







 本文围绕Java展开,介绍了读写锁,其读锁可多线程共享,写锁排他,还提及锁降级和不支持的锁升级;探讨了队列同步器AQS,它是锁对象底层实现;阐述原子类,底层用CAS算法保证原子性,能更新变量,同时分析了ABA问题及解决方案。
本文围绕Java展开,介绍了读写锁,其读锁可多线程共享,写锁排他,还提及锁降级和不支持的锁升级;探讨了队列同步器AQS,它是锁对象底层实现;阐述原子类,底层用CAS算法保证原子性,能更新变量,同时分析了ABA问题及解决方案。
读写锁
除了可重入锁之外,还有一种类型的锁叫做读写锁,当然它并不是专门用作读写操作的锁,它和可重入锁不同的地方在于,可重入锁是一种排他锁,当一个线程得到锁之后,另一个线程必须等待其释放锁,否则一律不允许获取到锁。而读写锁在同一时间,是可以让多个线程获取到锁的,它其实就是针对于读写场景而出现的。
读写锁维护了一个读锁和一个写锁,这两个锁的机制是不同的。
- 读锁:在没有任何线程占用写锁的情况下,同一时间可以有多个线程加读锁。
- 写锁:在没有任何线程占用读锁的情况下,同一时间只能有一个线程加写锁。
读写锁也有一个专门的接口:
public interface ReadWriteLock {
//获取读锁
Lock readLock();
//获取写锁
Lock writeLock();
}
此接口有一个实现类ReentrantReadWriteLock(实现的是ReadWriteLock接口,不是Lock接口,ReentrantReadWriteLock本身并不是锁,但可以通过它去获取读或者写锁),注意我们操作ReentrantReadWriteLock时,不能直接上锁,而是需要获取读锁或是写锁,再进行锁操作:
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.readLock().lock();
new Thread(lock.readLock()::lock).start();
}
这里我们对读锁加锁,可以看到可以多个线程同时对读锁加锁。程序执行不会卡住,能正常结束。因为读锁是共享锁。
但是写锁是排他锁,以下三种情况程序执行都会卡住。
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.readLock().lock();
new Thread(lock.writeLock()::lock).start();
}
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.writeLock().lock();
new Thread(lock.readLock()::lock).start();
}
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.writeLock().lock();
new Thread(lock.writeLock()::lock).start();
}
并且,ReentrantReadWriteLock不仅具有读写锁的功能,还保留了可重入锁(就是写锁)和公平/非公平机制,比如同一个线程可以重复为写锁加锁,并且必须全部解锁才真正释放锁:
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.writeLock().lock();
lock.writeLock().lock();
new Thread(() -> {
lock.writeLock().lock();
System.out.println("成功获取到写锁!");
}).start();
System.out.println("释放第一层锁!");
lock.writeLock().unlock();
TimeUnit.SECONDS.sleep(1);
System.out.println("释放第二层锁!");
lock.writeLock().unlock();
}
运行结果:
释放第一层锁!
释放第二层锁!
成功获取到写锁!
Process finished with exit code 0
通过之前的例子来验证公平和非公平(也是写锁):
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock(true);//公平锁
Runnable action = () -> {
System.out.println("线程 "+Thread.currentThread().getName()+" 将在1秒后开始获取锁...");
lock.writeLock().lock();
System.out.println("线程 "+Thread.currentThread().getName()+" 成功获取锁!");
lock.writeLock().unlock();
};
for (int i = 0; i < 10; i++) { //建立10个线程
new Thread(action, "T"+i).start();
}
}
线程 T0 将在1秒后开始获取锁...
线程 T1 将在1秒后开始获取锁...
线程 T2 将在1秒后开始获取锁...
线程 T5 将在1秒后开始获取锁...
线程 T0 成功获取锁!
线程 T4 将在1秒后开始获取锁...
线程 T7 将在1秒后开始获取锁...
线程 T3 将在1秒后开始获取锁...
线程 T8 将在1秒后开始获取锁...
线程 T1 成功获取锁!
线程 T6 将在1秒后开始获取锁...
线程 T9 将在1秒后开始获取锁...
