







 本文是《数据库系统》课程实验指南,重点介绍了如何使用DataGrip连接和操作SQL Server,包括数据定义、查询、更新、视图和数据控制等实验内容,涉及SQL Server的TCP/IP协议配置、DataGrip的使用以及各种SQL操作技巧。
本文是《数据库系统》课程实验指南,重点介绍了如何使用DataGrip连接和操作SQL Server,包括数据定义、查询、更新、视图和数据控制等实验内容,涉及SQL Server的TCP/IP协议配置、DataGrip的使用以及各种SQL操作技巧。
内容来自2021春季学期《数据库系统》课程的实验要求,具体来自《数据库系统实验指导教程(第二版)》
本片文章中使用的是SQL Server配合DataGrip,仅对DataGrip做一些基础使用的介绍,不赘述SQL Server安装过程
配置DataGrip
这里介绍的是如何使用DataGrip连接SQL Server,而且DataGrip是一款付费软件(可以通过学生认证白嫖使用权),如果使用的是SSMS连接SQL Server,那么可以直接跳过这部分
什么是DataGrip
DataGrip是JetBrains公司为数据库开发的一款IDE,一开始其相应功能仅是作为大名鼎鼎的IDEA的插件,后来独立成为了一款IDE,理论上来说完全可以通过为IDEA添加插件来实现相应功能,但是我喜欢一款IDE仅做一方面的工作,所以我还是安装了DataGrip,既然是JetBrains公司出品的,那么补全功能就是他们的一贯作风,我是离不开自动补全了,顺别贴一下我使用的软件(红框中的都是JetBrains公司出品的):

安装DataGrip有两种方法,一种是下载安装包安装,一种是使用JetBrains ToolBox安装,因为我使用学生认证白嫖了JetBrains全家桶,所以我使用JetBrains ToolBox进行相应的管理,这里不做安装过程的展示。
DataGrip:https://www.jetbrains.com/datagrip/
JetBrains ToolBox:https://www.jetbrains.com/toolbox-app/
开启SQL Server的TCP/IP协议
使用DataGrip连接SQL Server需要其开启TCP/IP功能,因为DataGrip不同于SSMS,并不属于官方工具,需要通过TCP/IP连接
