FileOutputFormat.setOutputPath(job,new Path("/mapreduce/demo10/out"));
//这个路径是我们最终的计算结果需要放在那里的路径。也是在hdfs上的路径。注意点:这个路径在执行前不能存在。
// 如果存在会报错,(因为目录存在的话它可能以为我以前是不是做过这个计算了)
//4.设置Mapper和Reduce
job.setMapperClass(partitionerMapper.class);
job.setReducerClass(partitionerReduce.class);
//这里的两个类就是下面写的静态内部类
//5.设置map和reddduce输出的kv类型
job.setMapOutputKeyClass(Student.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Student.class);
job.setOutputValueClass(NullWritable.class);
job.setPartitionerClass(MyPart.class);
job.setNumReduceTasks(4);
job.setGroupingComparatorClass(MyGroupComparator.class);
//6.提交任务,并且等待执行结果然后返回一个值
boolean b = job.waitForCompletion(true);
//首先这个方法的返回值是布尔类型的true或者false表示程序执行完后成功没哟。
// 里面的这个参数代表的是是否要打印日志信息。
return b?1:0;//这里使用三目运算符。如果执行成功就返回一个1,执行失败就返回一个0
}
static class partitionerMapper extends Mapper<LongWritable, Text,Student, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] arr=value.toString().split("\t");
context.write(new Student(arr[1],arr[0],Integer.parseInt(arr[2])),NullWritable.get());
}
}
static class partitionerReduce extends Reducer<Student,NullWritable,Student,NullWritable>{
@Override
protected void reduce(Student key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
}
4。最后运行的结果中就会有4个文件:
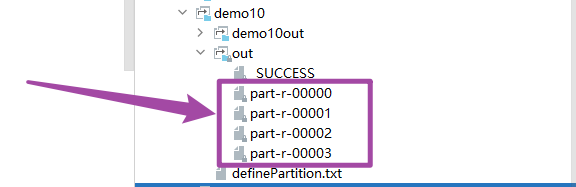
partition分区注意点:
如果reduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
如果1<reduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
如果reduceTask的数量=1,则不管mapTask端输出多少个分区文件,最终结果都交给这一个reduceTask,( 最终也就只会产生一个结果文件 part-r-00000;但是分区part-1的结果不知道要不要放进part-0文件中,最终会产生紊乱;
四:Top-N演示
需求:
获取观众人数排前三的主播和人数
源文件:
团团 2345 1000
小黑 67123 2000
哦吼 3456 7000
卢本伟 912345 6000
八戒 1234 5000
悟空 456 4000
唐僧 123345 3000
Job结果:
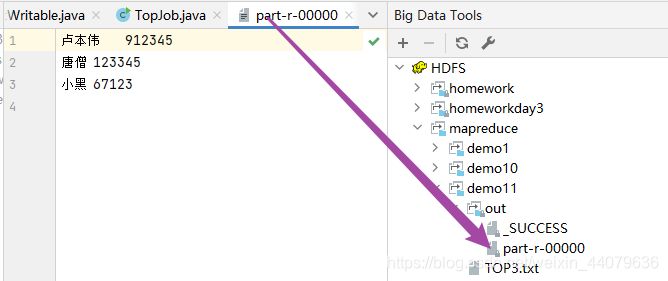
卢本伟 912345
唐僧 123345
小黑 67123
思路1:
不适用任何其他技术,让MapTask生成的结果都给ReduceTask来处理。
1. 按照观众人数,降序排序。
2. reduce端输出前3个。
在大数据量的情况下,就像最开始的幼儿园院长需要自己把几十万个学生一个一个过一遍,最后排出前三名。(直接不使用这种方法)
思路2:
1.每个MapTask只将自己计算出的前三名交给ReduceTask处理,因为其他的到了RduceTask中在自己局部计算都不是前三到那里肯定也不是前三就不去献丑了
2.ReduceTask只处理多个局部计算出来的前三名,做个汇总输出前三数据即可
这里使用思路二实现:
面临的问题:
- 如何让MapTask中排序完之后只取前三名输出
- ReduceTask在计算之前需要执行两步1.是下载局部计算的结果文件。2.是 merge合并(key排序、key分组、相同key的value放数组)3.计算的时候只输出前三个
1.首先先解决reduce的计算代码,这个比较简单,只用定义一个变量,然后再输出的时候判断这个变量是不是小于三,如果小于三就输出,否则就直接return退出对XXXReduce的调用,(这里不使用break,break只能退出当前循环,不能 退出reduce的调用)
static class topReduce extends Reducer<DescIntWritable,Text,DescIntWritable,Text>{
int targ=0;
@Override
protected void reduce(DescIntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for(Text s:values){
if(targ<3){
context.write(key,s);
targ++;
}
return;
}
}
}
2.解决MapTask中排序完之后只取前三名输出的方法,
- 只输出前三名 可以借鉴上面的思路,定义一个变量,只要小于三就可以输出,大于三就不让输出了。
- 因为排序的话首先是他的底层是使用key进行排序的,所以我们只能吧人数当做key,其次是需要倒叙排列,我们这里可以写一个类实现compareTo方法即可。
public int compareTo(DescIntWritable o) {
return o.num-this.num;
}
- 我们知道自动排序这个过程是在汇总计算ReduceTask的时候才会执行的,那么我们现在在MapTask中也想对数据进行排序那怎么 办呢。首先我们想到MapTask过程中使用的是键值对存储,那么在Map的知识点中有一个叫做TreeMap 的Map他可以自动对map的key进行排序。那我们就可以在方法外面 定义一个treemap,然后调用put方法随着循环往里面添加键值对,因为是自动排序的那么最后一个元素就是当前map中最少的就可以使用remove方法和laskey结合再加上没有四个元素了就删除最后一个不符合条件的就可以达到最终只保留三个符合要求的key是最大的数据了:
TreeMap<DescIntWritable,String> map=new TreeMap();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] arr = value.toString().split("\t");
map.put(new DescIntWritable(Integer.parseInt(arr[1])),arr[0]);
if(map.size()>3){
map.remove(map.lastKey());
}
}
- 解决了上面这个问题之后在想一下,我们的MapTask最终是要输出一个文件 的,那我们的context.write()写在哪呢?首先不能写到上面的这个map方法中吧,我们知道他的工作机制是没每去读取一个行数据就会调用一次map方法,如果写在里面的话会每一次都执行一次输出就不是跟我们预想的一样了。这时候我们看一下我们的这个map方法是在自定义的topmap方法中的,他继承了Mapper,并从重写了map方法,那我们点进去这个Mapper看看他的源码是怎样的,点开之后我们可以看到这样一个方法:
@Public
@Stable
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Mapper() {
}
protected void setup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
context.write(key, value);
}
protected void cleanup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
this.setup(context);
try {
