







Zookeeper介绍
Zookeeper是Apache Hadoop项目下的一个子项目,是一个树形目录服务。
Zookeeper是一个分布式的、开源的分布式应用程序的协调服务。
Zookeeper提供的主要功能包括:
- 配置管理
- 分布式锁
- 集群管理
Zookeeper数据模型

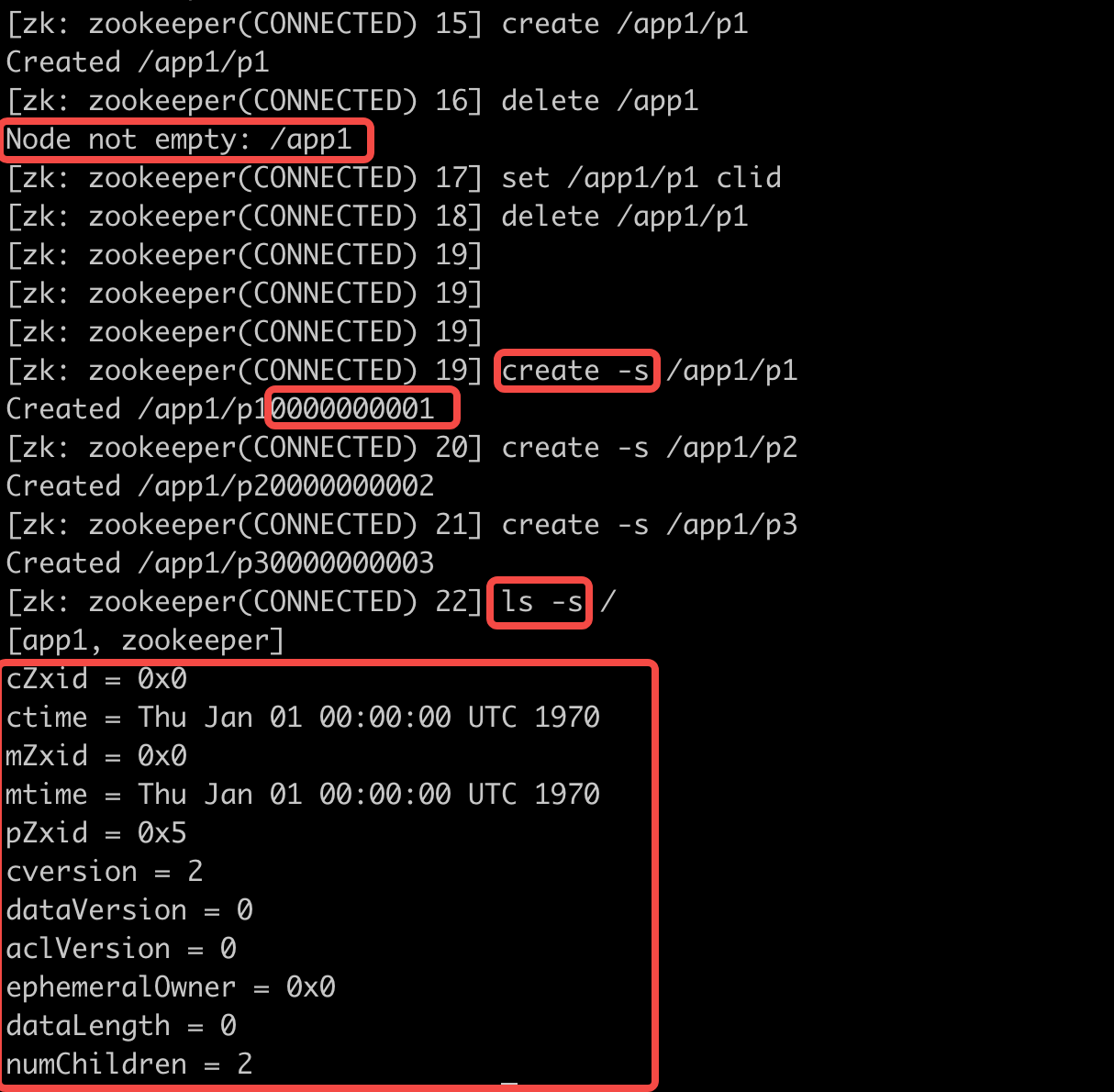
Zookeeper客户端常用命令


操作练习
JavaAPI操作 - Curator介绍
Curator是Apache Zookeeper的Java客户端
常见的Zookeeper Java API:
- 原生Java API
- ZkClient
- Curator
Curator项目的目标是简化Zookeeper客户端的使用
Curator最初是Netfix研发的,后来捐献了Apache基金会,目前是Apache的顶级项目。
Curator API常用操作
Curator API常用操作 - Watch监听
- Zookeeper允许用户在指定节点上注册一些Watcher,并且在一定特定事件触发的时候,Zookeeper服务端会将时间通知到感兴趣的客户端上去,该机制是Zookeeper实现分布式协调服务的重要特性
- Zookeeper中引入了Watcher机制来实现了发布/订阅功能,能够让多个订阅者同时监听某一个对象,当一个对象自身状态变化时,会通知所有订阅者。
- Zookeeper原生支持通过注册Watcher来进行事件监听,但是其使用并不是特别方便,需要开发人员自己反复注册Watcher,比较繁琐
- Curator引入了Cache来实现对Zookeeper服务端事件的监听
- Zookeeper提供了3种Watcher:
- NodeCache:只监听某一个特定的节点
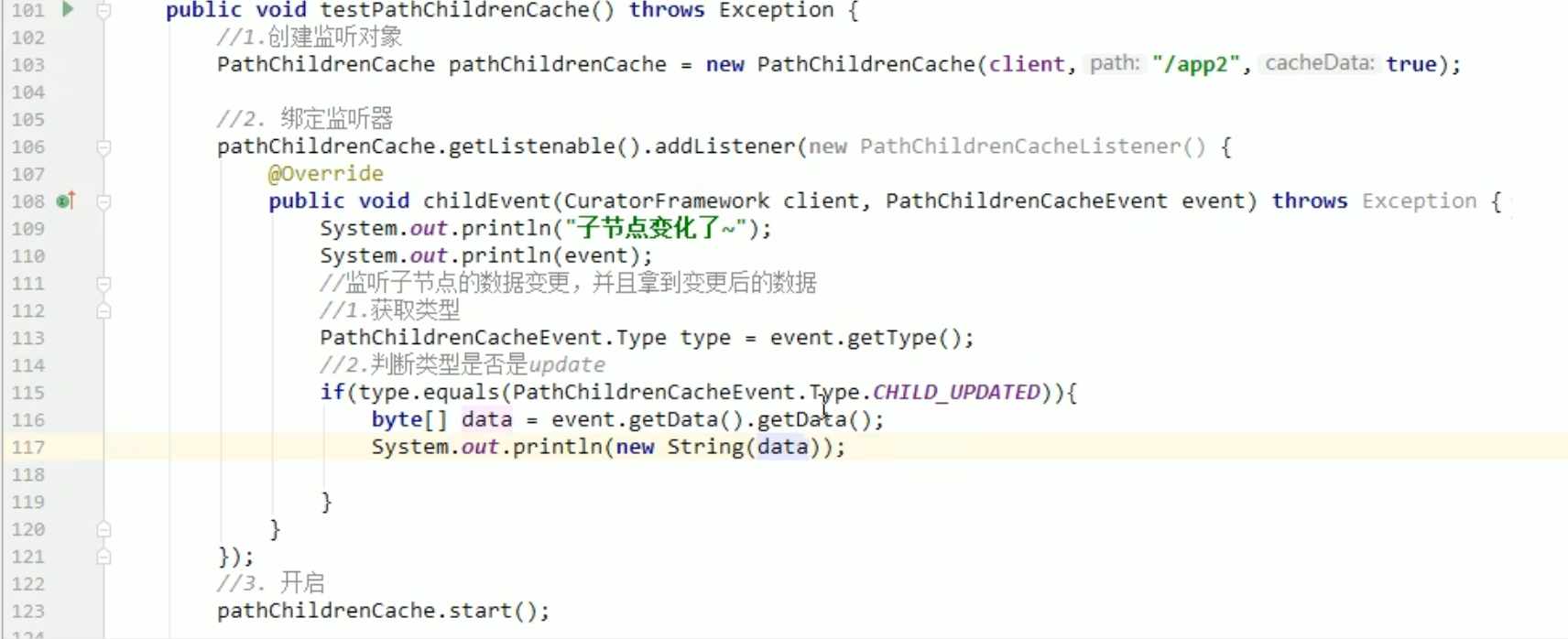
- PathChildrenCache:监听一个Znode的子节点