打开SQL Server 2019 配置管理器(如果严格按照老师的要求应该是安装2016),可以在开始菜单中找到,也可以通过"Win+Q"搜索找到,比如:
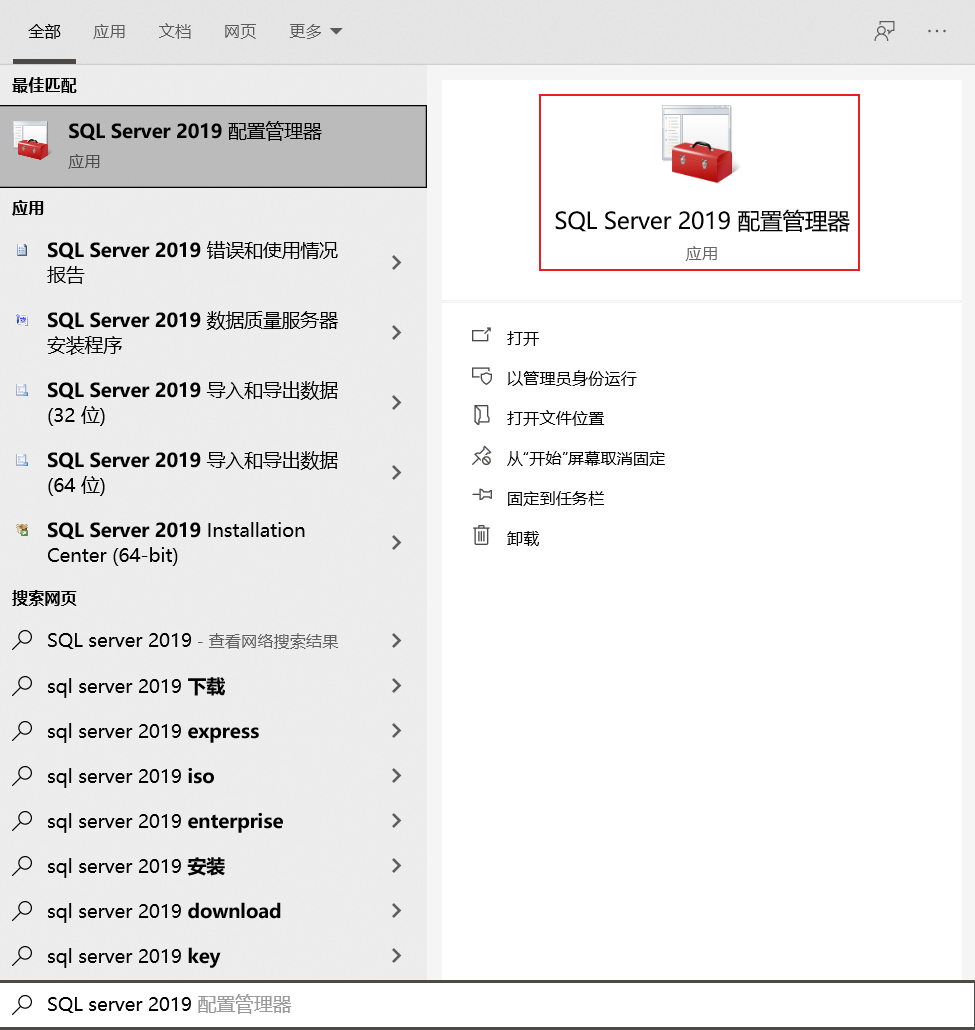
然后依次点开"SQL Server网络配置"->“MSSQLSERVER的协议”->“TCP/IP”
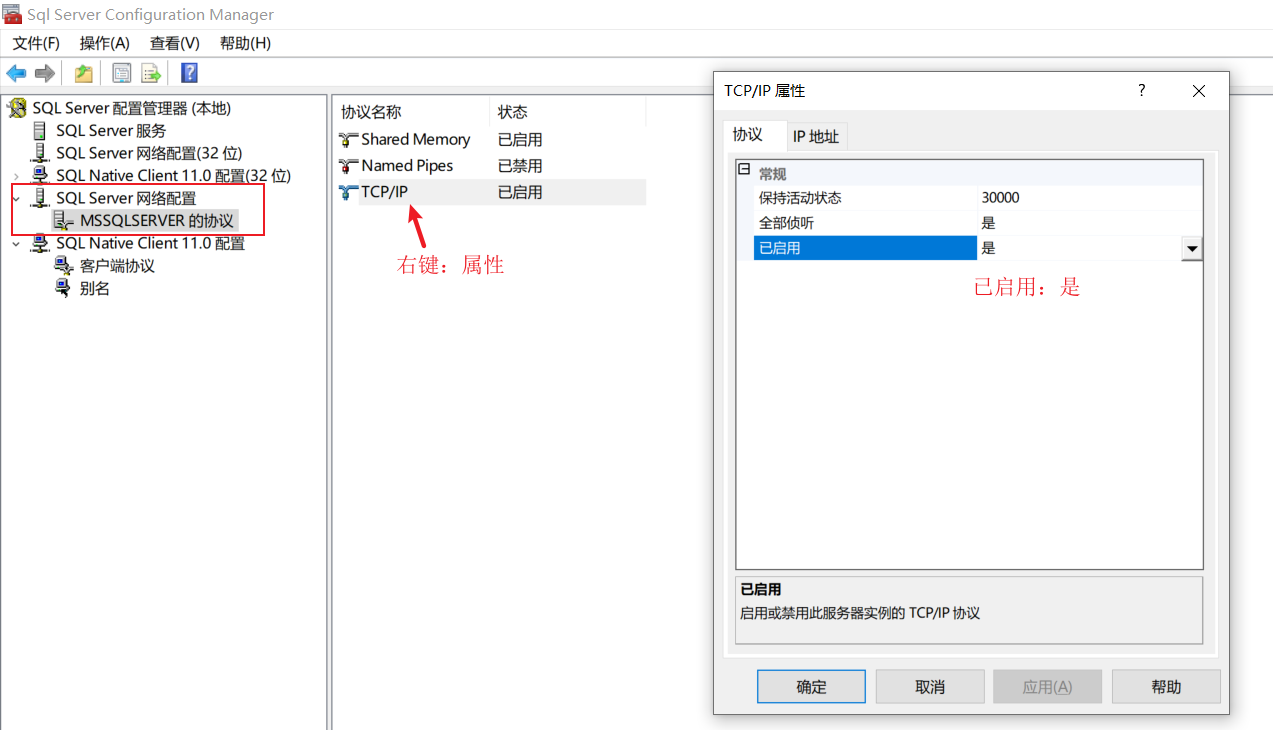
然后依次点开"SQL Server服务"->"SQL Server(MSSQLSERVER)"重启
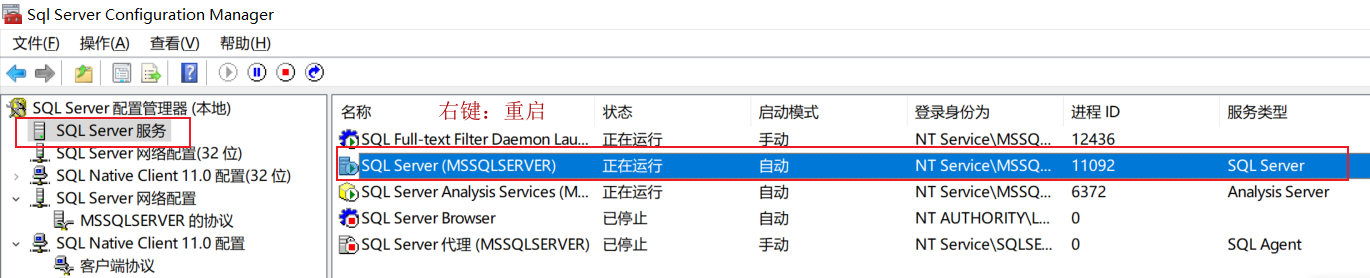
DataGrip连接SQL Server
依次点击"File"->“New”->“Data Source”->“Microsoft SQL Server”(SQL Server在Data Source中的顺序不一定与我的一致,因为我已经添加过了,开头第一个不是的话往下翻看找找)
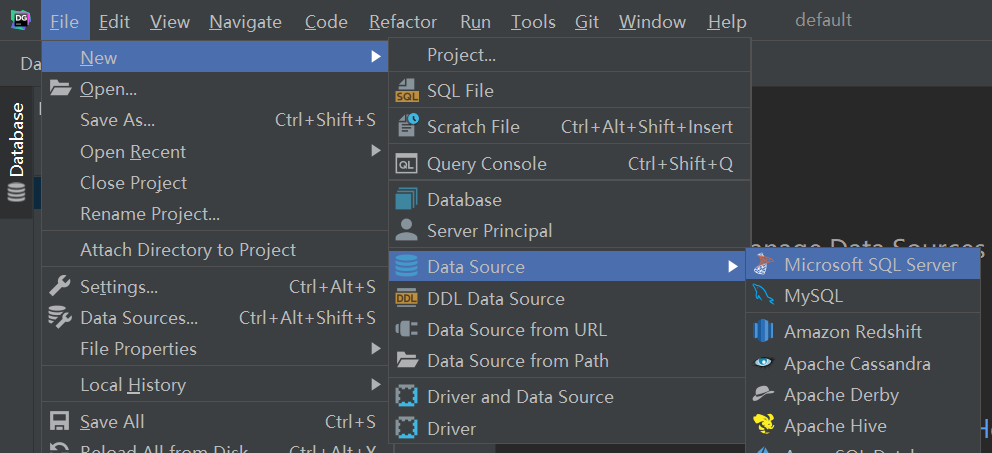
然后填写信息即可,这里做一下简单的介绍:
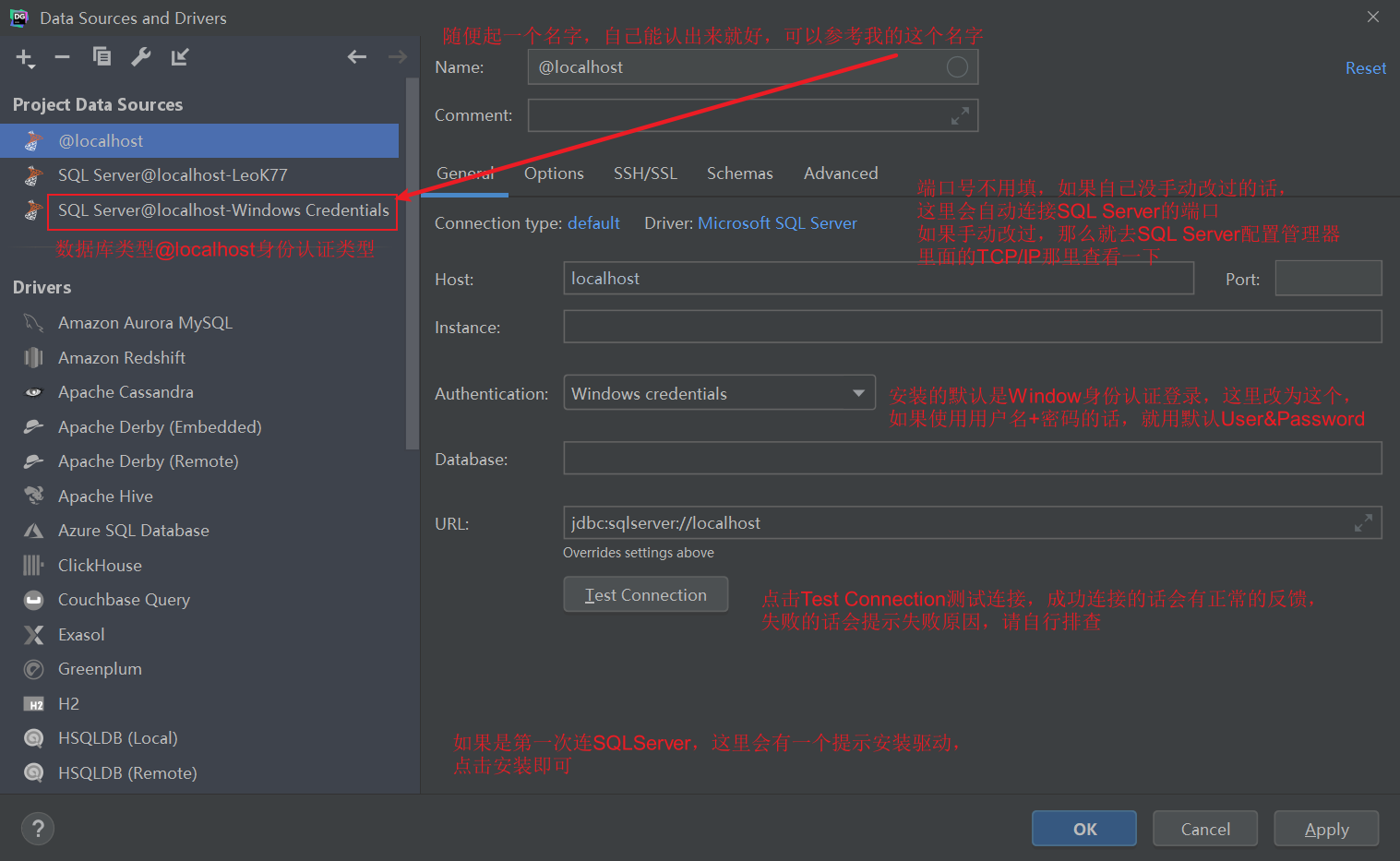
Test Connection成功示例:
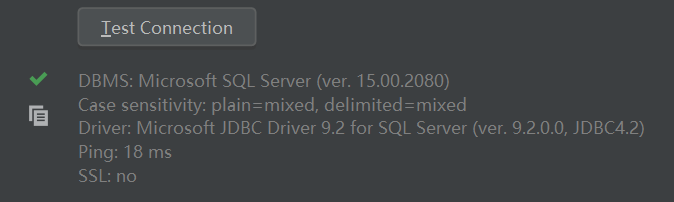
DataGrip主窗口,布局介绍大致如下:
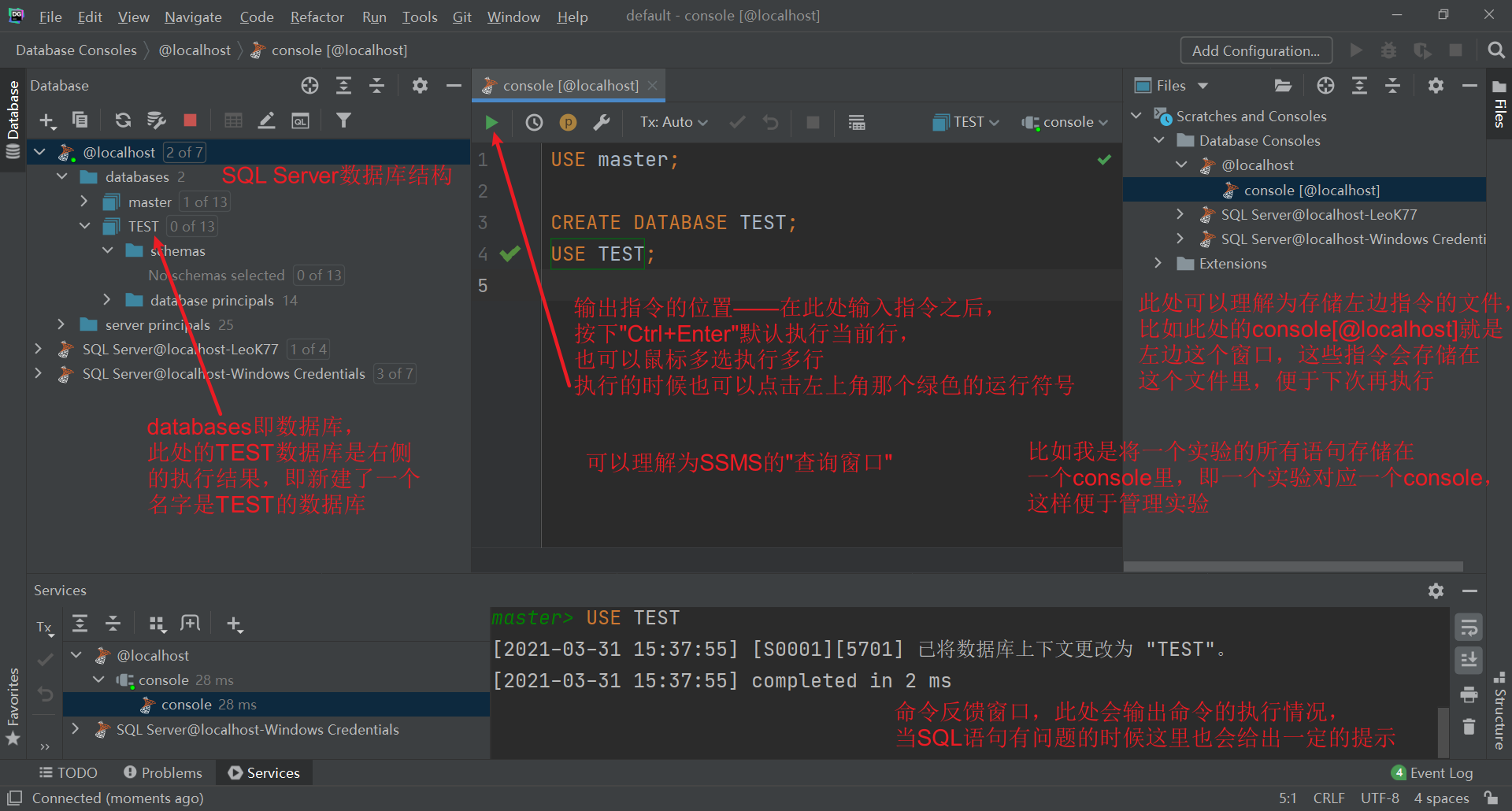
很多内容默认是不列出的,比如SQL Server数据库的默认SCHEMA是dbo,但是上述新建的TEST数据库中列出的SCHEMA居然一个也没有,这时候就需要手动使dboSCHEMA可见:
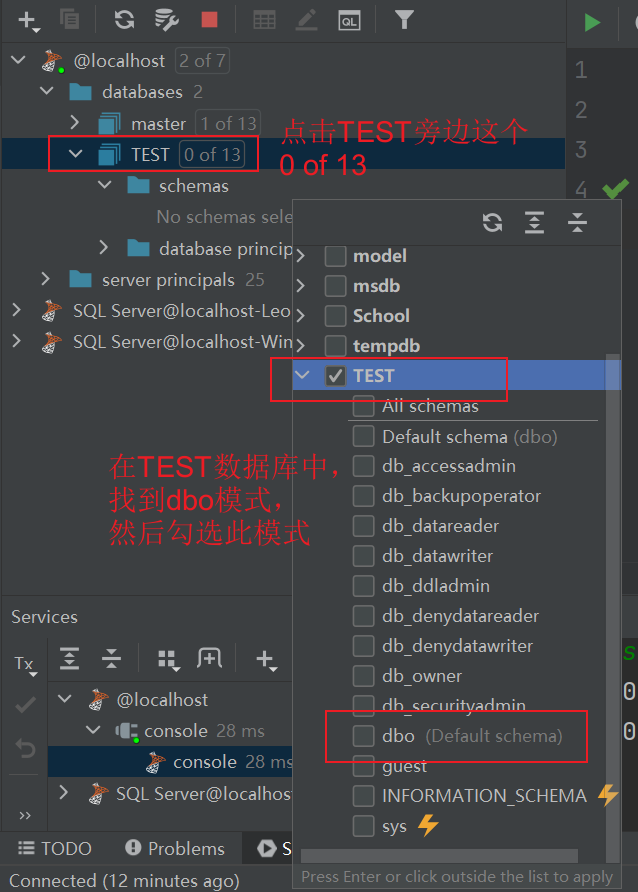
这样新建表或者对表进行操作之后,表的信息就可以在左侧看到了。
实验1.1——数据定义
实验目的:熟悉SQL的数据定义语言,能够熟练地使用SQL语句来创建和更改基本表,创建和取消索引
实验内容
- 使用CREATE语句创建基本表
- 更改基本表的定义,增加列,删除列,修改列的数据类型
- 创建表的升降序索引
- 取消表、表的索引或表的约束
实验步骤
