







 本文介绍了Python的基础知识,包括字典的定义、创建、操作和内置函数,集合的创建与方法,以及文件的读取操作,特别讨论了如何对Excel和CSV文件进行操作。
本文介绍了Python的基础知识,包括字典的定义、创建、操作和内置函数,集合的创建与方法,以及文件的读取操作,特别讨论了如何对Excel和CSV文件进行操作。
【Datawhale | python基础 | Day3】字典/集合/文件读取
1、字典dict
1.1 字典定义
- 字典是另一种可变容器模型,且可存储任意类型对象
- 字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示
dict = { key1:value1, key2:value2 } - 键一般是唯一的,如果重复最后的一个键值对会替换前面的,且键必须是不可变的,如字符串,数字或元组,但不可以是列表
- 值不需要唯一, 值可以取任何数据类型
1.2 创建字典
print('--------1、字典-------','\n')
print('--------1.2、创建字典-------')
dict0 = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
dict1 = { 'abc': 456 }
dict2 = { 'abc': 123, 98.6: 37 }
print('\n','dict0=',dict0,'\n','dict1=',dict1,'\n','dict2=',dict2,'\n')
"""
运行结果:
dict0= {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
dict1= {'abc': 456}
dict2= {'abc': 123, 98.6: 37}
"""
1.3 相关操作
- 访问字典:把相应的键放入到方括号中
- 修改字典:向字典添加新内容的方法是增加新的键/值对
- 删除字典元素:能删单一的元素也能清空字典,清空只需一项操作,删除一个字典用del命令
print('--------1.3、相关操作-------','\n')
print('--------1)访问字典-------','\n')
print('dict0[''Name'']:',dict0['Name'])
print('dict2[98.6]:',dict2[98.6])
"""
运行结果:
dict0[Alice]: 2341
dict2[98.6]: 37
"""
print('\n','--------2)修改字典-------','\n')
dict0['Age'] = 8; # 更新 Age
dict0['School'] = "菜鸟教程" # 添加信息
print('修改后的字典为:',dict0,'\n')
"""
修改后的字典为: {'Name': 'Runoob', 'Age': 8, 'Class': 'First', 'School': '菜鸟教程'}
"""
print('\n','--------3)删除字典-------','\n')
del dict0['Name'] # 删除键 'Name'
print('删除Name后的字典为:',dict0,'\n')
dict0.clear() # 清空字典
print('清空字典之后:',dict0,'\n')
del dict0 # 删除字典
# print('删除字典之后:',dict0,'\n')
"""
删除Name后的字典为: {'Age': 8, 'Class': 'First', 'School': '菜鸟教程'}
清空字典之后: {}
--------------删除字典之后,再次打印会报以下错误-------------------
NameError Traceback (most recent call last)
<ipython-input-19-c38418ac07a7> in <module>
37 print('清空字典之后:',dict0,'\n')
38 del dict0 # 删除字典
---> 39 print('删除字典之后:',dict0,'\n')
NameError: name 'dict0' is not defined
"""
1.4 内置函数和方法
1)内置函数
- len(dict):计算字典元素个数,即键的总数
- str(dict):输出字典,以可打印的字符串表示
- type(variable):返回输入的变量类型,如果变量是字典就返回字典类型
print('--------1.4、内置函数和方法-------','\n')
print('--------1)内置函数-------','\n')
dict0 = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print('计算字典元素个数,即键的总数:', len(dict0))
print('以字符串输出字典,:', str(dict0))
print('返回输入的变量类型:',type(dict0),'\n')
"""
运行结果:
计算字典元素个数,即键的总数: 3
以字符串输出字典,: {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
返回输入的变量类型: <class 'dict'>
"""
2)相关方法
- dict.clear():删除字典内所有元素
- dict.copy():返回一个字典的浅复制
- fromkeys():创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
- dict.get(key, default=None):返回指定键的值,如果值不在字典中返回default值
- key in dict:如果键在字典dict里返回true,否则返回false
- dict.items():以列表返回可遍历的(键, 值) 元组数组
- dict.keys():返回一个迭代器,可以使用 list() 来转换为列表
- dict.setdefault(key, default=None):和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
- dict.update(dict2):把字典dict2的键/值对更新到dict里
- dict.values():返回一个迭代器,可以使用 list() 来转换为列表
- pop(key[,default]):删除字典给定键 key 所对应的值,返回值为被删除的值,key值必须给出,否则返回default值
