






 本文介绍了Linux内核中的页和区的概念,详细阐述了伙伴系统算法如何解决外碎片问题,以及slab机制如何优化内存分配,特别是针对小内存区域的请求。此外,还讨论了页框回收算法LRU及其在活跃和非活跃链表中的应用。最后,提到了内核空间的内存管理,包括固定映射和非连续内存分配策略。
本文介绍了Linux内核中的页和区的概念,详细阐述了伙伴系统算法如何解决外碎片问题,以及slab机制如何优化内存分配,特别是针对小内存区域的请求。此外,还讨论了页框回收算法LRU及其在活跃和非活跃链表中的应用。最后,提到了内核空间的内存管理,包括固定映射和非连续内存分配策略。
页
内核用page结构体表示系统的每个物理页(页框),描述当前时刻在相关物理页存放的东西
- flag:表示状态,包括是不是脏的、是否锁定在内存中
- _count:页的引用计数
区(指物理内存,只和内核空间有关)
Linux根据页的特性进行分组,划分为区,每个区使用自己的伙伴系统算法
- ZONE_DMA:<16MB的内存页框。执行DMA操作,因为DMA只能使用特定的内存地址
- ZONE_NORMAL:≥16MB并<896MB的内存页框。能正常映射的页
- ZONE_HIGHEM:≥896MB的内存页框。高端内存,不能永久映射到内核地址空间,因为物理内存比虚拟内存大。如果虚拟内存比物理内存大那么ZONE_HIGHEM区为空
- 为什么是896MB:因为内核空间(线性地址)只有1GB,0-896MB线性地址和物理地址映射,剩下的128MB线性地址要和ZONE_HIGHEM映射
伙伴系统算法
一种内存分配策略
- 伙伴:两个块有相同大小,物理地址是连续的
- 解决外碎片问题
- 实现:
- 把所有空闲页框分组为11个块链表,每个链表包含 2^0 到 2^10 个连续页框
- 请求时:
- 合适的,取走
- 小于需要的,寻找下一个更大的页块
- 大于需要的,把多出来的拼接到合适的链表;如果拼接时发现是连续的页框(是伙伴),则合并拼接到更大的链表,迭代这个过程
- 释放时:
- 放回合适的链表
- 如果放回时是连续的页框(是伙伴),迭代更新链表
slab机制
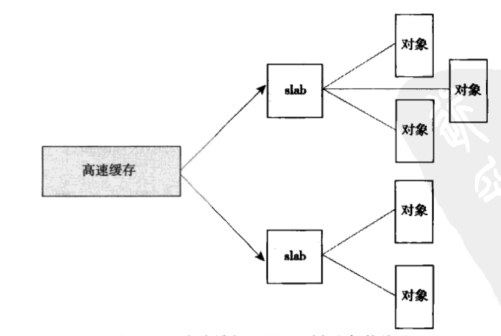
一种内存分配策略
- 解决内碎片问题,小内存区的请求问题
slab实现
- slab层把不同对象划分为高速缓存组,每个组存放不同类型的对象,比如task_struct_inod
- slab由一个或多个物理上连续的页组成,每个组由一个或多个slab组成
- 三种状态:slab满,就创建新slab;slab部分满,分配时先使用;slab空
- slab避免频繁分配和释放页
- 分配页:已发出一个分配新对象的请求;高速缓存不包含任何空闲对象,slab满
