







 本文介绍了哈希算法、一致性哈希、带有限负载一致性哈希、虚拟节点一致性哈希以及虚拟槽分区这五种算法,着重讨论了它们在解决数据分布、扩展性和性能差异等问题上的应用和优缺点。
本文介绍了哈希算法、一致性哈希、带有限负载一致性哈希、虚拟节点一致性哈希以及虚拟槽分区这五种算法,着重讨论了它们在解决数据分布、扩展性和性能差异等问题上的应用和优缺点。
一共有五种算法,分别为:哈希算法、一致性哈希算法、带有限负载的一致性哈希算法、虚拟节点一致性哈希算法、虚拟槽分区
哈希算法
思想:根据某个key的值或者key 的哈希值与当前可用的 master 节点数取模,根据取模的值获取具体的服务器
缺点:扩展性非常差。万一某个节点宕机,就需要重新计算
一致性哈希算法
目的:为了解决哈希算法可扩展性差的问题
思想:数据映射到哈希环上后按照顺时针的方向查找存储节点,即从数据映射在环上的位置开始,顺时针方向找到的第一个存储节点,那么他就存储在这个节点上
图解:
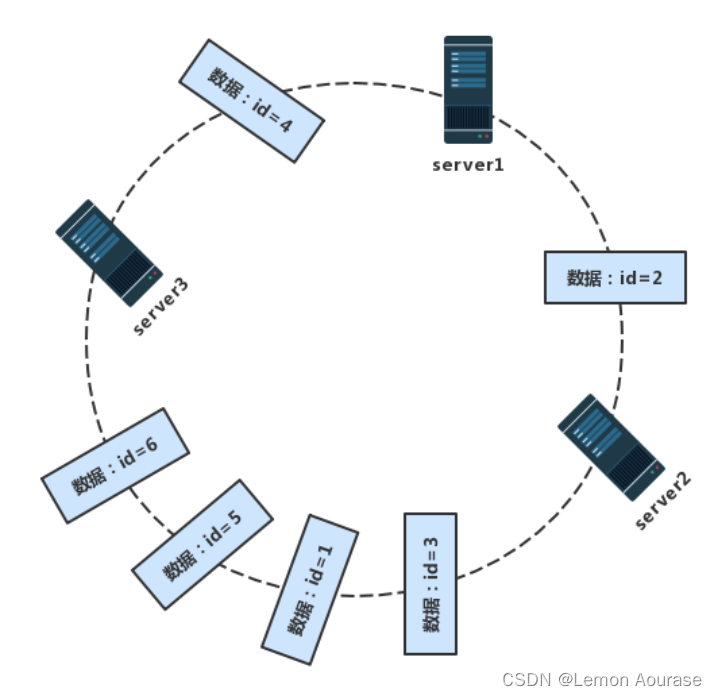
上图所示:id=2会存储在server2,id=3,1,5,6会存储在server3,id=4会存储在server1
缺点:会出现数据分布不均匀的问题,也就是数据倾斜的问题。但是在一定程度上可扩展性更强
带有限负载的一致性哈希算法
目的:为了解决数据倾斜的问题
思想:给每个存储节点设置一个存储上限值来控制存储节点添加或移除造成的数据不均匀,当数据按照一致性哈希算法找到相应的存储节点时,要先判断该存储节点是否达到了存储上限;如果已经达到了上限,则需要继续寻找该存储节点顺时针方向之后的节点进行存储