线程 T2 成功获取锁!
线程 T5 成功获取锁!
线程 T4 成功获取锁!
线程 T7 成功获取锁!
线程 T3 成功获取锁!
线程 T8 成功获取锁!
线程 T6 成功获取锁!
线程 T9 成功获取锁!
Process finished with exit code 0
如果是false,就是非公平锁,运行结果:
线程 T0 将在1秒后开始获取锁...
线程 T5 将在1秒后开始获取锁...
线程 T4 将在1秒后开始获取锁...
线程 T6 将在1秒后开始获取锁...
线程 T7 将在1秒后开始获取锁...
线程 T3 将在1秒后开始获取锁...
线程 T1 将在1秒后开始获取锁...
线程 T2 将在1秒后开始获取锁...
线程 T5 成功获取锁!
线程 T8 将在1秒后开始获取锁...
线程 T8 成功获取锁!
线程 T9 将在1秒后开始获取锁...
线程 T9 成功获取锁!
线程 T6 成功获取锁!
线程 T4 成功获取锁!
线程 T0 成功获取锁!
线程 T7 成功获取锁!
线程 T3 成功获取锁!
线程 T1 成功获取锁!
线程 T2 成功获取锁!
Process finished with exit code 0
锁降级和锁升级
锁降级指的是写锁降级为读锁。当一个线程持有写锁的情况下,虽然其他线程不能加读锁,但是线程自己是可以加读锁的:
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.writeLock().lock();
lock.readLock().lock();
System.out.println("成功加读锁!");
}
那么,如果我们在同时加了写锁和读锁的情况下,释放写锁,是否其他的线程就可以一起加读锁了呢?
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.writeLock().lock();
lock.readLock().lock();
new Thread(() -> {
System.out.println("开始加读锁!");
lock.readLock().lock();
System.out.println("读锁添加成功!");
}).start();
TimeUnit.SECONDS.sleep(1);//休眠不会释放锁,但是会释放CPU的执行权。这行代码就是为了保证new的线程可以执行一半,另一半没有执行是因为主线程没有释放写锁
lock.writeLock().unlock(); //如果释放写锁,会怎么样?
}
运行结果:
开始加读锁
等一秒
读锁添加成功
可以看到,一旦写锁被释放,那么主线程就只剩下读锁了,因为读锁可以被多个线程共享,所以这时第二个线程也添加了读锁。而这种操作,就被称之为"锁降级"(注意不是先释放写锁再加读锁,而是持有写锁的情况下申请读锁再释放写锁)
注意在仅持有读锁的情况下去申请写锁,属于"锁升级",ReentrantReadWriteLock是不支持的:
public static void main(String[] args) throws InterruptedException {
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.readLock().lock();
lock.writeLock().lock();
System.out.println("所升级成功!");
}
可以看到线程直接卡在加写锁的那一句了。
队列同步器AQS
这一部分是锁对象的底层实现,难度很大,先抛出问题,之后有时间再看。【先完成再完美,先学会最小必要知识】
前面我们了解了可重入锁和读写锁,那么它们的底层实现原理到底是什么样的呢?
比如我们执行了ReentrantLock的lock()方法,那它的内部是怎么在执行的呢?
public void lock() {
sync.lock();
}
可以看到,它的内部实际上啥都没做,而是交给了Sync对象在进行,并且,不只是这个方法,其他的很多方法都是依靠Sync对象在进行:
public void unlock() {
sync.release(1);
}
那么这个Sync对象是干什么的呢?可以看到,公平锁和非公平锁都是继承自Sync,而Sync是继承自AbstractQueuedSynchronizer,简称队列同步器:
abstract static class Sync extends AbstractQueuedSynchronizer {
//...
}
static final class NonfairSync extends Sync {}
static final class FairSync extends Sync {}
所以,要了解它的底层到底是如何进行操作的,还得看队列同步器,我们就先从这里下手吧!
