







 本文探讨了多种数据增强方法在计算机视觉任务中的应用,包括Max-drop, Cutout, Random Erasing等,以提高模型的鲁棒性和泛化能力。这些方法通过模拟遮挡、噪声等方式,避免过拟合,提升模型对图像变化的适应性。此外,还介绍了Mixup, CutMix等方法,通过融合多个样本信息来增强模型的训练效果。"
100703068,8571827,"Python数据分析库详解:Pandas, NumPy, SciPy与Matplotlib
本文探讨了多种数据增强方法在计算机视觉任务中的应用,包括Max-drop, Cutout, Random Erasing等,以提高模型的鲁棒性和泛化能力。这些方法通过模拟遮挡、噪声等方式,避免过拟合,提升模型对图像变化的适应性。此外,还介绍了Mixup, CutMix等方法,通过融合多个样本信息来增强模型的训练效果。"
100703068,8571827,"Python数据分析库详解:Pandas, NumPy, SciPy与Matplotlib
本篇博客是对计算机视觉任务中常见的几种基于单个样本进行数据增强的方法的一个总结,主要是给自己做一个笔记,如果有任何问题请大家指正(●ˇ∀ˇ●)
数据增强的作用
-
避免过拟合。当数据集具有某种明显的特征,例如数据集中图片基本在同一个场景中拍摄,使用Cutout方法和风格迁移变化等相关方法可避免模型学到跟目标无关的信息。
-
提升模型鲁棒性,降低模型对图像的敏感度。当训练数据都属于比较理想的状态,碰到一些特殊情况,如遮挡,亮度,模糊等情况容易识别错误,对训练数据加上噪声,掩码等方法可提升模型鲁棒性。
-
增加训练数据,提高模型泛化能力。
-
避免样本不均衡。在工业缺陷检测方面,医疗疾病识别方面,容易出现正负样本极度不平衡的情况,通过对少样本进行一些数据增强方法,降低样本不均衡比例。
方法一:Max-drop《Analysis on the Dropout Effect in Convolutional Neural Networks》
Max-drop方法发表于ACCV2016
论文链接:http://mipal.snu.ac.kr/images/archive/1/16/20190516013446%21Dropout_ACCV2016.pdf
代码链接:https://github.com/sungheonpark/Max-drop
1. 1 动机
由于遮挡、视角变化、光照变化等原因,同一类的不同图像往往不具有相同的特征。例如,人脸图像可能包含一只眼睛或两只眼睛,这取决于视点。因此,在一幅图像中起重要作用的特征可能不会出现在同一类的不同图像中。Max-drop旨在通过确定性地降低高激活来模拟这些情况,而不是随机选择降低激活。在卷积层的下层,这种降低最大激活的过程模拟了由于遮挡或其他类型的变化而导致重要特征不存在的情况。在较高层,每个特性映射学习更抽象和类特定的信息
1.2 做法
有选择地放弃在特征图或通道上具有高值的激活
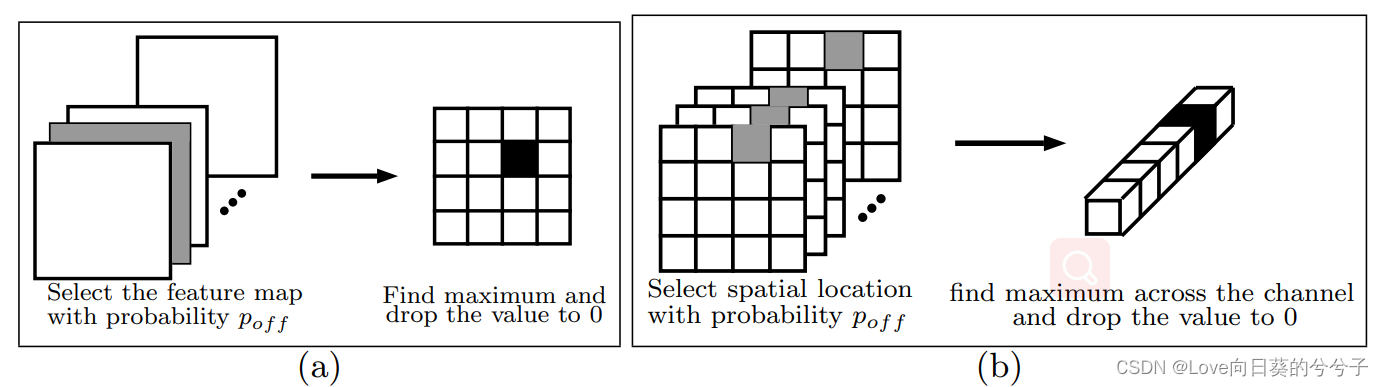
1.3 可视化