(1)使用SQL语句创建关系数据库表:人员表PERSON(P#, Pname, Page, Pgender),房间表ROOM(R#, Rname, Rarea),表P-R(P#, R#, Date)。其中P#是表PERSON的主键,具有唯一性约束,Page具有约束:大于18;R#是表ROOM的主键,具有唯一性约束;表P-R中的P#,R#是外键。
CREATE TABLE PERSON
(
P# CHAR(8) NOT NULL UNIQUE,
Pname CHAR(20) NOT NULL,
Page INT,
PRIMARY KEY (P#),
CHECK (Page > 18)
);
CREATE TABLE ROOM
(
R# CHAR(8) NOT NULL UNIQUE,
Rname CHAR(20),
Rarea FLOAT(10),
PRIMARY KEY (R#)
);
CREATE TABLE PR
(
P# CHAR(8) NOT NULL UNIQUE,
R# CHAR(8) NOT NULL UNIQUE,
Date DATETIME,
PRIMARY KEY (P#, R#),
-- FOREIGN KEY (P#) REFERENCES PERSON ON DELETE CASCADE,
-- FOREIGN KEY (R#) REFERENCES ROOM ON DELETE CASCADE
FOREIGN KEY (P#) REFERENCES PERSON,
FOREIGN KEY (R#) REFERENCES ROOM
);
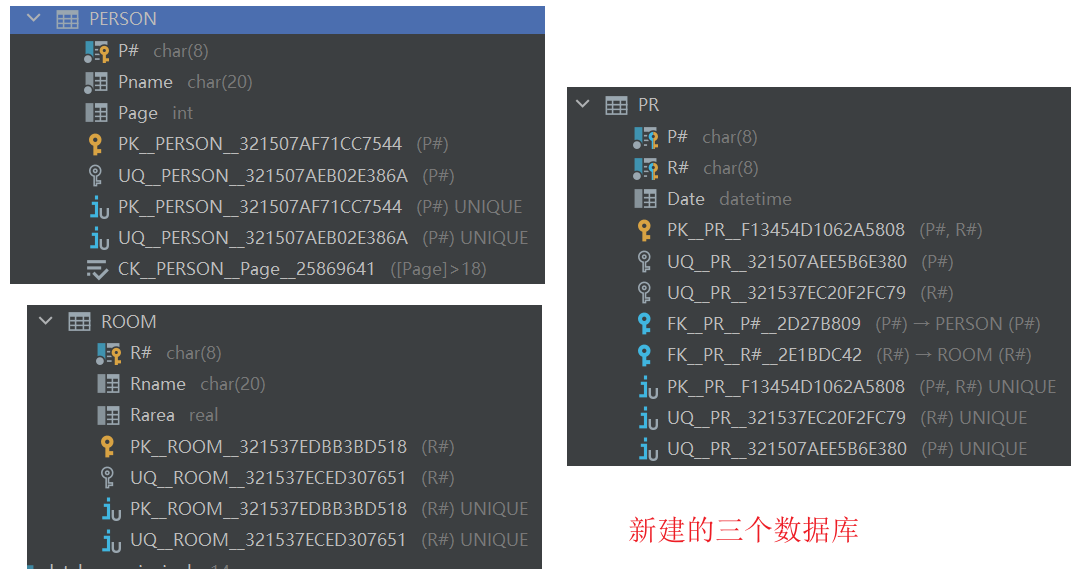
(2)更改表PERSON,增加属性Rtype(类型是CHAR,长度为10),取消Page大于18的约束。把表ROOM中的属性Rname的数据类型改为长度是30。
ALTER TABLE PERSON
ADD Ptype CHAR(10);
ALTER TABLE PERSON
DROP CONSTRAINT CK__PERSON__Page__25869641;
ALTER TABLE ROOM
ALTER COLUMN Rname CHAR(30);
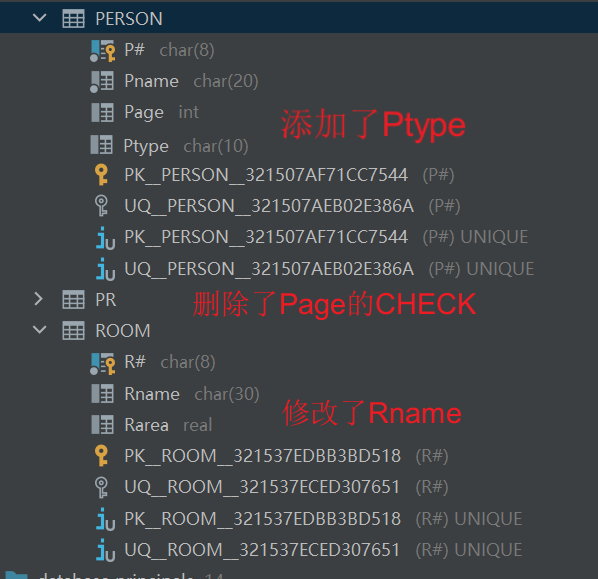
(3)删除表ROOM的一个属性Rarea。
(4)取消表PR。