原子类
前面我们说到,如果要保证i++的原子性(前面结果在一万到两万之间的那个例子),那么我们的唯一选择就是加锁,那么,除了加锁之外,还有没有其他更好的解决方法呢?JUC为我们提供了原子类,底层采用CAS算法,它是一种用法简单、性能高效、线程安全地更新变量的方式。
所有的原子类都位于java.util.concurrent.atomic包下。
原子类介绍
常用基本数据类,有对应的原子类封装:
- AtomicInteger:原子更新int
- AtomicLong:原子更新long
- AtomicBoolean:原子更新boolean
那么,原子类和普通的基本类在使用上有没有什么区别呢?我们先来看正常情况下使用一个基本类型:
public class Main {
public static void main(String[] args) {
int i = 1;
System.out.println(i++);
}
}
现在我们使用int类型对应的原子类,要实现同样的代码该如何编写:
public class Main {
public static void main(String[] args) {
AtomicInteger i = new AtomicInteger(1);
System.out.println(i.getAndIncrement()); //如果想实现i += 2这种操作,可以使用 addAndGet() 自由设置delta 值
}
}
输出的是1,i实际是2。和上面那个例子一样的效果。
我们可以将int数值封装到此类中(注意必须调用构造方法,它不像Integer那样有装箱机制),并且通过调用此类提供的方法来获取或是对封装的int值进行自增,乍一看,这不就是基本类型包装类嘛,有啥高级的。确实,还真有包装类那味,但是它可不仅仅是简单的包装,它的自增操作是具有原子性的:
public class Main {
private static AtomicInteger i = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Runnable r = () -> {
for (int j = 0; j < 100000; j++)
i.getAndIncrement();
System.out.println("自增完成!");
};
new Thread(r).start();
new Thread(r).start();
TimeUnit.SECONDS.sleep(1);
System.out.println(i.get());
}
}
自增完成!
自增完成!
200000
同样是直接进行自增操作,我们发现,使用原子类是可以保证自增操作原子性的,就跟我们前面加锁一样。怎么会这么神奇?我们来看看它的底层是如何实现的,直接从构造方法点进去:
private volatile int value;
public AtomicInteger(int initialValue) {
value = initialValue;
}
public AtomicInteger() {
}
可以看到,它的底层是比较简单的,其实本质上就是封装了一个volatile类型的int值,这样能够保证可见性,在CAS操作的时候不会出现问题。
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
可以看到最上面是和AQS采用了类似的机制,因为要使用CAS算法更新value的值,所以得先计算出value字段在对象中的偏移地址,CAS直接修改对应位置的内存即可(可见Unsafe类的作用巨大,很多的底层操作都要靠它来完成)
接着我们来看自增操作是怎么在运行的:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