- popitem():随机返回并删除字典中的一对键和值(一般删除末尾对)
print('--------2)相关方法-------','\n')
#### clear()######
print ("字典长度 : %d" % len(dict0))
dict0.clear()
print ("字典删除后长度 : %d" % len(dict0))
"""
运行结果:
字典长度 : 3
字典删除后长度 : 0
"""
#### dict.copy() ######
dict1 = {'user':'runoob','num':[1,2,3]}
dict2 = dict1.copy()
print ("新复制的字典为 : ",dict2)
dict2 = dict1 # 浅拷贝: 引用对象
dict3 = dict1.copy() # 浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
# 修改 data 数据
dict1['user']='root'
dict1['num'].remove(1)
# 输出结果
print(dict1)
print(dict2)
print(dict3)
"""
运行结果:
新复制的字典为 : {'user': 'runoob', 'num': [1, 2, 3]}
{'user': 'root', 'num': [2, 3]}
{'user': 'root', 'num': [2, 3]}
{'user': 'runoob', 'num': [2, 3]}
"""
#### dict.fromkeys(seq[, value]) ######
seq = ('name', 'age', 'sex')
dict4 = dict.fromkeys(seq)
print ("新的字典为 : %s" % str(dict4))
dict5 = dict.fromkeys(seq, 10)
print ("新的字典为 : %s" % str(dict5))
"""
运行结果:
新的字典为 : {'name': None, 'age': None, 'sex': None}
新的字典为 : {'name': 10, 'age': 10, 'sex': 10}
"""
# # dict.get(key, default=None)
print ("age 值为 : %s" % dict5.get('age'))
print ("Sex 值为 : %s" % dict5.get('Sex'))
"""
运行结果:
age 值为 : 10
Sex 值为 : None
"""
## key in dict
dict = {'Name': 'Runoob', 'Age': 7}
# 检测键 Age 是否存在
if 'Age' in dict:
print("键 Age 存在")
else :
print("键 Age 不存在")
# 检测键 Sex 是否存在
if 'Sex' in dict:
print("键 Sex 存在")
else :
print("键 Sex 不存在")
# not in
# 检测键 Age 是否存在
if 'Age' not in dict:
print("键 Age 不存在")
else :
print("键 Age 存在")
"""
运行结果:
键 Age 存在
键 Sex 不存在
键 Age 存在
"""
### dict.items()
print ("Value : %s" % dict.items())
"""
运行结果:
Value : dict_items([('Name', 'Runoob'), ('Age', 7)])
"""
## dict.keys()
print(dict.keys())
print(list(dict.keys())) # 转换成列表
"""
运行结果:
dict_keys(['Name', 'Age'])
['Name', 'Age']
"""
## dict.setdefault(key, default=None)
print ("Age 键的值为 : %s" % dict.setdefault('Age', None))
print ("Sex 键的值为 : %s" % dict.setdefault('Sex', None))
print ("新字典为:", dict)
"""
运行结果:
Age 键的值为 : 7
Sex 键的值为 : None
新字典为: {'Name': 'Runoob', 'Age': 7, 'Sex': None}
"""
### dict.update(dict2)
dict = {'Name': 'Runoob', 'Age': 7}
dict2 = {'Sex': 'female' }
dict.update(dict2)
print ("更新字典 dict : ", dict)
"""
运行结果:
更新字典 dict : {'Name': 'Runoob', 'Age': 7, 'Sex': 'female'}
"""
### dict.values()
dict = {'Sex': 'female', 'Age': 7, 'Name': 'Zara'}
print ("字典所有值为 : ", list(dict.values()))
"""
运行结果:
字典所有值为 : ['female', 7, 'Zara']
"""
## pop(key[,default])
pop_obj = dict.pop('Name') #返回值为被删除的值
print(pop_obj)
"""
运行结果:
Zara
"""
## dict.popitem()
pop_obj = dict.popitem() #随机返回
print(pop_obj)
"""
运行结果:
('Age', 7)
"""
2、集合
2.1 集合定义
- 集合(set)是一个无序的不重复元素序列。
- 可以使用大括号 { } 或者 set() 函数创建集合
- 创建一个空集合,必须用 set() 而不是 { },因为 { } 是用来创建一个空字典
2.2 创建集合
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 这里演示的是去重功能
# {'orange', 'banana', 'pear', 'apple'}
print('orange' in basket) # 快速判断元素是否在集合内
# True
print('crabgrass' in basket)