- 释放页:slab高速缓存中有太多空闲对象;定时器确定有完全未被使用的slab
页框回收算法:最近最少使用LRU(双链策略)
把属于进程用户态地址空间或页高速缓存的所有页分成两组:活动链表和非活动链表
- 活跃链表上的页面被认为是“热”的且不会被换出,而非活跃链表上的页是可以被换出的
- 页面从尾部加入,头部移除
- 两个链表需要维持平衡,如果活跃链表过多,就将活跃链表的头页面移到非活跃链表
内核空间
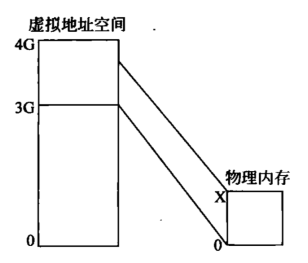
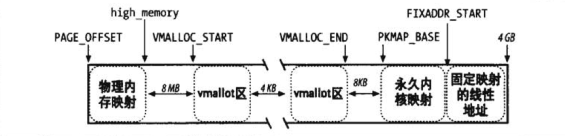
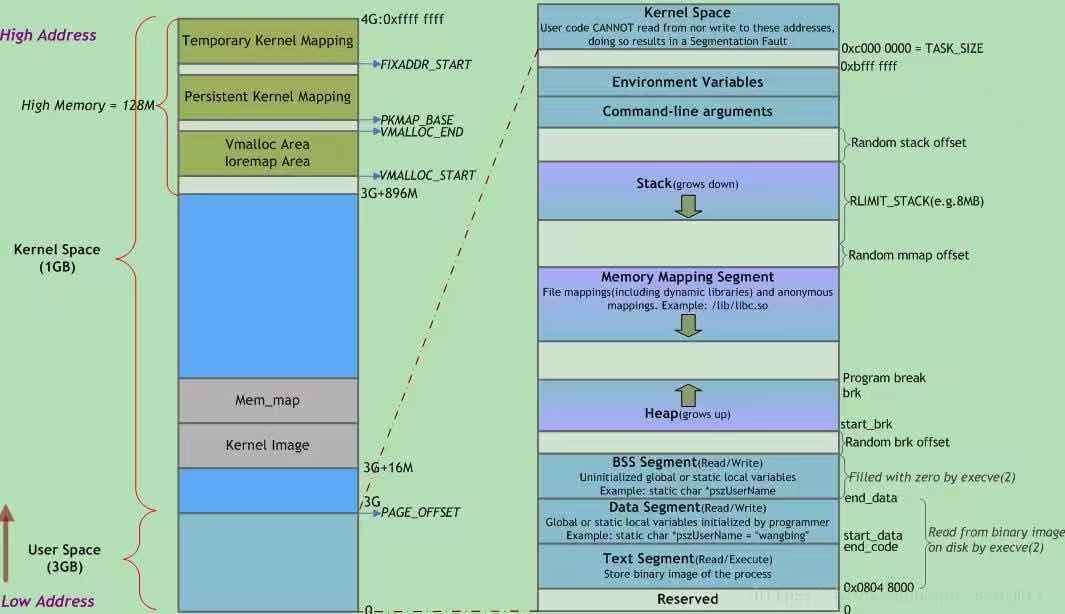
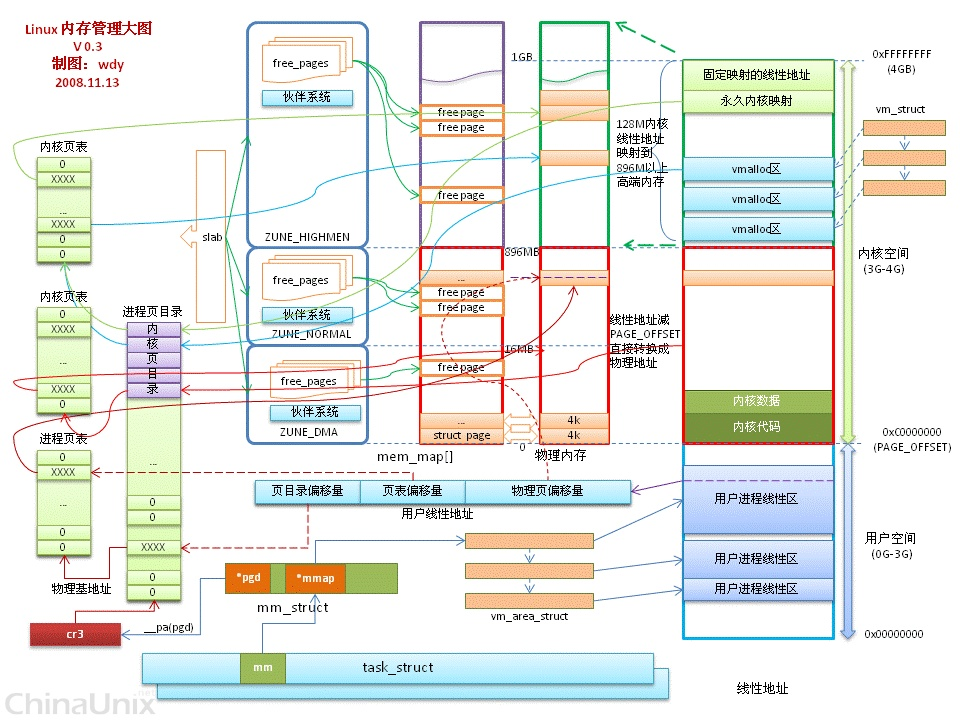
- 至少128MB的线性地址总是留作它用,因为内核使用这些线性地址实现非连续内存分配和固定映射的线性地址
- 固定映射:线性地址映射一个物理内存的页框,代替指针变量,使用时不需要检查和只需一次访存。都放在线性地址第4个GB的末端
- 非连续内存分配:动态分配和释放内存页的一种特殊方法
- 用户空间最多访问3GB物理内存范围,没有高端内存的概念;内核可以访问所有物理内存,因此有高端内存的概念
- 内核空间3GB到3GB+896MB的部分都是直接映射到0到896MB的ZONE_NORMAL和ZONE_DMA,内核页表做线性地址-3GB=物理地址的映射
- kmalloc:保证线性地址和物理地址都是连续的
- 内核映像放在这段内核空间
- 内核空间128MB的三种映射ZONE_HIGHEM区机制
- 永久内核映射:允许内核建立高端页框到内核地址空间的长期映射,使用内核页表中一个专门的页表
- 建立永久内核映射可能会阻塞当前进程,因为可能没有空闲页表项,所以不能用于中断上下半部
- 临时内核映射:每个CPU保留部分固定映射的地址,使用专门的页表进行映射
- 因为一定会有保留的地址,所以不会阻塞,可用于中断上下半部
- 非连续内存区管理:使用专门的页表项
- vmalloc:线性地址连续,物理地址不一定连续
- 为了获得大块内存时使用
- vmalloc更像是为0-896MB的地址保留更完整的有连续的地址的内存给DMA和Normal的kmalloc使用,因为内存用多了还是会出现碎片,所以把不太重要的映像放在高端内存去折腾,比如声音驱程
- 永久内核映射:允许内核建立高端页框到内核地址空间的长期映射,使用内核页表中一个专门的页表


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