可以看到这里调用了unsafe.getAndAddInt(),套娃时间到,我们接着看看Unsafe里面写了什么:
public final int getAndAddInt(Object o, long offset, int delta) { //delta就是变化的值,++操作就是自增1
int v;
do {
//volatile版本的getInt()
//能够保证可见性
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta)); //compareAndSwapInt(o, offset, v, v + delta)是Unsafe类的本地方法,是c++实现的。这个CAS方法是真正最底层的CPU的CAS指令。CAS操作:先看值是不是和预期的一样,如果是那就进行更新。其中变量v就是预期的值,然后compareAndSwapInt这个方法又会再去对应的内存地址拿一次值,如果是相等的就是和预期一样。
//这里是开始cas替换int的值,每次都去拿最新的值去进行替换,如果成功则离开循环,不成功说明这个时候其他线程先修改了值,就进下一次循环再获取最新的值然后再cas一次,直到成功为止
return v;
}
可以看到这是一个do-while循环,那么这个循环在做一个什么事情呢?感觉就和我们之前讲解的AQS队列中的机制差不多,也是采用自旋形式,来不断进行CAS操作,直到成功。
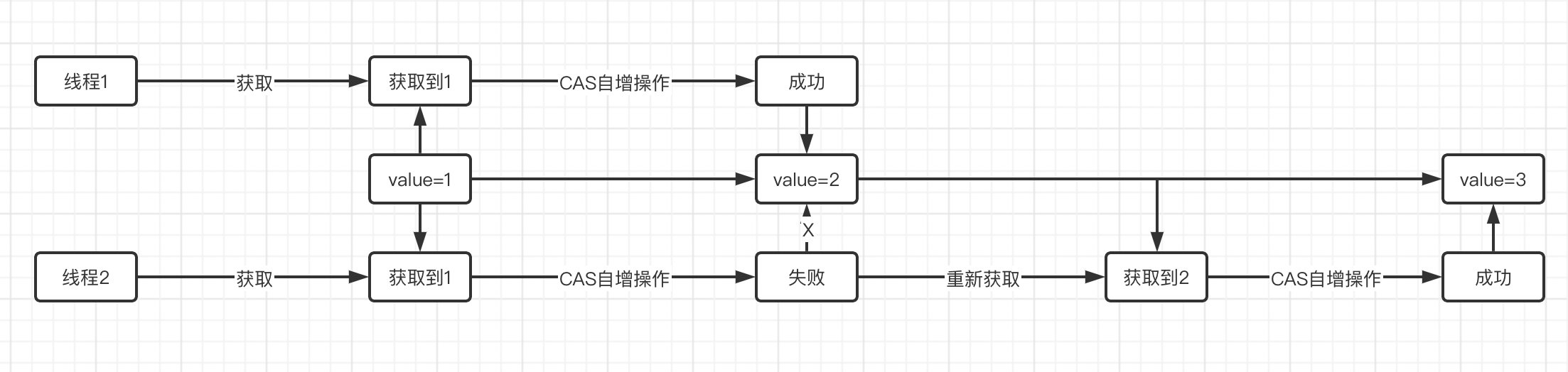
可见,原子类底层也是采用了CAS算法来保证的原子性,包括getAndSet、getAndAdd等方法都是这样。原子类也直接提供了CAS操作方法,我们可以直接使用:
public static void main(String[] args) throws InterruptedException {
AtomicInteger integer = new AtomicInteger(10);
System.out.println(integer.compareAndSet(30, 20));//很明显这是JAVA层面的CAS。不是底层的cpu指令。
System.out.println(integer.compareAndSet(10, 20));
System.out.println(integer);
}
运行结果:
false
true
20
如果想以普通变量的方式来设定值,那么可以使用lazySet()方法,这样就不采用volatile的立即可见机制了。
AtomicInteger integer = new AtomicInteger(1);
integer.lazySet(2);
除了基本类有原子类以外,基本类型的数组类型也有原子类:
- AtomicIntegerArray:原子更新int数组
- AtomicLongArray:原子更新long数组
- AtomicReferenceArray:原子更新引用数组
其实原子数组和原子类型一样的,不过我们可以对数组内的元素进行原子操作:
public static void main(String[] args) throws InterruptedException {
AtomicIntegerArray array = new AtomicIntegerArray(new int[]{0, 4, 1, 3, 5});
Runnable r = () -> {
for (int i = 0; i < 100000; i++)
array.getAndAdd(0, 1);//拿第一个元素,自增100000次
};
new Thread(r).start();
new Thread(r).start();
TimeUnit.SECONDS.sleep(1);
System.out.println(array.get(0));