while(context.nextKeyValue()) {
this.map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
this.cleanup(context);
}
}
public abstract class Context implements MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Context() {
}
}
}
其中声明了类Context,传递了四个泛型,分别是输入的key类型、输入的value类型、输出的key类型、输出的value类型。
定义了四个方法:
setup:定义Map的启动工作,比如读入一些配置、进行一些变量的初始化等
map:定义实际的mapper阶段功能,比如数据读入、处理、打标签、分发等
cleanup:定义mapper阶段之后收尾工作,比如多路输出等。
run:实际执行程序的方法,先调用setup完成启动工作,然后调用map完成实际的mapper阶段功能,在所有map工作都完成之后,调用cleanup完成收尾工作。
对于每个maptask和reducetask来说,都是先调用run()方法,因此根据源代码中run()方法的结构可以看出,不管是map任务还是reduce任务,程序都要经过如下几个阶段:调用run()方法–>调用setup(context)方法–>循环执行map()或reduce()方法–>最后调用cleanup(context)方法。
其中setup方法和cleanup方法默认是不做任何操作,且它们只被执行一次。但是setup方法一般会在map函数之前执行一些准备工作,如作业的一些配置信息等;cleanup方法则是在map方法运行完之后最后执行 的,该方法是完成一些结尾清理的工作,如:资源释放等。如果需要做一些配置和清理的工作,需要在Mapper/Reducer的子类中进行重写来实现相应的功能。map方法会在对应的子类中重新实现,就是我们自定义的map方法。该方法在一个while循环里面,表明该方法是执行很多次的。run方法就是每个maptask调用的方法。
所以我们就在重写这个cleanup方法,只在最后执行一次,这时候我们的treemap已经计算了本MapTask中最多的三条数据了,只用在最后输出一次即可:
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Set<Map.Entry<DescIntWritable,String>> set = map.entrySet();
for(Map.Entry<DescIntWritable,String> entry:set){
context.write(entry.getKey(),new Text(entry.getValue()));
}
}
实现:
最终来看一下实现代码:
1.倒叙排列的自定义类DescIntWritable
package demo11;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.yarn.webapp.hamlet.Hamlet;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class DescIntWritable implements WritableComparable<DescIntWritable> {
private int num;
public DescIntWritable() {
}
public DescIntWritable(int num) {
this.num = num;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
public int compareTo(DescIntWritable o) {
return o.num-this.num;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(num);
}
public void readFields(DataInput dataInput) throws IOException {
num=dataInput.readInt();
}
@Override
public String toString() {
return Integer.toString(num);
}
}
2.MapReduce的主方法类:
package demo11;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class TopJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new TopJob(),args);
}
public int run(String[] strings) throws Exception {
//1.创建配置类对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://hadoop10:9000");
//2.创建Job对象
Job job = Job.getInstance(conf);
job.setJarByClass(TopJob.class);
//3.设置要读取和输出的方式和路径
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//1.方式1:设置要读取的文件
FileInputFormat.addInputPath(job,new Path("/mapreduce/demo11/TOP3.txt"));
FileOutputFormat.setOutputPath(job,new Path("/mapreduce/demo11/out")); // out是文件夹,并且不能存在
//4.设置Mapper和Reducer
job.setMapperClass(topMapper.class);
job.setReducerClass(topReduce.class);
//5.设置Mapper和Reducer输出的key-value类型
job.setMapOutputKeyClass(DescIntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DescIntWritable.class);
//job.waitForCompletion 提交作业,并且等到作业执行结束,作业执行结束之后,返回true代表执行成功
//run方法的返回值是int,如果是1代表成功,如果是0代表失败
return job.waitForCompletion(true)?1:0;
}
static class topMapper extends Mapper<LongWritable, Text,DescIntWritable,Text>{
TreeMap<DescIntWritable,String> map=new TreeMap();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] arr = value.toString().split("\t");
map.put(new DescIntWritable(Integer.parseInt(arr[1])),arr[0]);
if(map.size()>3){
map.remove(map.lastKey());
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Set<Map.Entry<DescIntWritable,String>> set = map.entrySet();
for(Map.Entry<DescIntWritable,String> entry:set){
context.write(entry.getKey(),new Text(entry.getValue()));
}
}
}
static class topReduce extends Reducer<DescIntWritable,Text,Text,DescIntWritable>{
int i = 0;
@Override
protected void reduce(DescIntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for(Text name:values){
if(i < 3){
context.write(name,key);
i++;
}else{
return;
}
}
}
}
}
3.看一下运行结果
OVER


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









