




 本文介绍了如何利用递归找到用户的最终推荐人。首先,解释了数据库中推荐关系的字段描述,接着深入讨论了递归的概念,包括递归的定义、递推公式和满足的条件。文章通过电影院座位和台阶问题举例,展示了如何编写递归代码。同时,提到了递归可能导致的堆栈溢出和重复计算问题,以及对应的解决策略。最后,针对开篇问题,提出了寻找最终推荐人的解决方案,讨论了可能遇到的堆栈溢出和无限递归问题,并给出了避免这些问题的方法。
本文介绍了如何利用递归找到用户的最终推荐人。首先,解释了数据库中推荐关系的字段描述,接着深入讨论了递归的概念,包括递归的定义、递推公式和满足的条件。文章通过电影院座位和台阶问题举例,展示了如何编写递归代码。同时,提到了递归可能导致的堆栈溢出和重复计算问题,以及对应的解决策略。最后,针对开篇问题,提出了寻找最终推荐人的解决方案,讨论了可能遇到的堆栈溢出和无限递归问题,并给出了避免这些问题的方法。
文章目录
一、场景描述
一般来说,我们会通过数据库来记录这种推荐关系。在数据库表中,我们可以记录两行数据,其中 actor_id 表示用户 id,referrer_id 表示推荐人 id。
A推荐B,B推荐C。A既是B的最终推荐人,也是C的最终推荐人。(这个情景也类似目录的分类,或电商的一级或二级分类。还有省级与市级城市的关系。)
1.1、数据库中的字段数据描述
数据库表中,actor_id 表示用户 id,referrer_id 表示推荐人 id。
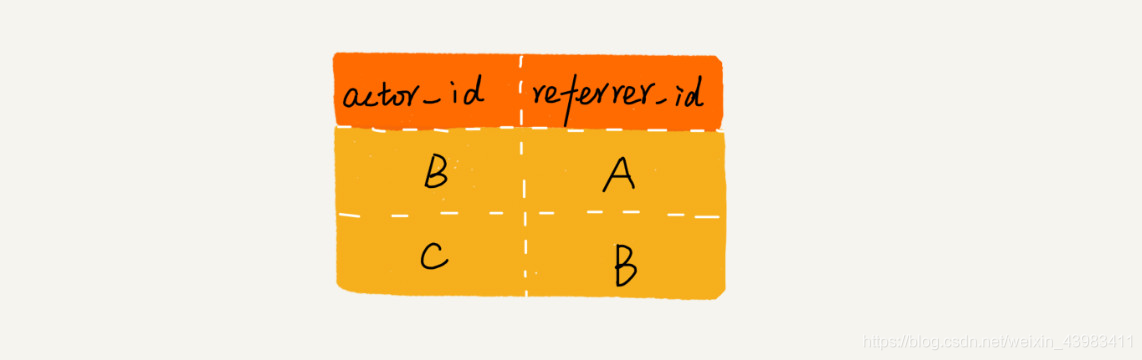
1.2、给定一个用户 ID,如何查找这个用户的“最终推荐人”?
二、如何理解“递归”?
2.1、算法中最难的两个部分
2.1.1、一个是动态规划
2.1.2、一个就是递归
2.2、递归的含义
去的过程叫“递”,回来的过程叫“归”。基本上,所有的递归问题都可以用递推公式来表示。
2.3、递推公式
三、递归需要满足的三个条件
3.1、一个问题的解可以分解为几个子问题的解
何为子问题?子问题就是数据规模更小的问题。比如,前面讲的电影院的例子,你要知道,“自己在哪一排”的问题,可以分解为“前一排的人在哪一排”这样一个子问题。
3.2、这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
3.3、存在递归终止条件
把问题分解为子问题,把子问题再分解为子子问题,一层一层分解下去,不能存在无限循环,这就需要有终止条件。
还是电影院的例子,第一排的人不需要再继续询问任何人,就知道自己在哪一排,也就是 f(1)=1,这就是递归的终止条件。
四、如何编写递归代码?
4.1、写出递归代码最关键的两点
4.1.1、写出递推公式
4.1.1.1、示例一——电影院确定当前座位是第几排
电影座位的案例,它的递推公式:
f(n)=f(n-1)+1 其中,f(1)=1
f(n) 表示你想知道自己在哪一排,f(n-1) 表示前面一排所在的排数,f(1)=1 表示第一排的人知道自己在第一排。有了这个递推公式,我们就可以很轻松地将它改为递归代码,如下:
int f(int n) {
if (n == 1) return 1;
return f(n-1) + 1;
}
4.1.1.2、示例二——假如这里有 n 个台阶,每次你可以跨 1 个台阶或者 2 个台阶,请问走这 n 个台阶有多少种走法?
