



Hadoop2.7.2全分布式平台部署+Hive2.3.3+Spark2.4.3
基础配置
注意:全部服务器都需要执行以下操作
创建用户和用户组
sudo groupadd hadoop
mkdir -p /home/hadoop
sudo useradd hadoop -d /home/hadoop/hadoop -g hadoop -s /bin/bash
echo 'hadoop:hadoop' | chpasswd
为普通用户设置权限
chmod u+w /etc/sudoers
echo "hadoop ALL=(ALL) ALL" >> /etc/sudoers
echo "hadoop ALL=(ALL:ALL) NOPASSWD: NOPASSWD: ALL" >> /etc/sudoers
chmod u-w /etc/sudoers
设置主机名
vi /etc/hostname
master
保存退出
bash
关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
更改时区
echo "TZ='Asia/Shanghai'; export TZ" >> /etc/profile && source /etc/profile
yum install -y ntp
vi /etc/ntp.conf
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server 127.127.1.0
fudge 127.127.1.0 stratum 10
systemctl start ntpd.service
添加映射
vi /etc/hosts
master_ip master
slave1_ip slave1
slave2_ip slave2
宿主机互相免密通信
ssh-keygen -t rsa
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
将三台宿主机的的公钥相互复制
chmod 700 .ssh && chmod 600 .ssh/authorized_keys
设置文件权限
sudo chown -R hadoop:hadoop /opt
注意:以下全部操作默认hadoop用户下执行,如需root用户操作时,会有提示
配置java
mkdir -p /opt/java
解压
tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt/java
环境变量(root用户下执行)
vi /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_221
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
source /etc/profile
检查java是否配置成功
java -version

安装Hadoop2.7.2
注意:只需主服务器需要执行以下操作
解压
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/hadoop/
环境变量(root用户下执行)
vi /etc/profile
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.2
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
配置hadoop-env.sh文件
echo "export JAVA_HOME=/opt/java/jdk1.8.0_221" >> hadoop-env.sh
配置core-site.xml文件
<!--默认的主机名和端口号-->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<!--临时数据的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/hadoop-2.7.2/tmp</value>
</property>
<!--SNN检查NN日志时间间隔(单位为秒)-->
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<!--缓冲区大小-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--设置日志文件大小为64M-->
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
配置hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.http.address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hadoop-2.7.2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/hadoop-2.7.2/tmp/dfs/data</value>
</property>
<!--定义HDFS对应的HTTP服务器地址和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9031</value>
</property>
<!--开启webhdfs,允许文件的访问修改等操作-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
配置mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml && vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置yarn-site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>32768</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--RM提供的管理员访问地址,向RM发送管理命令等-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8040</value>
</property>
<!--RM提供给ApplicationMster的访问地址,AM通过该地址向RM申请资源、释放资源等-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<!--RM对web服务提供地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
<!--RM提供NodeManager地址, 通过该地址向RM心跳、领取任务等-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.min-healthy-disks</name>
<value>0.0</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>80.0</value>
</property>
配置yarn-env.sh文件
echo "export JAVA_HOME=/opt/java/jdk1.8.0_221" >> yarn-env.sh
配置msater、slaves文件
echo master >> master && echo slave1 >> slaves && echo slave2 >> slaves
传输-格式化-启动
将安装目录传输到从节点
scp -r /opt/hadoop/hadoop-2.7.2 hadoop@slave1:/opt/hadoop/
scp -r /opt/hadoop/hadoop-2.7.2 hadoop@slave2:/opt/hadoop/
在主节点执行格式化
hdfs namenode -format
在主节点执行启动
start-all.sh
stop-all.sh
jps