ALTER TABLE ROOM
DROP COLUMN Rarea;
DROP TABLE PR;
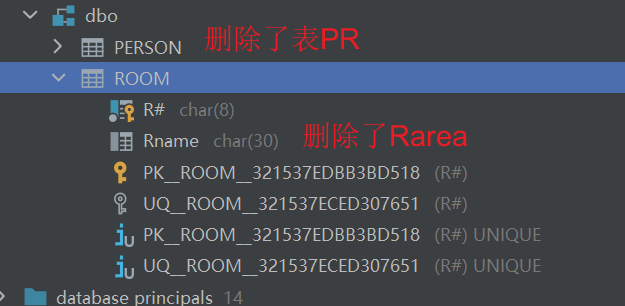
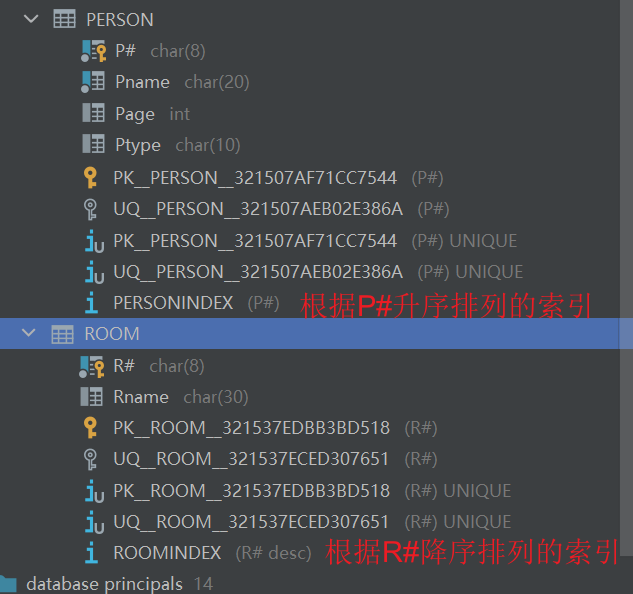
(5)为ROOM表创建按R#降序排列的索引。
(6)为PERSON表创建按P#升序排列的索引。
CREATE INDEX ROOMINDEX ON ROOM (R# DESC);
CREATE INDEX PERSONINDEX ON PERSON (P# ASC);
(7)创建表PERSON的按Pname升序排列的唯一性索引。
(8)取消PERSON表P#升序索引。
CREATE UNIQUE INDEX PERSONUNIQUE ON PERSON (Pname ASC);
DROP INDEX PERSON.PERSONINDEX;
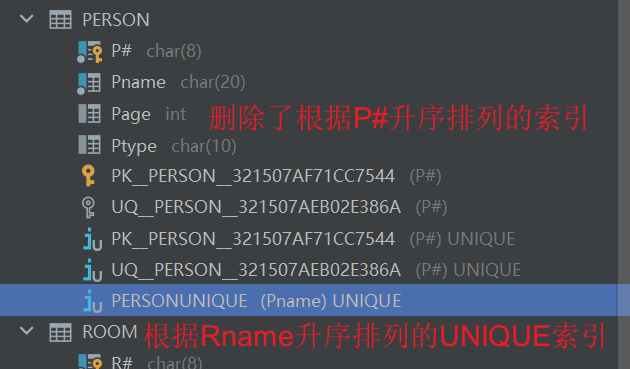
自我实践
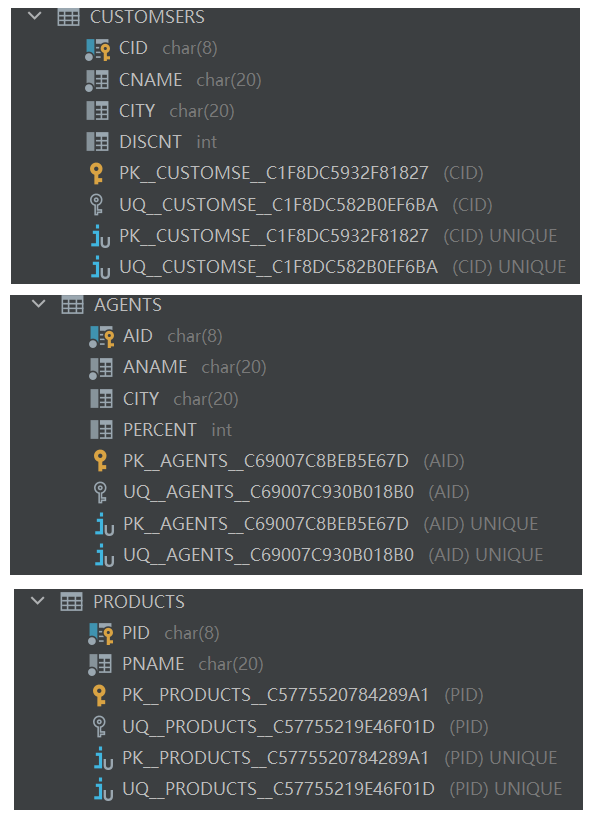
(1)创建数据库表CUSTOMSERS(CID, CNAME, CITY, DISCNT),数据库表AGENTS(AID, ANAME, CITY, PERCENT),数据库表PRODUCTS(PID, PNAME)。其中CID,AID,PID分别是各表的主键,具有唯一性约束。
CREATE TABLE CUSTOMSERS
(
CID CHAR(8) NOT NULL UNIQUE,
CNAME CHAR(20) NOT NULL,
CITY CHAR(20),
DISCNT INT,
PRIMARY KEY (CID)
)
CREATE TABLE AGENTS
(
AID CHAR(8) NOT NULL UNIQUE,
ANAME CHAR(20) NOT NULL,
CITY CHAR(20),
[PERCENT] INT,
PRIMARY KEY (AID)
);
CREATE TABLE PRODUCTS
(
PID CHAR(8) NOT NULL UNIQUE,
PNAME CHAR(20) NOT NULL,
PRIMARY KEY (PID)
);
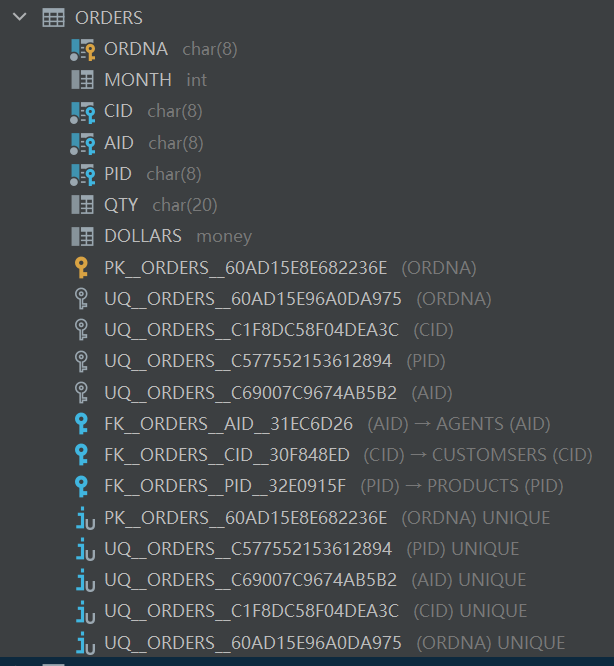