- TreeCache:可以监听整个树上的所有节点,类似于PathChildrenCache和NodeCache的组合
NodeCache练习:

PathChildrenCache练习:
TreeCache练习:
分布式锁
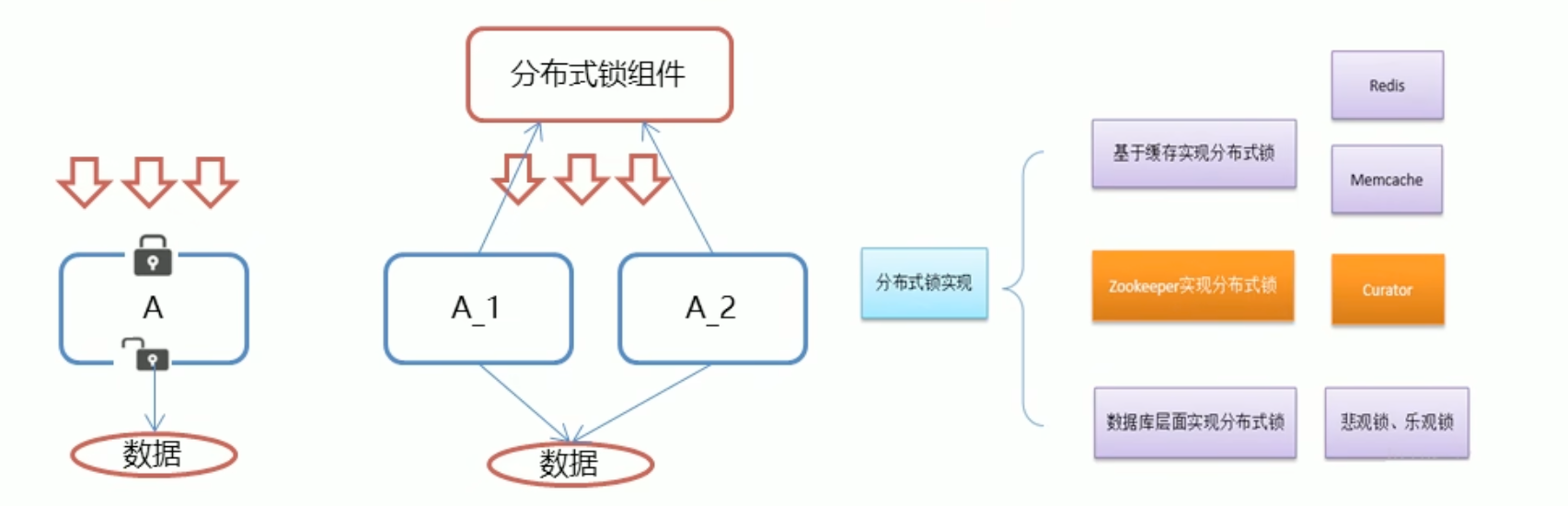
- 在我们进行单击应用开发,涉及并发同步的时候,我们往往采用synchronized或者Lock的方式解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVM下,没有任何问题。
- 但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。