图解:
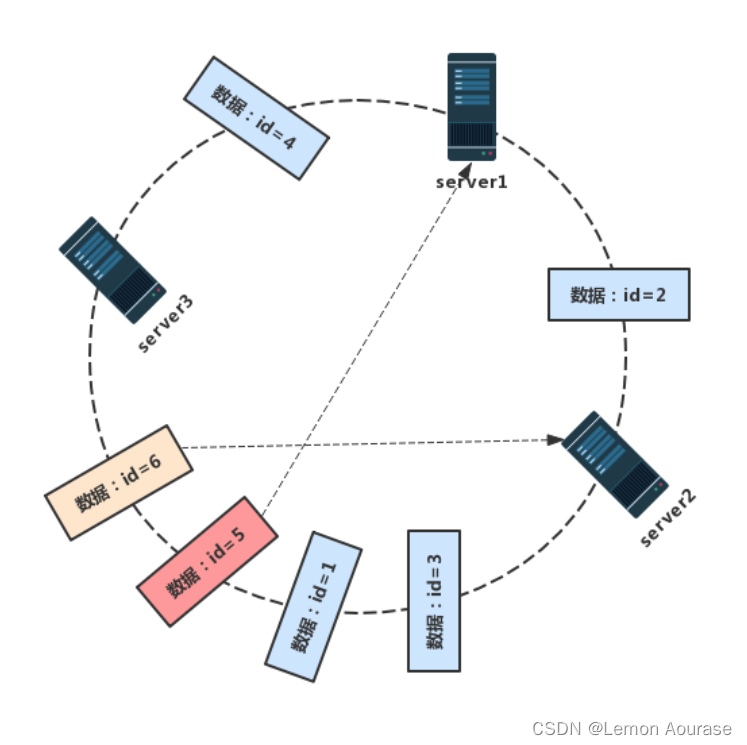
我们的添加顺序按照 id 大小排序,所以前四个数据(1,2,3,4)都没有问题,这时候的服务器都没有超过最高负载数量。
id=5 的数据落在了服务器 server2 和服务器 server3 之间,本应该是存储在服务器server3 上,但是由于此时的服务器 server3 上已经存储了 id=1、id=3 的数据,达到了最高限定,因此 id=5 的数据会沿着顺时针的方向继续往下寻找服务器。下一个服务器就是 server1,此时的服务器 server1 只存储了 id=4 的数据,并没有达到上限,所以 id=5 的数据就会存储在服务器 server1。id=6 的数据同样的道理,存储在server2上面。
虚拟节点一致性哈希算法
目的:带有限负载的一致性哈希算法存在一个服务器之间异构性(每台服务器的性能配置可能存在不一样)的问题
思想:根据每个节点的性能为每个节点划分不同数量的虚拟节点,并将这些虚拟节点映射到哈希环中,然后再按照一致性哈希算法进行数据映射和存储
图解:
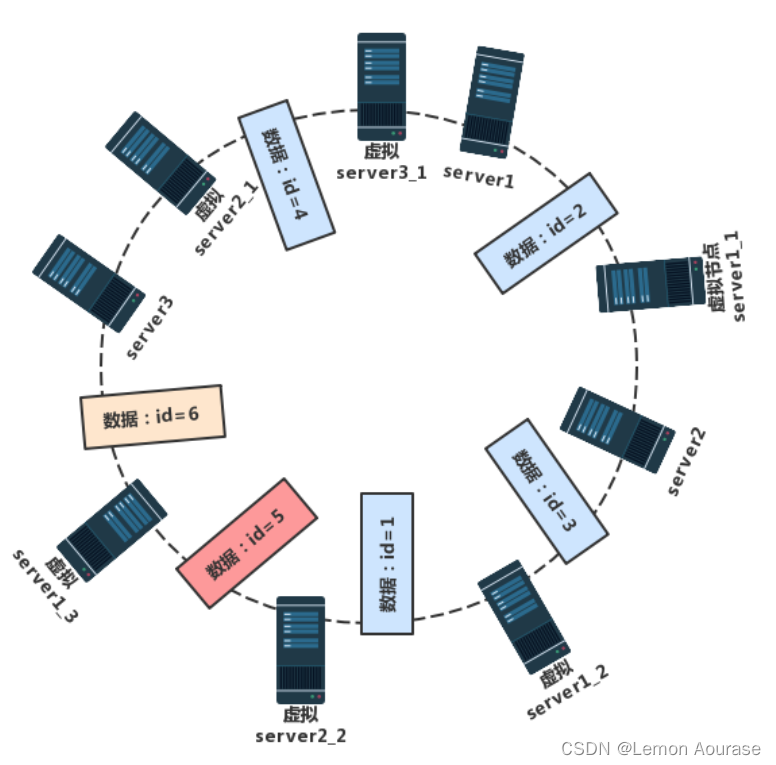
假设服务器server3是配置最差的,所以我们以服务器server3 为基准,服务器server2 是服务器server3 的两倍,服务器server1 是服务器server3 的三倍,我们建立虚拟节点。