(2)创建数据库表ORDERS(ORDNA, MONTH, CID, AID, PID, QTY, DOLLARS)。其中ORDNA是主键,具有唯一性约束;CID,AID,PID是外键,分别参照的是表CUSTOMSERS的CID字段,表AGENTS的AID字段,PRODUCTS的PID字段。
CREATE TABLE ORDERS
(
ORDNA CHAR(8) NOT NULL UNIQUE,
MONTH INT,
CID CHAR(8) NOT NULL UNIQUE,
AID CHAR(8) NOT NULL UNIQUE,
PID CHAR(8) NOT NULL UNIQUE,
QTY CHAR(20),
DOLLARS MONEY,
PRIMARY KEY (ORDNA),
FOREIGN KEY (CID) REFERENCES CUSTOMSERS (CID),
FOREIGN KEY (AID) REFERENCES AGENTS (AID),
FOREIGN KEY (PID) REFERENCES PRODUCTS (PID)
);
(3)增加数据库表PRODUCTS的三个属性列:CITY,QUANTITY,PRICE。
ALTER TABLE PRODUCTS
ADD CITY CHAR(20);
ALTER TABLE PRODUCTS
ADD QUANTITY INT;
ALTER TABLE PRODUCTS
ADD PRICE MONEY;
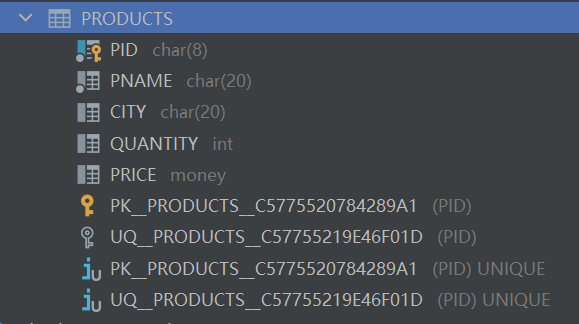
(4)为以上四个表建立各自的按主键增序排列的索引。
CREATE INDEX CUSINDEX ON CUSTOMSERS (CID);
CREATE INDEX AGENTSINDEX ON AGENTS (AID);
CREATE INDEX PROINDEX ON PRODUCTS (PID);
CREATE INDEX ORDERSINDEX ON ORDERS (ORDNA);
(5)取消步骤(4)建立的四个索引。
DROP INDEX CUSTOMSERS.CUSINDEX;
DROP INDEX AGENTS.AGENTSINDEX;
DROP INDEX PRODUCTS.PROINDEX;
