







Spark SQL
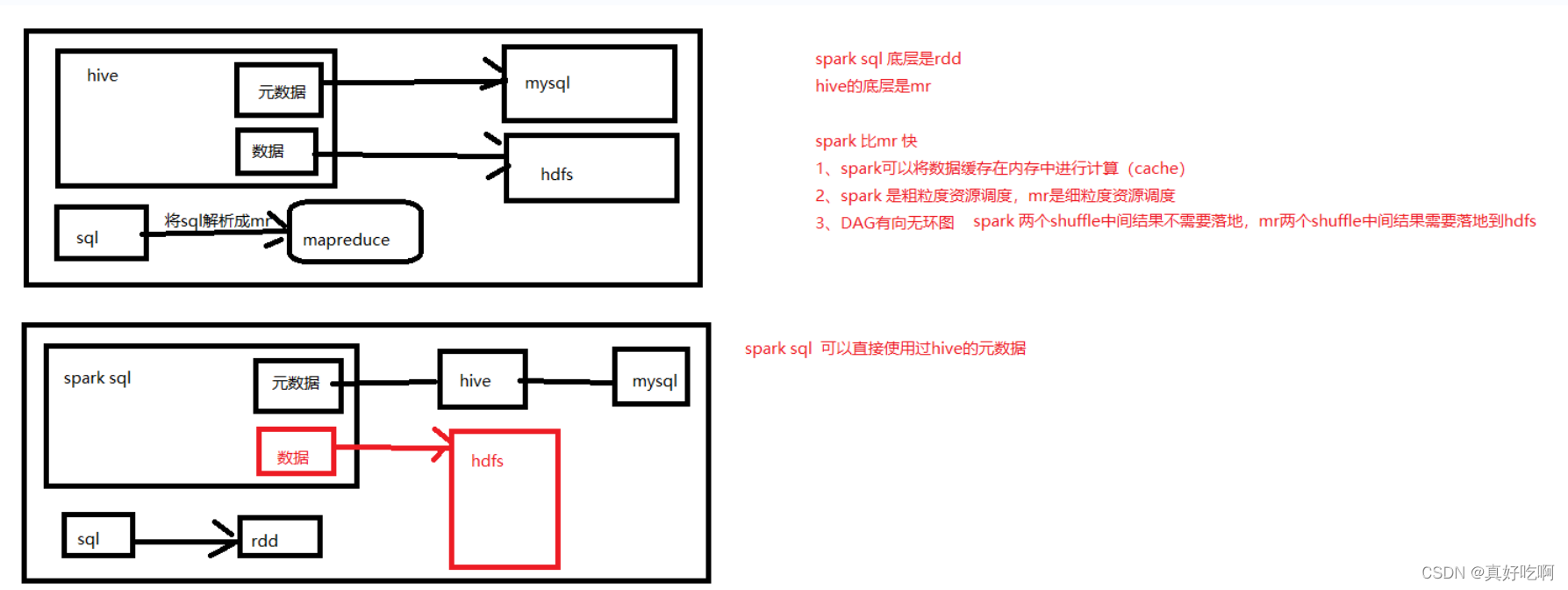
Spark SQL整合Hive
1. 修改Hive配置文件hive-site.xml
在Hive的conf目录下
在hive-site.xml中添加以下内容
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
2. 将hive-site.xml 复制到spark conf目录下
cp hive-site.xml /usr/local/soft/spark-2.4.5/conf/
3. 启动hive元数据服务
nohup hive --service metastore >> metastore.log 2>&1 &
4.将mysql 驱动包复制到saprk jars目录下
在Hive的lib目录下找到mysql驱动包
cp mysql-connector-java-5.1.17.jar /usr/local/soft/spark-2.4.5/jars/
5. 启动Spark SQL
文件小可以将并行度改小一点,默认并行度为200。
并行度的计算:10G的文件 / 128MB = 80
10G的文件需要80个Task
spark-sql
spark-sql --master yarn-client
--master yarn-client这个参数不写的话默认是local模式的
--不可以使用yarn-cluster,因为Driver端必须要在本地启动
spark-sql --master yarn-client --conf spark.sql.shuffle.partitions=2
--conf spark.sql.shuffle.partitions=2 可以在启动spark-sql时就指定,如果启动时不指定的话,后面可以在spark-sql中通过:set spark.sql.shuffle.partitions=2 指定
案例
创建student表
create table student
(
id string,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS textfile
location '/data/student/';
创建score表
create table score
(
student_id string 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