- 那么就需要一种更加高级的锁机制,来处理这种跨机器的进程之间的数据同步问题 – 这就是分布式锁
zookeeper分布式锁原理
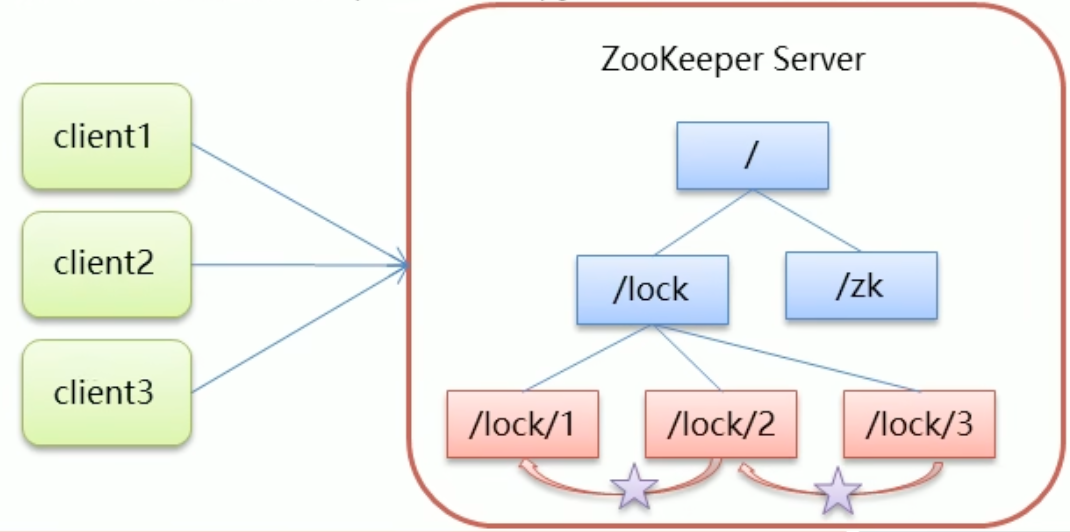
核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。
- 客户端获取锁时,在lock节点下创建临时顺序节点。
- 然后获取lock下面的所有子节点,客户端获取所有子节点之后,如果发现自己创建子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