假设服务器server3 的虚拟节点为服务器server3_1,服务器server2 就有两个虚拟节点服务器server2_1、服务器server2_2,服务器server1 有三个虚拟节点服务器server1_1、服务器server1_2、服务器server1_3。
落到虚拟节点上的数据都会存到对应的物理服务器上,所以通过带虚拟节点的一致性哈希算法后,数据存储结果为:数据id=2、id=3、id=5 的数据都会存储到服务器server1 上,id=1 的数据将会存储到服务器server2 上,数据 id=4、id=6 都会存放到服务器server3上。
虚拟槽分区
虚拟槽分区是 redis cluster 中默认的数据分布技术。
Redis cluster 中有16384(0~16383)个槽,会将这些槽平均分配到每个 master 上,在存储数据时利用 CRC16 算法,具体的计算公式为:slot = CRC16(key)/16384 来计算 key 属于哪个槽。
一个key查找过程图示如下:
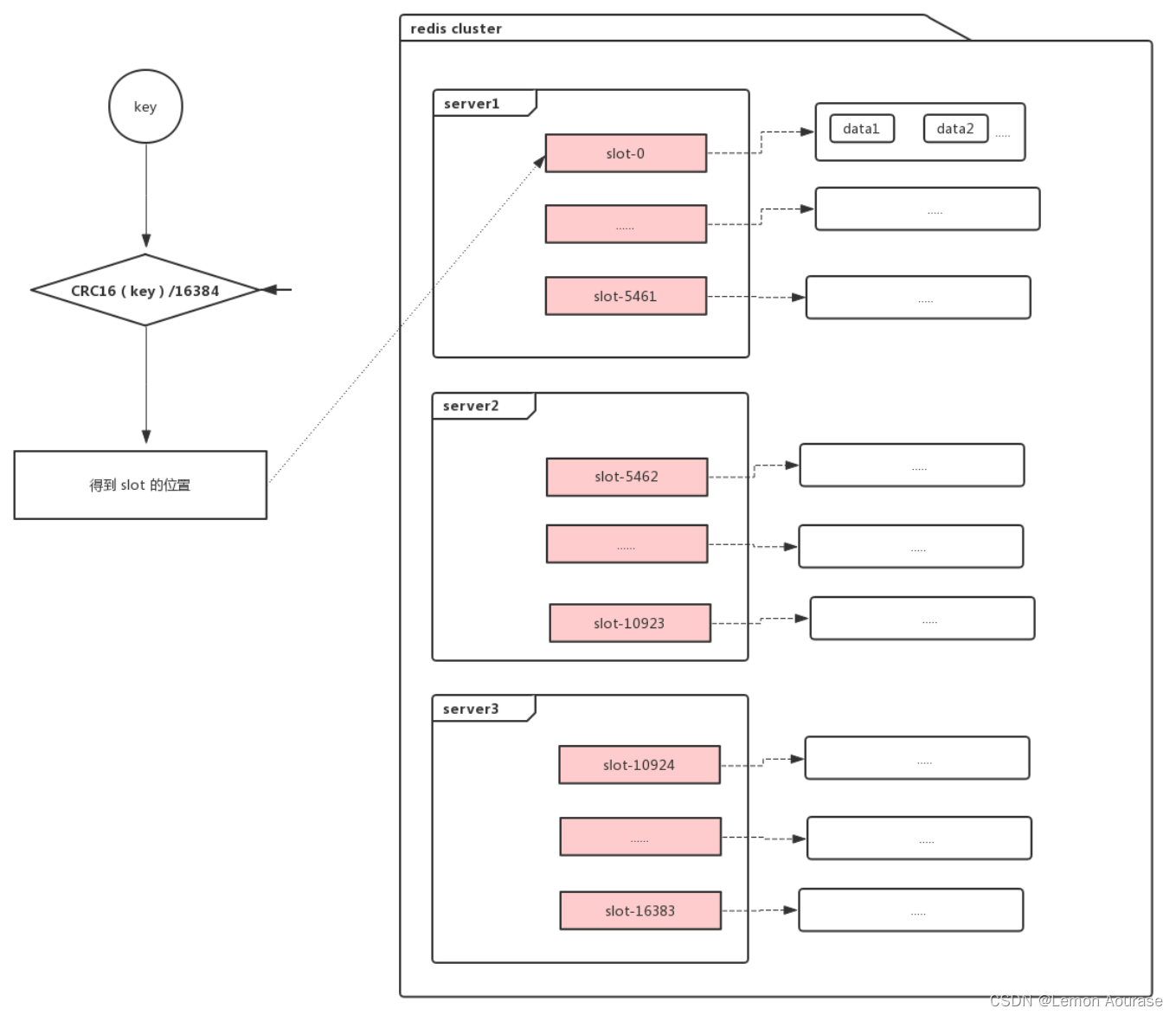
虚拟槽分区解耦了数据与节点的关系,通过引入槽,让槽成为集群内数据管理和迁移的基本单位,简化了节点扩容和收缩难度。我们只需关注数据在哪个槽,所以虚拟槽分区可以说比较好的兼容了数据均匀分布和扩展性的问题

















 1403
1403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