}
运行结果:
200000
在JDK8之后,新增了DoubleAdder和LongAdder,在高并发情况下,LongAdder的性能比AtomicLong的性能更好,主要体现在自增上,它的大致原理如下:在低并发情况下,和AtomicLong是一样的,对value值进行CAS操作,但是出现高并发的情况时,AtomicLong会进行大量的循环操作来保证同步,而LongAdder会将对value值的CAS操作分散为对数组cells中多个元素的CAS操作(内部维护一个Cell[] as数组,每个Cell里面有一个初始值为0的long型变量,在高并发时会进行分散CAS,就是不同的线程可以对数组中不同的元素进行CAS自增,这样就避免了所有线程都对同一个值进行CAS),只需要最后再将结果加起来即可。
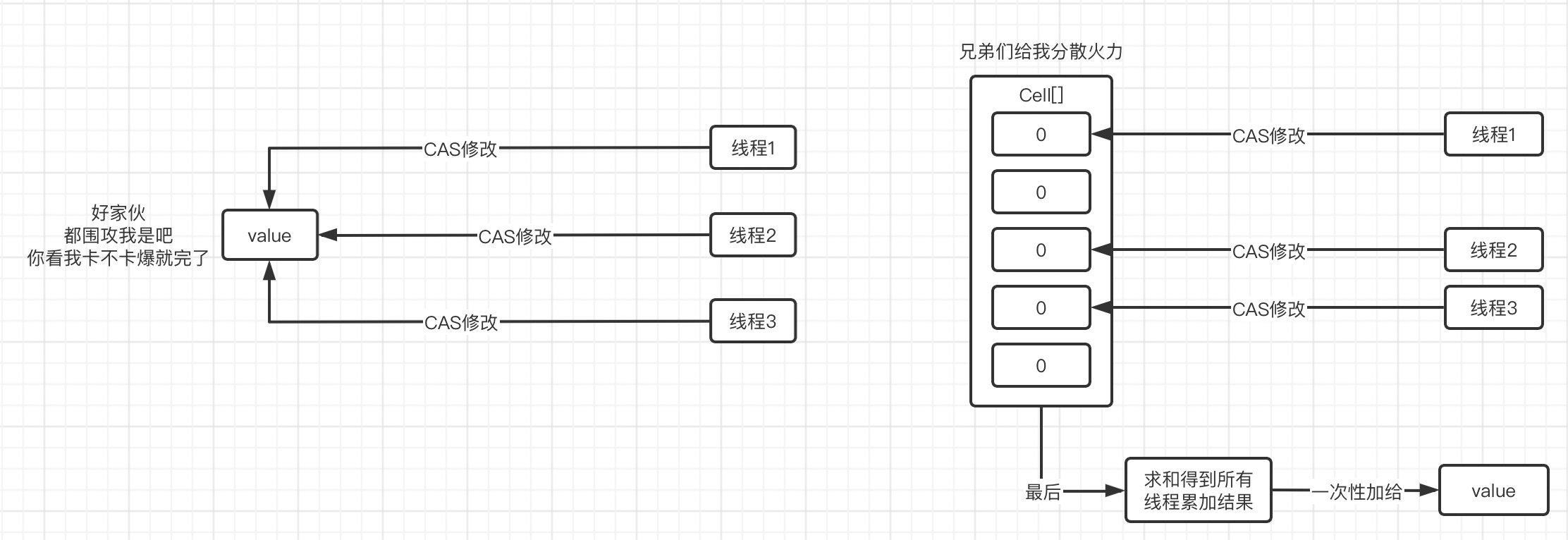
使用如下:
public static void main(String[] args) throws InterruptedException {
LongAdder adder = new LongAdder();
Runnable r = () -> {
for (int i = 0; i < 100000; i++)
adder.add(1);
};
for (int i = 0; i < 100; i++)
new Thread(r).start(); //100个线程
TimeUnit.SECONDS.sleep(1);
System.out.println(adder.sum()); //最后求和即可
}
运行结果:
100 00000
由于底层源码比较复杂,这里就不做讲解了。两者的性能对比(这里用到了CountDownLatch,自减):
public class Main {
public static void main(String[] args) throws InterruptedException {
System.out.println("使用AtomicLong的时间消耗:"+test2()+"ms");
System.out.println("使用LongAdder的时间消耗:"+test1()+"ms");
}
private static long test1() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(100);
LongAdder adder = new LongAdder();
long timeStart = System.currentTimeMillis();
Runnable r = () -> {
for (int i = 0; i < 100000; i++)
adder.add(1);
latch.countDown();
};
for (int i = 0; i < 100; i++)
new Thread(r).start();
latch.await();
return System.currentTimeMillis() - timeStart;
}
private static long test2() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(100);
AtomicLong atomicLong = new AtomicLong();
long timeStart = System.currentTimeMillis();
Runnable r = () -> {
for (int i = 0; i < 100000; i++)
atomicLong.incrementAndGet();
latch.countDown();
};
for (int i = 0; i < 100; i++)