如果有 7 个台阶,你可以 2,2,2,1 这样子上去,也可以 1,2,1,1,2 这样子上去,总之走法有很多,那如何用编程求得总共有多少种走法呢?
我们仔细想下,实际上,可以根据第一步的走法把所有走法分为两类,第一类是第一步走了 1 个台阶,另一类是第一步走了 2 个台阶。所以 n 个台阶的走法就等于先走 1 阶后,n-1 个台阶的走法 加上先走 2 阶后,n-2 个台阶的走法。用公式表示就是:
f(n) = f(n-1)+f(n-2)
4.1.2、找到终止条件
4.1.2.1、示例一的终止条件:f(1)=1
4.1.2.2、示例二的终止条件:
f(1)=1,f(2)=2。
这个时候,你可以再拿 n=3,n=4 来验证一下,这个终止条件是否足够并且正确。
4.1.3、总结
递归终止条件和递推公式:
f(1) = 1;
f(2) = 2;
f(n) = f(n-1)+f(n-2)
转化成递归代码:
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return f(n-1) + f(n-2);
}
写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
4.1.4、思路总结
如果一个问题 A 可以分解为若干子问题 B、C、D,你可以假设子问题 B、C、D 已经解决,在此基础上思考如何解决问题 A。而且,你只需要思考问题 A 与子问题 B、C、D 两层之间的关系即可,不需要一层一层往下思考子问题与子子问题,子子问题与子子子问题之间的关系。屏蔽掉递归细节,这样子理解起来就简单多了。
因此,编写递归代码的关键是,只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
五、递归代码要警惕堆栈溢出
5.1、为什么会堆栈溢出?
5.2、解决方式
通过在代码中限制递归调用的最大深度的方式来解决这个问题。
5.3、改造代码——电影院(知道自己所在排位数)
电影院那个例子,我们可以改造成下面这样子,就可以避免堆栈溢出了。不过,我写的代码是伪代码,为了代码简洁,有些边界条件没有考虑,比如 x<=0。
// 全局变量,表示递归的深度。
int depth = 0;
int f(int n) {
++depth;
if (depth > 1000) throw exception;
if (n == 1) return 1;
return f(n-1) + 1;
}
5.4、该方法的弊端
但这种做法并**不能完全解决问题,**因为最大允许的递归深度跟当前线程剩余的栈空间大小有关,事先无法计算。如果实时计算,代码过于复杂,就会影响代码的可读性。所以,如果最大深度比较小,比如 10、50,就可以用这种方法,否则这种方法并不是很实用。
六、递归代码要警惕重复计算
6.1、分解第二个例子的递归过程(从这里入手)
第二个递归代码的例子,如果我们把整个递归过程分解一下
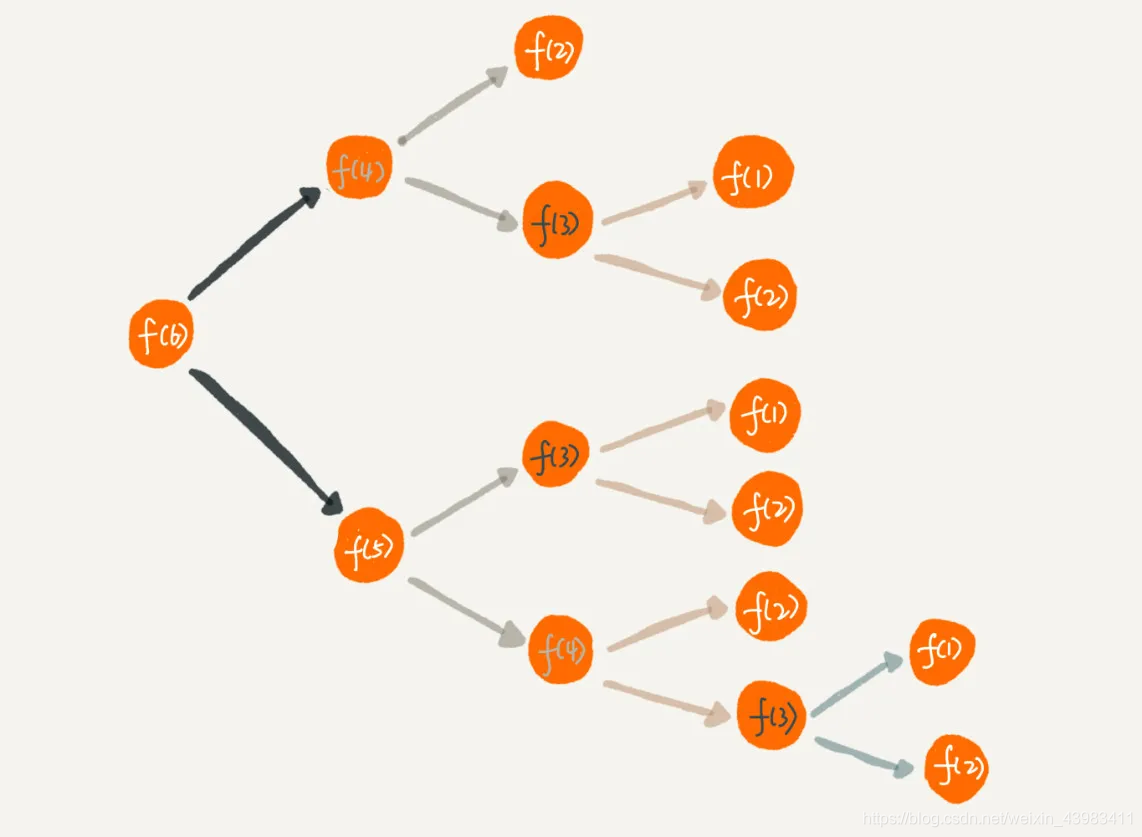
从图中,我们可以直观地看到,想要计算 f(5),需要先计算 f(4) 和 f(3),而计算 f(4) 还需要计算 f(3),因此,f(3) 就被计算了很多次,这就是重复计算问题。
6.2、解决此问题的方法及代码
为了避免重复计算,我们可以通过一个数据结构(比如散列表)来保存已经求解过的 f(k)。当递归调用到 f(k) 时,先看下是否已经求解过了。如果是,则直接从散列表中取值返回,不需要重复计算,这样就能避免刚讲的问题了。