DROP INDEX ORDERS.ORDERSINDEX;
实验1.2——数据查询
实验目的:熟悉SQL语句的数据查询语言,能够使用SQL语句对数据库进行单表查询、连接查询、嵌套查询、集合查询和统计查询。通过实验理解在数据库表中的对数据的NULL值的处理。
前期准备
虽然直接写出SELECT语句也可以,但是为了直观的看出自己写的对不对,还是要先导入School数据库,一般情况下导入数据库时遇到的最多的问题就是“访问权限”问题,修改一下权限即可:
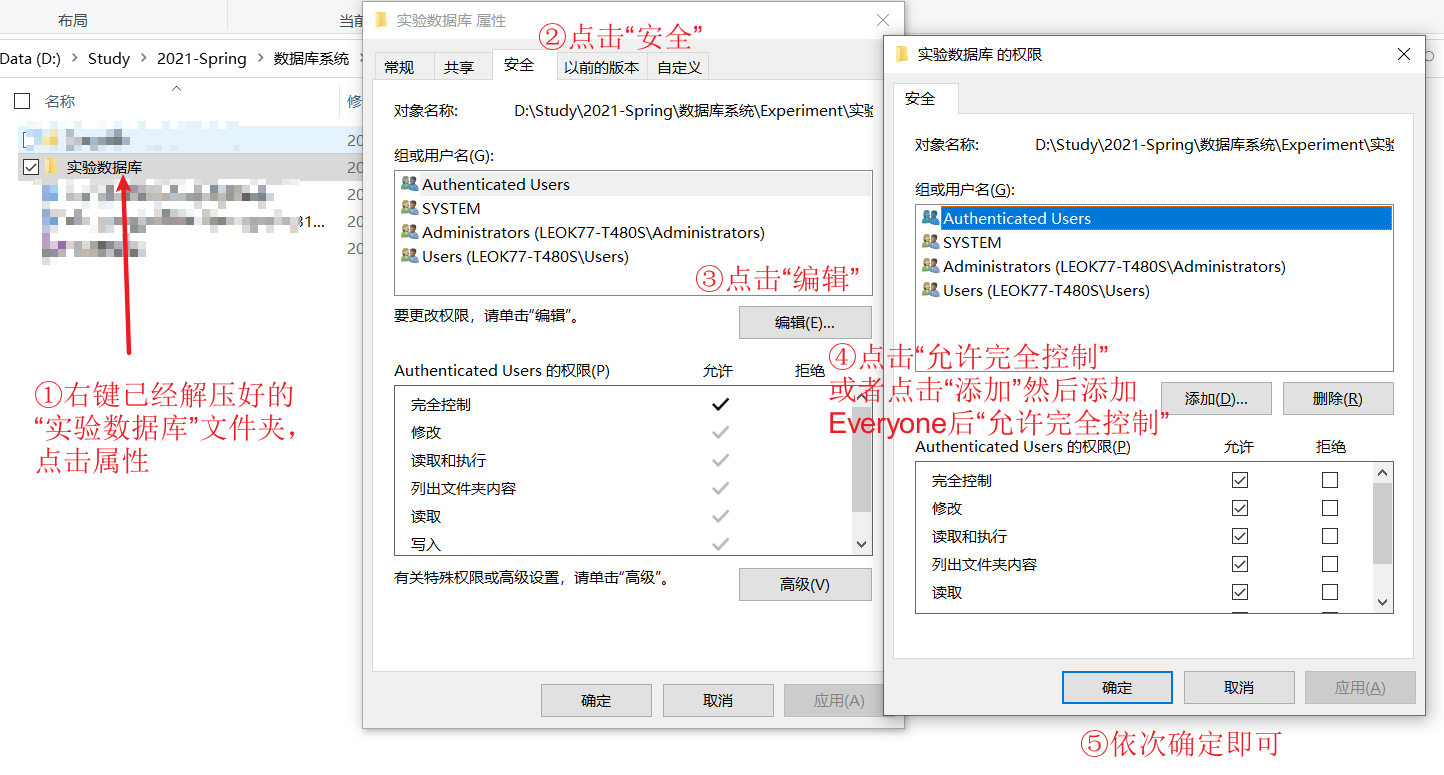
在DataGrip的console或者SSMS的查询中执行如下语句:
EXEC sp_attach_db @dbname = 'School',
@filename1 = N'D:\Study\2021-Spring\数据库系统\Experiment\实验数据库\School_Data.MDF',
@filename2 = N'D:\Study\2021-Spring\数据库系统\Experiment\实验数据库\School_Log.LDF'
- 其中:
- dbname即数据库名称,可以自己改
- filename1和filename2分别是mdf和ldf文件的路径,替换为自己的路径即可
如果使用的是DataGrip,可能还需要使导入的数据库可见,参照前面的"配置DataGrip"中的介绍即可。
实验内容
本节内容主要是对数据库进行查询操作,包括如下4类查询方式:
- 单表查询
- 查询的目标表达式为所有列、指定列或指定列的运算
- 使用DISTINCT保留字消除重复行
- 对查询结果排序和分组
- 集合分组使用集函数进行各项统计
- 连接查询
- 笛卡尔连接和等值连接
- 自连接
- 外连接
- 复合条件连接
- 多表连接
- 嵌套查询
- 通过实验验证对子查询的两个限制条件
- 体会相关子查询和不相关子查询的不同
- 考察4类谓词的用法,包括:
- 第1类:IN,NOT IN
- 第2类:带有比较运算符的子查询
- 第3类:SOME, ANY或ALL谓词的子查询
- 第4类:带有EXISTS谓词的子查询
- 集合运算
- 使用保留字UNION进行集合或运算
- 采用逻辑运算符AND或OR来实现集合交和减运算
实验步骤
以School数据库为例,在该数据库中存在4张表格,分别为:
STUDENTS(sid, sname, email, grade)
TEACHERS(tid, tname, email, salary)
COURSES(cid, cname, hour)
CHOICES(no, sid, tid, cid, score)
在数据库中,存在这样的关系:学生可以选择课程。一个课程对应一个教师。在表CHOICES中保存学生的选课记录
(1)查询年级为2001的所有学生的名称,按编号升序排列
SELECT sname
FROM STUDENTS
WHERE grade = 2001
ORDER BY sid;
(2)查询学生的选课成绩合格的课程成绩,并把成绩换算为绩点(60分对应绩点为1,每增加1,绩点增加1)
SELECT score - 60 + 1
FROM CHOICES
WHERE score >= 60;
-- SELECT score - 59
-- FROM CHOICES
-- WHERE score >= 60;
(3)查询课时是48或64的课程的名称
SELECT cname
FROM COURSES
WHERE hour IN (48, 64);
(4)查询所有课程名称中含有data的课程编号
SELECT cid
FROM COURSES
WHERE cname LIKE '%data%';
(5)查询所有选课记录的课程号(不重复显示)
SELECT DISTINCT cid
FROM CHOICES;
(6)统计所有老师的平均工资
SELECT AVG(salary)
FROM TEACHERS;
(7)查询所有学生的编号、姓名和平均成绩,按总平均成绩降序排列
SELECT STUDENTS.sid, sname, AVG(score) 'AVG-SCORE'
FROM STUDENTS,
CHOICES
WHERE STUDENTS.sid = CHOICES.sid
GROUP BY STUDENTS.sid, sname
ORDER BY AVG(score) DESC;
(8)统计各个课程的选课人数和平均成绩
SELECT cid, COUNT(DISTINCT sid) 'COUNT-PEOPLE', AVG(score) 'AVG-SCORE'
FROM CHOICES
GROUP BY cid;
(9)查询至少选修了三门课程的学生编号
