







1.Spark 内存介绍
在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 Spark 作业(Job),并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给 Driver,同时为需要持久化的 RDD 提供存储功能。
Spark应用程序启动时的–executor-memory或spark.executor.memory参数配置。Executor内运行的并发任务共享JVM堆内内存,这些任务在缓存RDD和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行Shuffle时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些Spark内部的对象实例,或者用户定义的Spark应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同
2 . 内存空间分配
2.1 静态内存管理
在静态内存管理机制下,存储内存、执行内存和其他内存三部分的大小在Spark应用程序运行期间是固定的,但用户可以在应用程序启动前进行配置,堆内内存的分配如图所示:
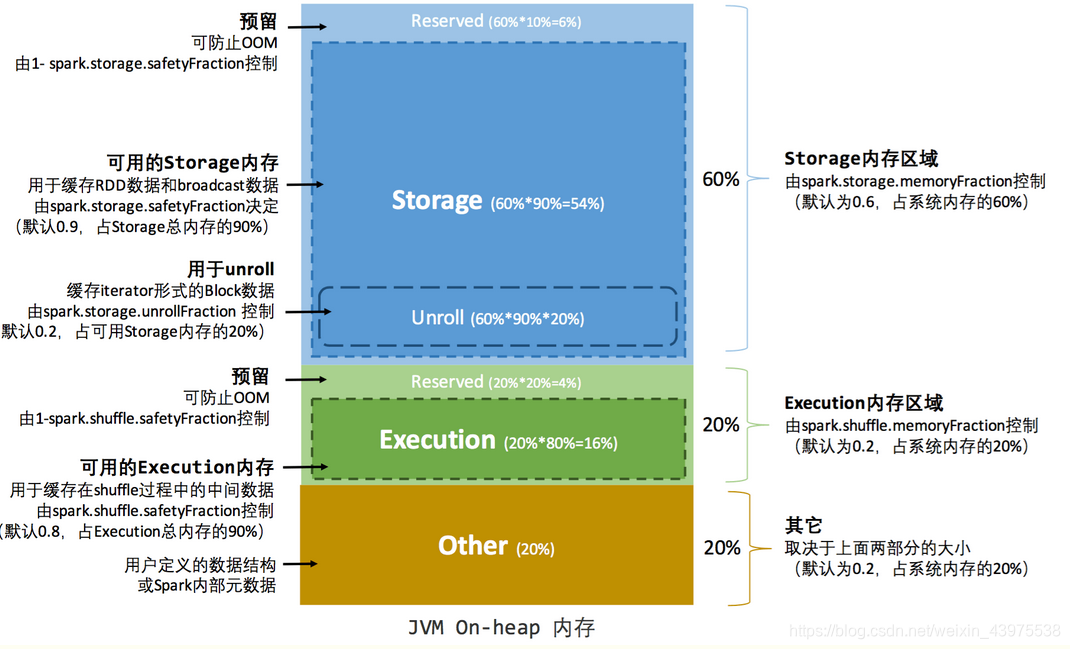 计算公式:
计算公式:
名称 计算方式 相关参数
Storage systemMaxMemory * 0.6 * 0.9 spark.storage.memoryFraction/spark.storage.safetyFraction
Execution systemMaxMemory * 0.2 * 0.8 spark.shuffle.memoryFraction/spark.shuffle.safetyFraction
缺点
cache数据的应用在运行的时候只会占用一小部分可用内存,而默认的内存配置中storage就用去了60%,造成了浪费。
2.2 统一内存管理
Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域。
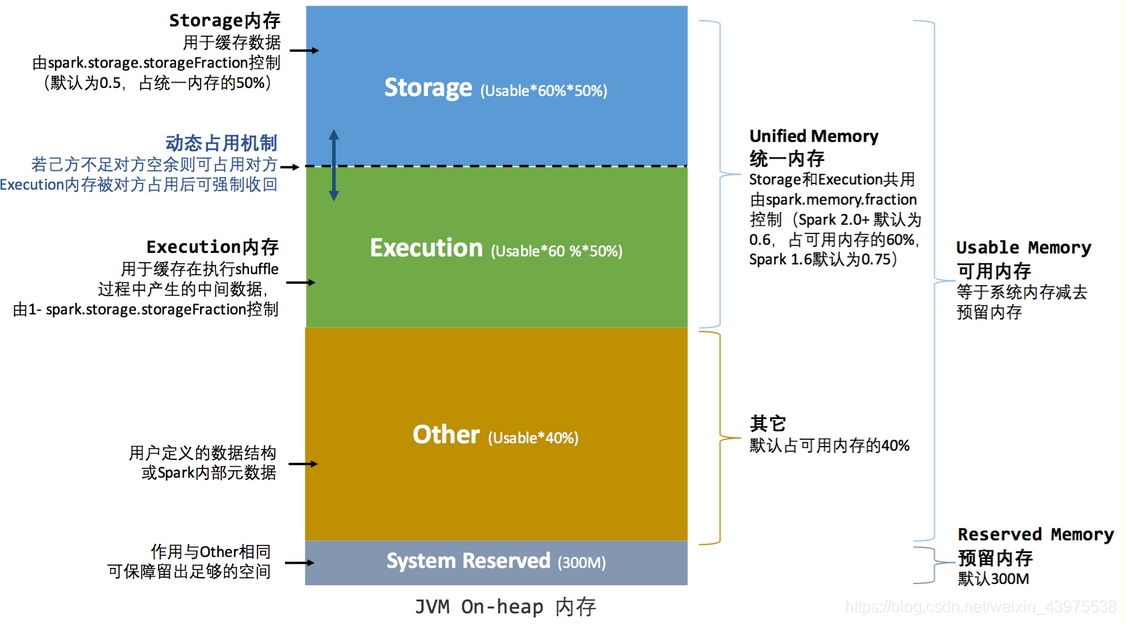 计算公式:
计算公式:
名称 计算方式 相关参数
Storage (Total-300M) * 60% * 50% spark.storage.storageFraction/spark.memory.fraction
Execution (Total-300M) * 60% * 50% spark.storage.storageFraction/spark.memory.fraction
Other (Total-300M) * 40% spark.memory.fraction
System Reserved 300M 无
动态占用机制
设定基本的Storage内存和Execution内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围
双方的空间都不足时,则存储到硬盘,若己方空间不足而对方空余时,可借用对方的空间(存储空间不足是指不足以放下一个完整的 Block)
Execution的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间
Storage的空间被对方占用后,无法让对方”归还”,因为需要考虑 Shuffle过程中的很多因素,实现起来较为复杂。
3. 存储内存管理
3.1 RDD 的持久化机制
1、为什么要持久化
action操作触发,会触发RDD的重算,对于相同数据执行多次action操作,要多次从FS中读取数