- 如果发现自己创建的节点并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
- 如果发现比自己小的那个节点被删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是lock子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。
Curator实现分布式锁API
在Curator中有五种锁方案:
- InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
- InterProcessMutex:分布式可重入排它锁
- InterProcessReadWriteLock:分布式读写锁
- InterProcessMultiLock:将多个锁作为单个实体管理的容器
- InterProcessSemaphoreV2:共享信号量
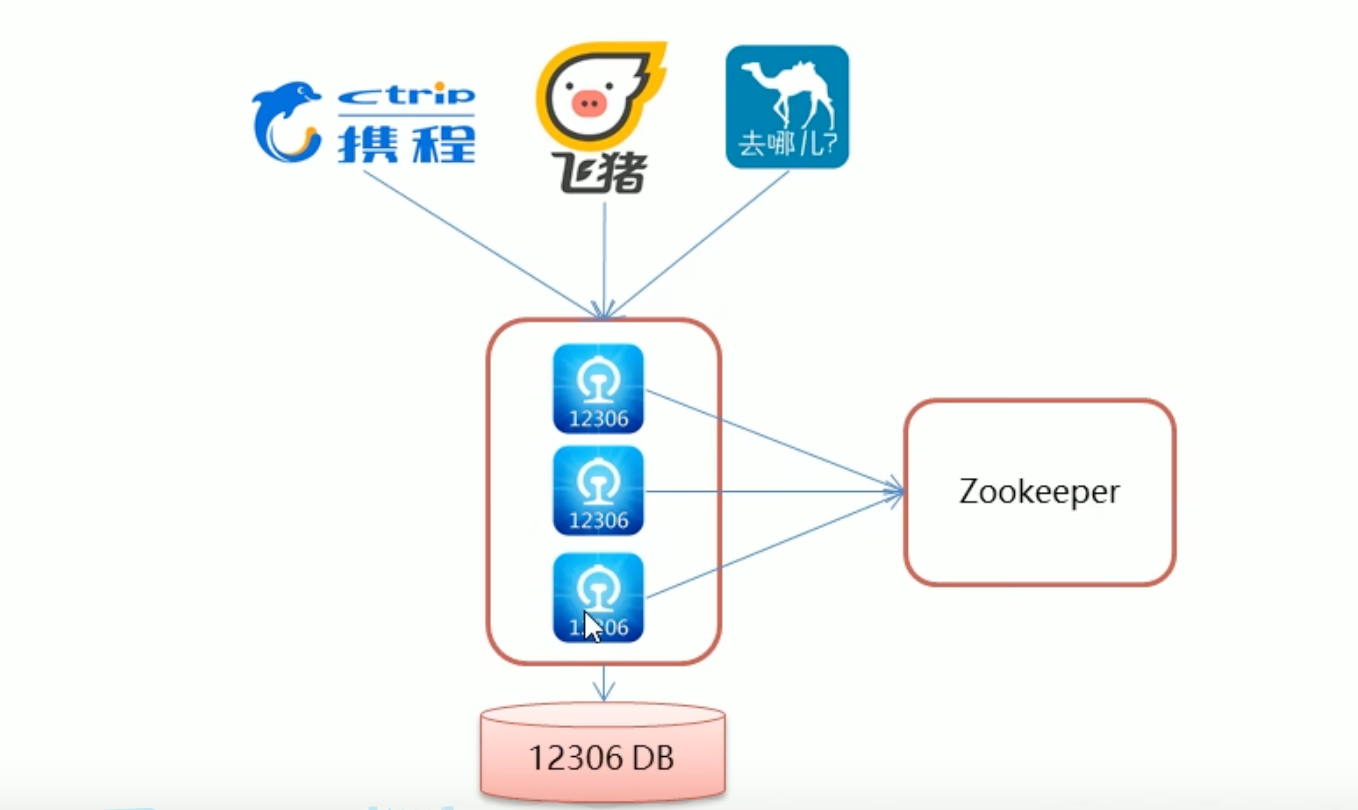
分布式锁案例 – 模拟12306售票
编码:
Ticket12306.java

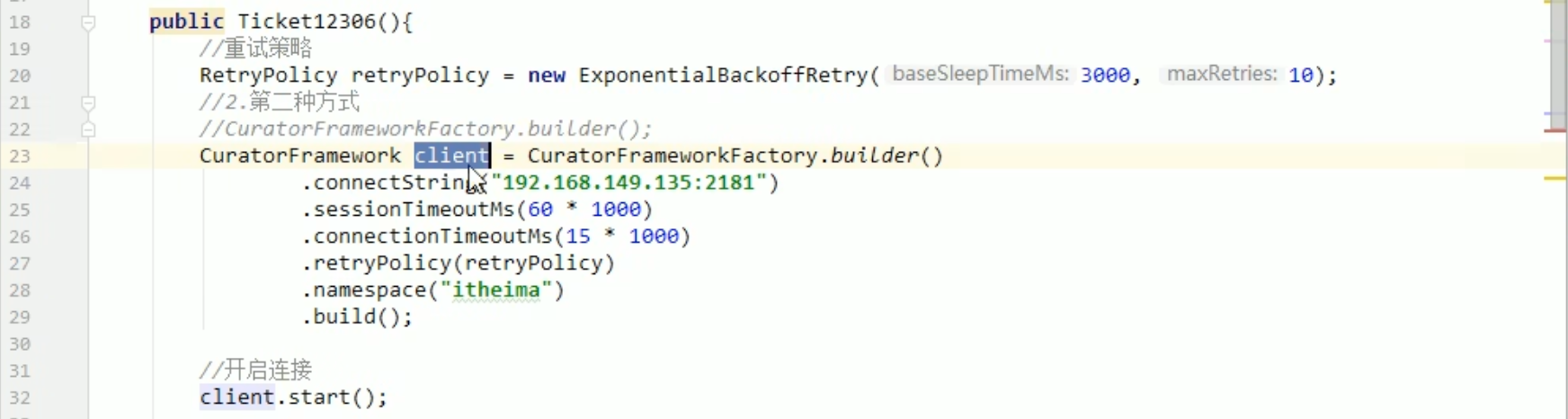


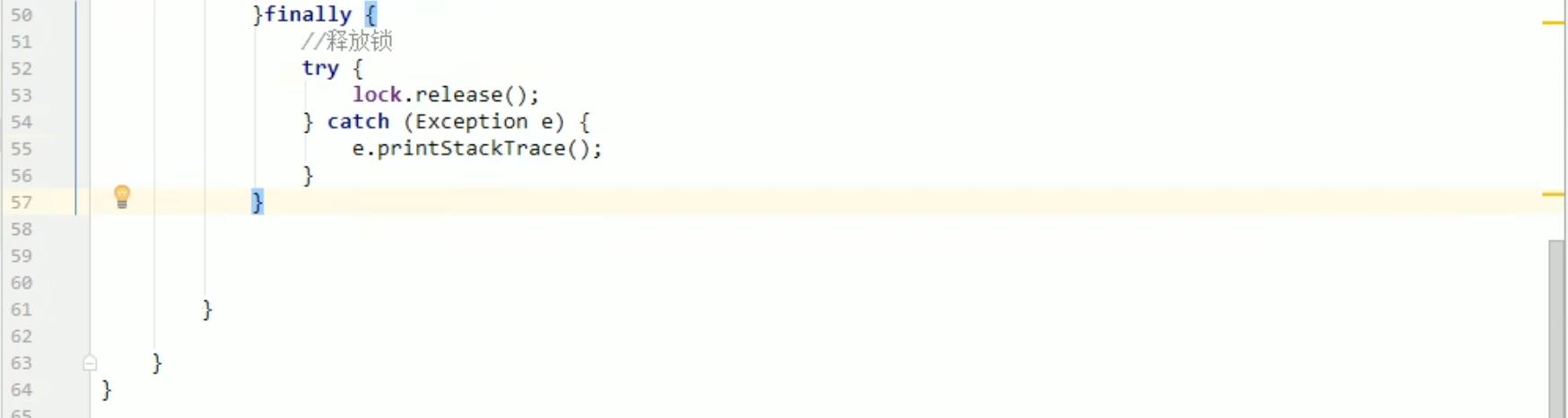