public int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
// hasSolvedList可以理解成一个Map,key是n,value是f(n)
if (hasSolvedList.containsKey(n)) {
return hasSolvedList.get(n);
}
int ret = f(n-1) + f(n-2);
hasSolvedList.put(n, ret);
return ret;
}
七、怎么将递归代码改写为非递归代码?
问题一:局部变量一直给赋值(如以下情况),内存会给分配新的空间吗?还是一直是一个空间。
问题二:尾递归可以解决堆栈溢出的问题。(尾递归就是只调用所在方法,没有其他运算)
7.1、理论总结
笼统的讲,所有的递归代码都可以改写为 迭代循环的非递归写法。 如何做?抽象出递推公式、初始值和边界条件,然后用迭代循环实现。
7.2、示例一的代码改写后
int f(int n) {
int ret = 1;
for (int i = 2; i <= n; ++i) {
ret = ret + 1;
}
return ret;
}
7.3、示例二的代码改写后
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
int ret = 0;
int pre = 2;
int prepre = 1;
for (int i = 3; i <= n; ++i) {
ret = pre + prepre;
prepre = pre;
pre = ret;
}
return ret;
}
递归的原理总结:
递归是从上向下挖到最下面,然后逆向一直往上回去。而上面的迭代,其实就是从最下面开始,然后一直往上。本质是一样的。
八、解答开篇问题
8.1、如何找到“最终推荐人”?我的解决方案是这样的:
long findRootReferrerId(long actorId) {
Long referrerId = select referrer_id from [table] where actor_id = actorId;
if (referrerId == null) return actorId;
return findRootReferrerId(referrerId);
}
8.2、这个代码有两个问题
8.2.1、第一,如果递归很深,可能会有堆栈溢出的问题。
8.2.2、第二,如果数据库里存在脏数据,我们还需要处理由此产生的无限递归问题。比如 demo 环境下数据库中,测试工程师为了方便测试,会人为地插入一些数据,就会出现脏数据。如果 A 的推荐人是 B,B 的推荐人是 C,C 的推荐人是 A,这样就会发生死循环。
8.3、解决办法
两个问题,都可以选择限制递归深度来解决。但是第二个问题有一个更高级的办法,就是自动检测环。这个后面会有详解。
九、课后思考题
我们平时调试代码喜欢使用 IDE 的单步跟踪功能,像规模比较大、递归层次很深的递归代码,几乎无法使用这种调试方式。对于递归代码,你有什么好的调试方法呢?
9.1、解决办法(不太明白)
IDEA调试技巧之条件断点
调试递归:
1.打印日志发现,递归值。
2.结合条件断点进行调试。

















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