据,这就降低了性能。因而我们可以通过cache和persist方法将RDD缓存到内存或者磁盘中。
重算:重新将FS上的数据读入RDD再根据依赖关系推导出所需要的RDD。
2、cache() && persist()
cache:
底层调用了persist方法
默认StorageLevel为MEMORY_ONLY且不可更改
persist:
默认StorageLevel为MEMORY_ONLY,可以自由设置StorageLevel
注意:
懒执行,持久化的最小单位为分区
spark会自动监控各节点的缓存情况,请采用LRU移除一些数据
应用程序所有job结束,持久化数据丢失
也可以通过unpersist()方法手动移除缓存,它是立即执行的
持久化可以赋值给一个变量,下个job中使用这个变量就是使用的持久化的数据。
3、checkpoint()
执行流程:
1、设置文件保存目录,sc.SetCheckpointDir(“外部目录”)
2、执行job时对要执行checkpoint的rdd做标记
3、job执行完回溯查看哪些rdd有chekc标记,
4、重新执行一次job用来计算checkpoint的RDD的数据。
特点:
懒执行,基于DISK_ONLY
可以将数据存在外部文件系统的磁盘中
应用程序所有job执行完数据不丢失(和cache和persist的区别),用来保存rdd状态,在
sparkstreaming应用很多
优化:
在需要checkpoint()的rdd上执行cache,重新job时速度会加快
3.2 存储级别
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they’re needed. This is the default level. |
| MEMORY_AND_DISK | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don’t fit on disk, and read them from there when they’re needed. |
| MEMORY_ONLY_SER(Java and Scala) | Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. |
| MEMORY_AND_DISK_SER(Java and Scala) | Similar to MEMORY_ONLY_SER, but spill partitions that don’t fit in memory to disk instead of recomputing them on the fly each time they’re needed. |
| DISK_ONLY | Store the RDD partitions only on disk.MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. Same as the levels above, but replicate each partition on two cluster nodes. |
| OFF_HEAP (experimental) | Similar to MEMORY_ONLY_SER, but store the data in off-heap memory. This requires off-heap memory to be enabled. |

















 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