# False
# 下面展示两个集合间的运算.
a = set('abracadabra')
b = set('alacazam')
print(a)
print(b)
print(a - b) # 集合a中包含而集合b中不包含的元素
print(a | b) # 集合a或b中包含的所有元素
print(a & b) # 集合a和b中都包含了的元素
print(a ^ b) # 不同时包含于a和b的元素
2.3 相关方法
-
添加元素
s.add( x ):将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
s.update( x ): 添加元素,且参数可以是列表,元组,字典等,x 可以有多个,用逗号分开。 -
移除元素
s.remove( x ):将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
s.discard( x ):移除集合中的元素,且如果元素不存在,不会发生错误
s.pop():随机删除集合中的一个元素 -
计算集合 s 元素个数
len(s):计算集合 s 元素个数 -
清空集合
s.clear():清空集合 -
判断元素 x 是否在集合 s 中
x in s:判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False -
其他方法
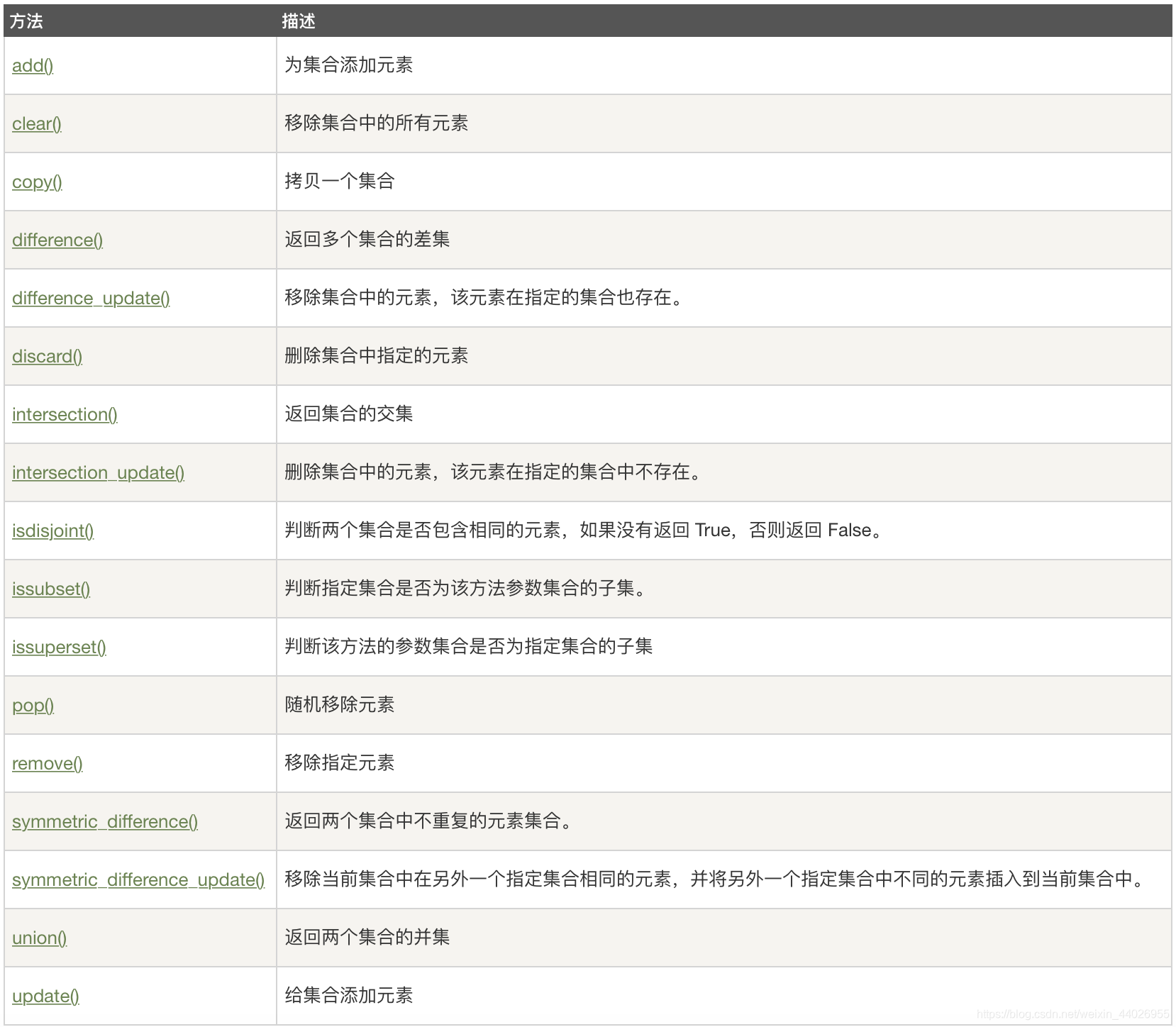
3.file文件读取
3.1 打开文件(读写两种方式)
1)读文件
- open() 方法:用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError
- 使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法
- open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)
open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式,默认为文本格式,其他格式可参见链接
http://www.runoob.com/python3/python3-file-methods.html - buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 默认None
# 文件操作第一种方法
file = open('homework.txt') #打开文件
file.read() #读文件
file.close() #关闭文件
# 文件操作第二种方法
with open('homework.txt', 'r') as f: # 打开文件
print(f.read())
with open('homework.txt', 'r') as f:
for line in f.readlines(): # 读取文件内容
print(line.strip()) # 把末尾的'\n'删掉
