







今天学习Python,学到了两个很好用的函数:to_period()和agg()。
to_period()是提取时间的函数,可以按年、月、日等。
agg()是对数据做聚合操作,可以按意愿填写想要的聚合函数,比如min, max, median等。
具体怎么用还是看例子吧,一清二楚。
首先导入库,并建立一个获取一段时间的函数。
import numpy as np
import pandas as pd
import datetime
def getDateList(start_date, end_date):
date_list = []
start_date = datetime.datetime.strptime(start_date, '%Y-%m-%d')
end_date = datetime.datetime.strptime(end_date, '%Y-%m-%d')
date_list.append(start_date.strftime('%Y-%m-%d'))
while start_date < end_date:
start_date += datetime.timedelta(days=1)
date_list.append(start_date.strftime('%Y-%m-%d'))
return date_list构造一个数据框,包含日期和次数两列。
date_list = getDateList("2021-10-15","2022-02-15")
rndint = np.random.randint(1, 100, len(date_list))
df = pd.DataFrame(np.c_[date_list, rndint], columns=['DATE', 'CNT'])
df.head()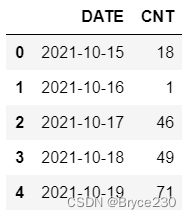
更改两列的数据格式,DATE列改为datetime,CNT列改为int。
df['DATE'] = pd.to_datetime(df['DATE'])
df['CNT'] = df['CNT'].astype(int)
df.info()
将DATE列设为索引。
df_new = df.set_index('DATE', drop=True)
df_new.head()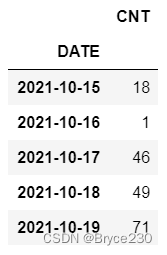
基于to_period()和groupby()函数按 日 聚合。(按日聚合其实就是原始数据)
df_new.groupby(df_new.index.to_period("D")).mean()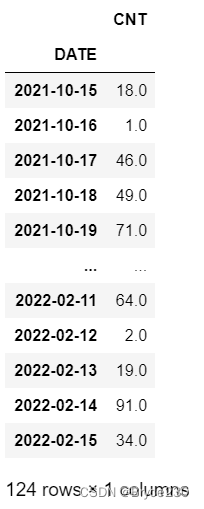
基于to_period()和groupby()函数按 周 聚合。
df_new.groupby(df_new.index.to_period("W")).mean()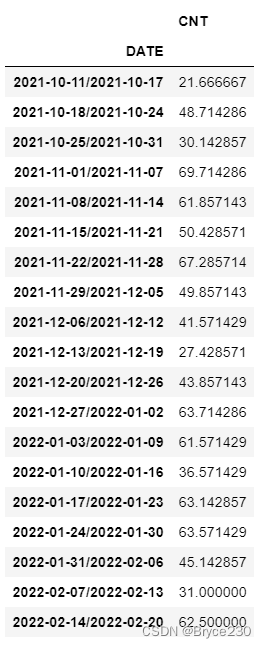
基于to_period()和groupby()函数按 月 聚合。
df_new.groupby(df_new.index.to_period("M")).mean()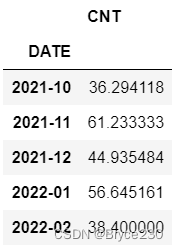
基于to_period()和groupby()函数按 年 聚合。(Y改为A也可以)
df_new.groupby(df_new.index.to_period("Y")).mean()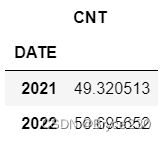
基于agg()函数求最大值、最小值、平均值等。
df_new.groupby(df_new.index.to_period("M")).agg(['min','max','mean','std','median'])
最后,欢迎大家关注我的WX公众号:且听数据说,更多内容与你分享,期待相遇。

















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