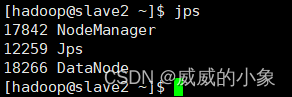
注意:以下所有相关内容全部都是在主节点配置
安装mysql
下载安装(root用户下)
yum -y install epel-release && yum -y install wget
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
rpm -ivh mysql57-community-release-el7-9.noarch.rpm
yum -y install mysql-community-client --nogpgcheck
yum -y install mysql-community-common --nogpgcheck
yum -y install mysql-community-libs --nogpgcheck
yum -y install numactl-libs --nogpgcheck
yum -y install mysql-community-server --nogpgcheck
yum -y install mariadb-server
sudo systemctl daemon-reload
sudo systemctl start mysqld
sudo systemctl status mysqld
配置mysql信息
grep 'password' /var/log/mysqld.log
mysql -u root -p
修改密码
set global validate_password_policy=0;
set global validate_password_length=1;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
设置hadoop用户权限
create user 'hadoop'@'localhost' identified by 'hadoop';
grant all privileges on *.* to 'hadoop'@'localhost' with grant option;
grant all privileges on *.* to 'hadoop'@'localhost' identified by 'hadoop' with grant option;
flush privileges;
部署Hive2.3.3
基础配置
mkdir -p /opt/hive/
解压
tar -zxvf apache-hive-2.3.4-bin.tar.gz -C /opt/hive/
配置环境变量(root下)
vi /etc/profile
export HIVE_HOME=/opt/hive/apache-hive-2.3.3-bin
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
复制文件
cp mysql-connector-java-5.1.47-bin.jar /opt/hive/apache-hive-2.3.3-bin/lib
配置hive-site.xml
vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>system:java.io.tmpdir</name>
<value>/opt/hive/iotmp</value>
<description/>
</property>
<property>
<name>hive.files.umask.value</name>
<value>0002</value>
</property>
<property>
<name>hive.metastore.authorization.storage.checks</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.execute.setugi</name>
<value>false</value>
</property>
<property>
<name>hive.security.authorization.enabled</name>
<value>false</value>
</property>
<property>
<name>hive.security.authorization.task.factory</name>
<value>org.apache.hadoop.hive.ql.parse.authorization.HiveAuthorizationTaskFactoryImpl</value>
</property>
<property>
<name>hive.security.authorization.createtable.owner.grants</name>
<value>ALL</value>
</property>
<property>
<name>hive.users.in.admin.role</name>
<value>hadoop</value>
</property>
<property>
<name>datanucleus.shcema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
</configuration>
编译-启动
schematool -dbType mysql -initSchema
mkdir -p /opt/hive/apache-hive-2.3.3-bin/logs
后台启动
nohup hive --service metastore > /opt/hive/apache-hive-2.3.3-bin/logs/meta.log 2>&1 &
nohup hive --service hiveserver2 > /opt/hive/apache-hive-2.3.3-bin/logs/hiveserver2.log 2>&1 &
查看运行情况
jps
部署Spark2.4.3
基础配置
mkdir -p /opt/spark/
解压
tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz -C /opt/spark/
配置环境变量(root下)
vi /etc/profile
export SPARK_HOME=/opts/spark/spark-2.4.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
配置spark-env.sh文件
export JAVA_HOME=/opt/java/jdk1.8.0_221
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/hadoop-2.7.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=spark
修改yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
传输jar包
cp /opt/spark/spark-2.4.3-bin-hadoop2.7/yarn/spark-2.4.3-yarn-shuffle.jar /opt/hadoop/hadoop-2.7.2/share/hadoop/yarn/lib/
启动spark
chmod +x bin/*
chmod +x sbin/*
在spark2.3.4下
sh sbin/start-all.sh
sh sbin/stop-all.sh
运行结果如下:

部署Sprk on Hive(参考一下内容)
1.hive-site.xml添加一下信息
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
2.hive-site.xml拷贝至spark的conf目录
3.hadoop目录下的core-site.xml与hdfs-site.xml拷贝至spark下的conf
4.hive的lib目录下的mysql-connector-java-5.1.47-bin.jar拷贝至spark的jars
关闭hive和spark服务重新启动
5.nohup hive --service metastore > /opt/hive/apache-hive-2.3.3-bin/logs/meta.log 2>&1 &
nohup hive --service hiveserver2 > /opt/hive/apache-hive-2.3.3-bin/logs/hiveserver2.log 2>&1 &
6.spark-sql

















 3428
3428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