new Thread(r).start();
latch.await();
return System.currentTimeMillis() - timeStart;
}
}
使用AtomicLong的时间消耗:234ms
使用LongAdder的时间消耗:52ms
除了对基本数据类型支持原子操作外,对于引用类型,也是可以实现原子操作的:
public static void main(String[] args) throws InterruptedException {
String a = "Hello";
String b = "World";
AtomicReference<String> reference = new AtomicReference<>(a);
reference.compareAndSet(a, b);
System.out.println(reference.get());
}
world
JUC还提供了字段原子更新器,可以对类中的某个指定字段进行原子操作(注意字段必须添加volatile关键字):
public class Main {
public static void main(String[] args) throws InterruptedException {
Student student = new Student();
AtomicIntegerFieldUpdater<Student> fieldUpdater =
AtomicIntegerFieldUpdater.newUpdater(Student.class, "age");
System.out.println(fieldUpdater.incrementAndGet(student));
}
public static class Student{
volatile int age;
}
}
结果:
1
了解了这么多原子类,是不是感觉要实现保证原子性的工作更加轻松了。
ABA问题及解决方案
我们来想象一下这种场景:
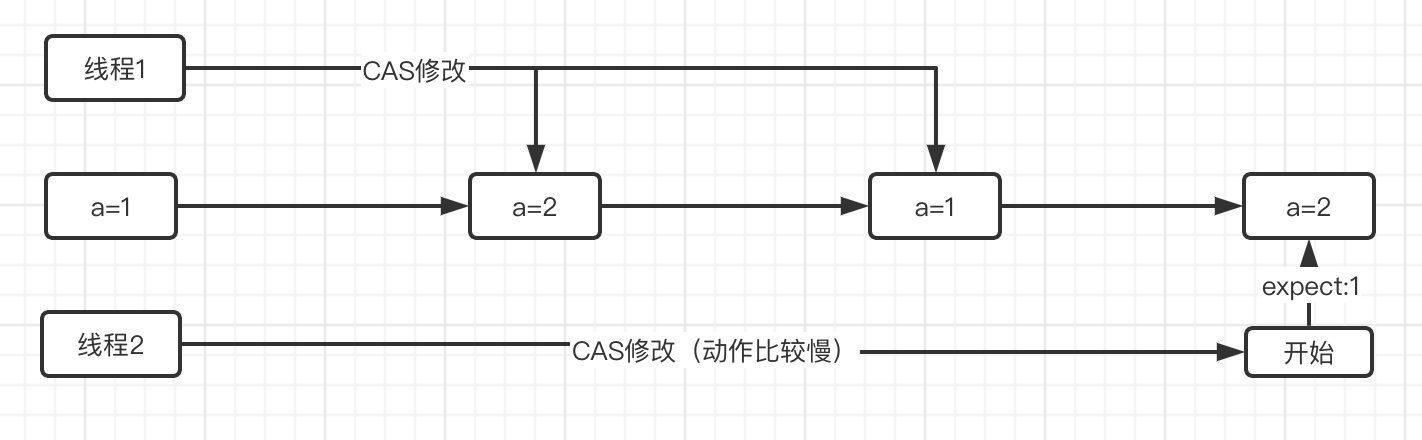
线程1和线程2同时开始对a的值进行CAS修改,但是线程1的速度比较快,将a的值修改为2之后紧接着又修改回1,这时线程2才开始进行判断,发现a的值是1,所以CAS操作成功。
很明显,这里的1已经不是一开始的那个1了,而是被重新赋值的1,这也是CAS操作存在的问题(无锁虽好,但是问题多多),它只会机械地比较当前值是不是预期值,但是并不会关心当前值是否被修改过,这种问题称之为ABA问题。
那么如何解决这种ABA问题呢,JUC提供了带版本号的引用类型,只要每次操作都记录一下版本号,并且版本号不会重复,那么就可以解决ABA问题了:
public static void main(String[] args) throws InterruptedException {
String a = "Hello";
String b = "World";
AtomicStampedReference<String> reference = new AtomicStampedReference<>(a, 1); //在构造时需要指定初始值和对应的版本号
reference.attemptStamp(a, 2); //可以中途对版本号进行修改,注意要填写当前的引用对象
System.out.println(reference.compareAndSet(a, b, 2, 3)); //CAS操作时不仅需要提供预期值和修改值,还要提供预期版本号和新的版本号
System.out.println(reference.getReference());
}
true
World




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