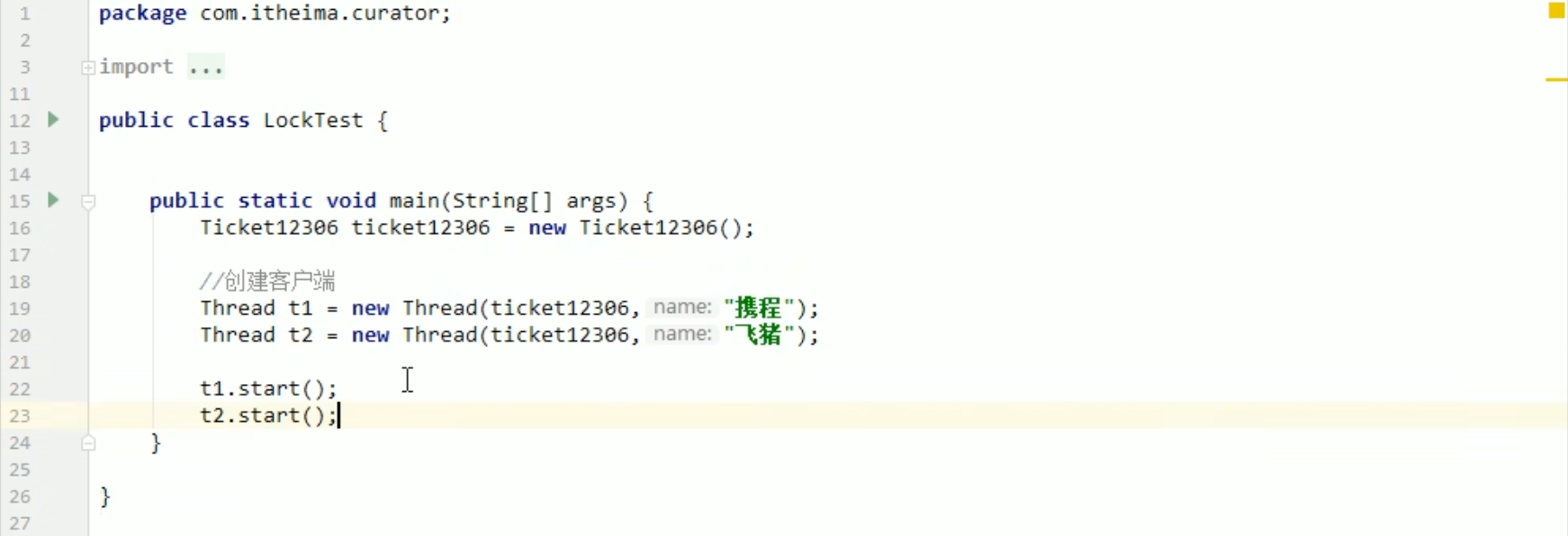
LockTest.java
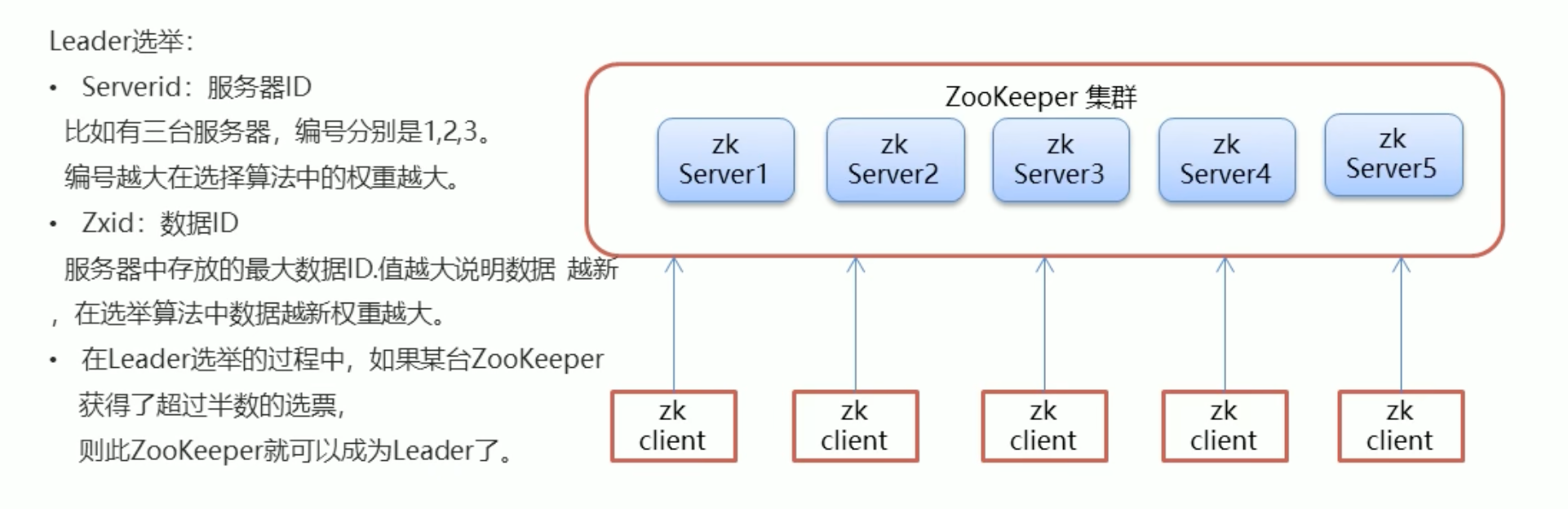
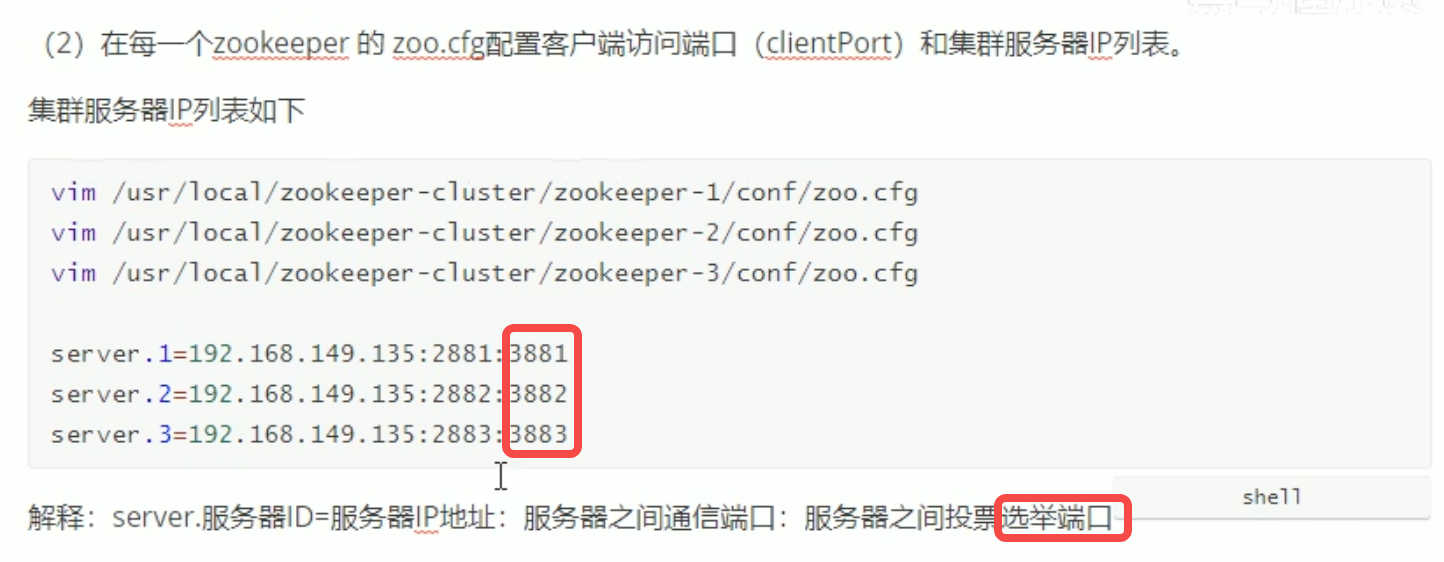
Zookeeper集群介绍
环境搭建关键配置
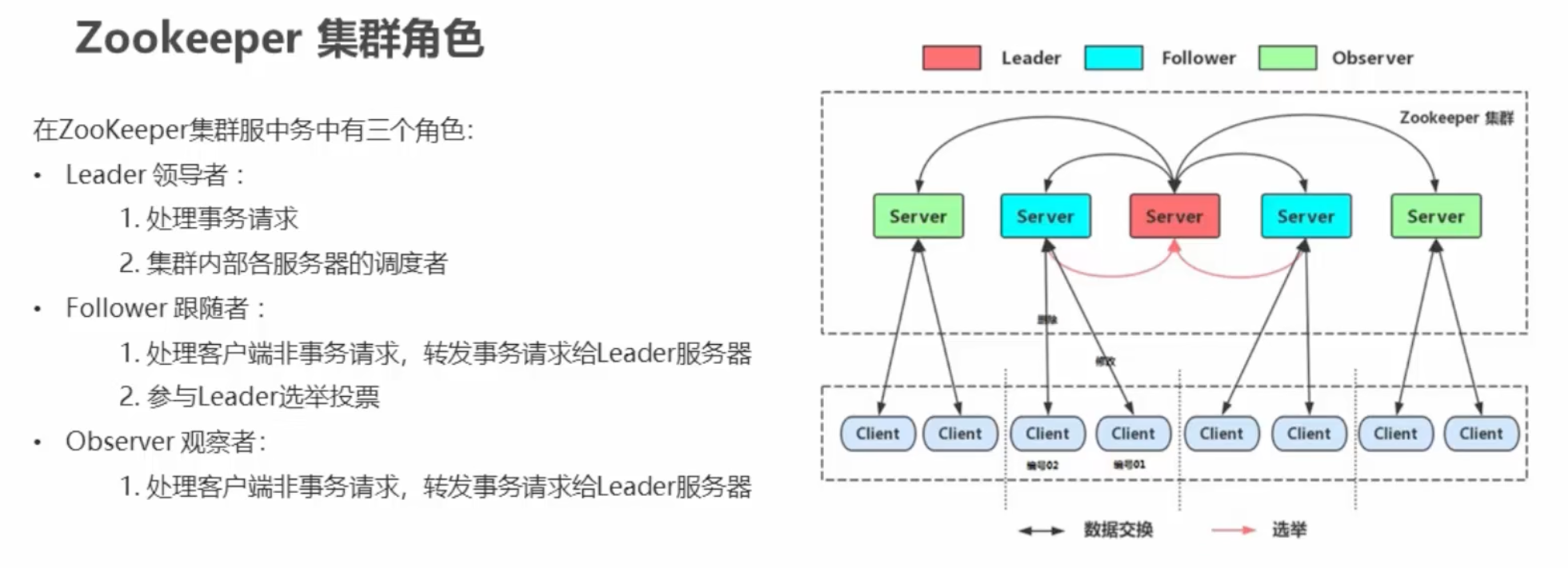
zookeeper集群角色

















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