SELECT sid
FROM CHOICES
GROUP BY sid
HAVING COUNT(DISTINCT cid) >= 3;
(10)查询编号为800009026的学生所选的全部课程的课程名和成绩
SELECT cname, score
FROM COURSES,
CHOICES
WHERE COURSES.cid = CHOICES.cid
AND CHOICES.sid = '800009026';
(11)查询所有选了database的学生的编号
SELECT sid
FROM COURSES,
CHOICES
WHERE COURSES.cname = 'database'
AND COURSES.cid = CHOICES.cid;
SELECT sid
FROM CHOICES
WHERE cid IN (
SELECT COURSES.cid
FROM COURSES
WHERE cname = 'database'
);
(12)求出选择了同一个课程的学生对
SELECT DISTINCT FIRST.sid, SECOND.sid
FROM CHOICES FIRST,
CHOICES SECOND
WHERE FIRST.sid != SECOND.sid
AND FIRST.cid = SECOND.cid;
(13)求出至少被两名学生选修的课程编号
SELECT cid
FROM CHOICES
GROUP BY cid
HAVING COUNT(DISTINCT sid) >= 2;
(14)查询选修了编号为80009026的学生所选的某个课程的学生编号
SELECT sid
FROM CHOICES
WHERE cid IN (
SELECT cid
FROM CHOICES
WHERE sid = '800009026'
);
(15)查询学生的基本信息及选修课程编号和成绩
SELECT STUDENTS.*, CHOICES.cid, CHOICES.score
FROM STUDENTS,
CHOICES
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4381
4381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









