







 本文介绍了使用Python爬虫抓取时光网top100电影的名称、导演和评分的过程。针对不同页面的网址规律进行处理,并利用XPath解析网页获取数据。在遇到评分缺失的情况时,通过try...except处理。文章结尾作者表示自己是初学者,欢迎读者指出错误。
本文介绍了使用Python爬虫抓取时光网top100电影的名称、导演和评分的过程。针对不同页面的网址规律进行处理,并利用XPath解析网页获取数据。在遇到评分缺失的情况时,通过try...except处理。文章结尾作者表示自己是初学者,欢迎读者指出错误。
一、思路
1.第一页的网址:http://www.mtime.com/top/movie/top100/,
第二页网址:http://www.mtime.com/top/movie/top100/index-2.html
两者比较没有规律,但从后面页的网址开始就有规律,所以考虑分成两段提取
2.在匹配评分的时候发现re匹配不出来(应该是个人能力问题),最终通过Xpath匹配
3.但在52名的电影没有评分,故在抓取评分的时候放了try,不然会报一个超出索引范围的错:
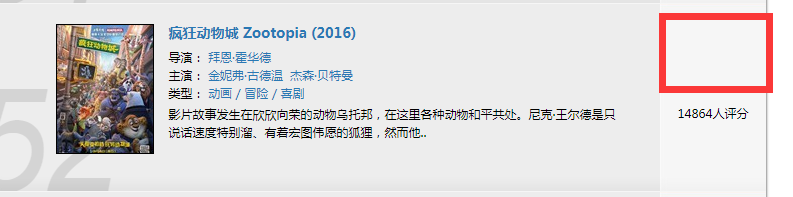
4.对输出稍微格式化了一个,但还是有不如意的地方
二、代码
import urllib.request,re
from lxml import etree
for j in range(10):
print('正在爬取第 %d 页' %int(j+1),'......')
if j == 0:
url = "http://www.mtime.com/top/movie/top100/"
date = urllib.request.urlopen( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2991
2991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