"""
运行结果:
python学习 咖喱 胡骞
leetcode刷题 老表 陈焕森
编程集训 孙超 小熊
统计学 李奇峰 蓝昔
ML项目实践 杨冰楠 孙涛
高级算法梳理 于鸿飞 小雪
基础算法梳理 sm1les 钱令武
知乎小组 李严 黑桃
学习群 咖喱 排骨
"""
2)写文件
- 写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符’w’或者’wb’表示写文本文件或写二进制文件
f = open('test.txt', 'w')
f.write('Hello, world!')
f.close()
3.2 操作方法

3.3 学习对excel及csv文件进行操作
4、任务打卡
读取一个文件【文件将在之后给出】,将文件中转换为字典,key值为学习项目,value值为一个负责人列表,并判断字典中是否有负责人负责多个学习项目。
### 生成负责人字典
dict1={}
with open('homework.txt', 'r') as f:
for line in f.readlines(): # 读取文件内容
word = line.strip() # 把末尾的'\n'删掉
key = word.split(' ')[0]
value = [word.split(' ')[1], word.split(' ')[2]]
dict1[key] = value
print(dict1)
"""
运行结果:
{'python学习': ['咖喱', '胡骞'], 'leetcode刷题': ['老表', '陈焕森'], '编程集训': ['孙超', '小熊'], '统计学': ['李奇峰', '蓝昔'], 'ML项目实践': ['杨冰楠', '孙涛'], '高级算法梳理': ['于鸿飞', '小雪'], '基础算法梳理': ['sm1les', '钱令武'], '知乎小组': ['李严', '黑桃'], '学习群': ['咖喱', '排骨']}
"""
### 判断字典中是否有负责人负责多个学习项目
dict2 = {}
for i,v in dict1.items():
for j in v:
if dict2.get(j) is None:
dict2[j] = 1
else:
dict2[j] += 1
print(dict2)
for i,v in dict2.items():
if v >1:
print('负责多个项目的负责人有:', i)
"""
运行结果:
{'咖喱': 2, '胡骞': 1, '老表': 1, '陈焕森': 1, '孙超': 1, '小熊': 1, '李奇峰': 1, '蓝昔': 1, '杨冰楠': 1, '孙涛': 1, '于鸿飞': 1, '小雪': 1, 'sm1les': 1, '钱令武': 1, '李严': 1, '黑桃': 1, '排骨': 1}
负责多个项目的负责人有: 咖喱
"""


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