方法二:《Improved Regularization of Convolutional Neural Networks with Cutout》
Cutout方法于2017年出现
论文链接:https://arxiv.53yu.com/pdf/1708.04552.pdf
代码链接:https://github.com/uoguelph-mlrg/Cutout
2.1 动机
在一些人体姿态估计,人脸识别,目标跟踪,行人重识别等任务中常常会出现遮挡的情况,为了提高模型的鲁棒性,提出了使用Cutout数据增强方法。该方法的依据是Cutout能够让CNN更好地利用图像的全局信息,而不是依赖于一小部分特定的视觉特征。
2.2 做法
随机屏蔽掉训练过程中输入的正方形区域,称之为cutout,可以用来提高鲁棒性和卷积神经网络的整体性能。这种方法非常容易实现,而且还可以与现有的数据增强形式和其他正则化方法结合使用,以进一步提高模型性能
2.3 代码实现
import torch
import numpy as np
class Cutout(object):
"""Randomly mask out one or more patches from an image.
Args:
n_holes (int): Number of patches to cut out of each image.
length (int): The length (in pixels) of each square patch.
"""
def __init__(self, n_holes, length):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
"""
Args:
img (Tensor): Tensor image of size (C, H, W).
Returns:
Tensor: Image with n_holes of dimension length x length cut out of it.
"""
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for n in range(self.n_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img
# for example
parser.add_argument('--n_holes', type=int, default=1,
help='number of holes to cut out from image')
parser.add_argument('--length', type=int, default=16,
help='length of the holes')
train_transform = transforms.Compose(
[transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[x / 255.0 for x in [125.3, 123.0, 113.9]],
std=[x / 255.0 for x in [63.0, 62.1, 66.7]])
])
if args.cutout:
train_transform.transforms.append(Cutout(n_holes=args.n_holes, length=args.length))
2.4 可视化

方法三:《Random Erasing Data Augmentation》
Random Erasing与Cutout是同一年出现,即都是2017年出现,发表于AAAI2020.
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/7000
代码链接:https://github.com/zhunzhong07/Random-Erasing
3.1 动机
对常用的数据增强技术(如随机裁剪和翻转)的补充,并在图像分类、目标检测和行人重识别方面产生了较强基线的持续改进
3.2 做法
在训练中,Random Erasing随机选择图像中一个任意大小的矩形区域,用随机值擦除其像素点。
- 与cutout相比:
1)相同点:都是在训练过程中随机擦除输入图像中的一个区域像素点
2)不同点:cutout是擦除正方形区域,Random Erasing方法是擦除任意大小的矩形区域
3.3 代码实现
# transforms.py文件内容
from __future__ import absolute_import
from torchvision.transforms import *
from PIL import Image
import random
import math
import numpy as np
import torch
class RandomErasing(object):
'''
Class that performs Random Erasing in Random Erasing Data Augmentation by Zhong et al.
-------------------------------------------------------------------------------------
probability: The probability that the operation will be performed.
sl: min erasing area
sh: max erasing area
r1: min aspect ratio
mean: erasing value
-------------------------------------------------------------------------------------
'''
def __init__(self, probability = 0.5, sl = 0.02, sh = 0.4, r1 = 0.3, mean=[0.4914, 0.4822, 0.4465]):
self.probability = probability
self.mean = mean
self.sl = sl
self.sh = sh
self.r1 = r1
def __call__(self, img):
if random.uniform(0, 1) > self.probability:
return img
for attempt in range(100):
area = img.size()[1] * img.size()[2]
target_area = random.uniform(self.sl, self.sh) * area
aspect_ratio = random.uniform(self.r1, 1/self.r1)
h = int(round(math.sqrt(target_area * aspect_ratio)))
w = int(round(math.sqrt(target_area / aspect_ratio)))
if w < img.size()[2] and h < img.size()[1]:
x1 = random.randint(0, img.size()[1] - h)
y1 = random.randint(0, img.size()[2] - w)
if img.size()[0] == 3:
img[0, x1:x1+h, y1:y1+w] = self.mean[0]
img[1, x1:x1+h, y1:y1+w] = self.mean[1]
img[2, x1:x1+h, y1:y1+w] = self.mean[2]
else:
img[0, x1:x1+h, y1:y1+w] = self.mean[0]
return img
return img
# 例如
import transforms
transform_train =< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









