







python基础
一、计算机组成相关
内存的作用:临时存储CPU要处理的数据,内存的速度远远高于硬盘的速度。
例如内存被占满了,那cpu处理速度肯定相应变慢。此时将内存释放,cpu的处理速度就会变快了。
python编写规范:
文件编码全部为utf-8,需要再文件开头加上:# – coding: utf-8 –
二、python基础知识
python是一门解释型高级语言。
优点:跨平台,开源语言。开发效率高,执行效率低;模块扩展库种类繁多。
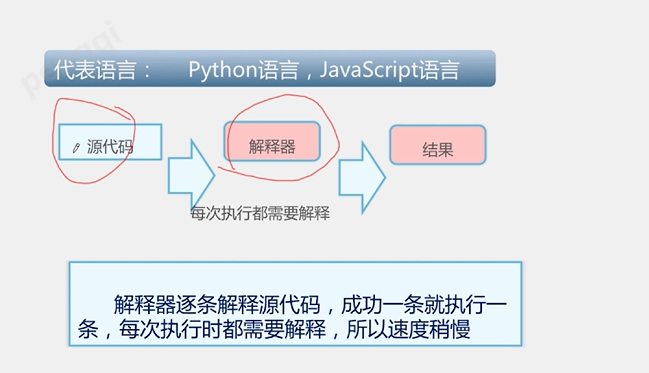
Python解释器作用:运行文件,大部分使用的是CPython解释器
PyCharm :python IDE(集成开发环境),内部集成多种功能,可以提高工作效率,如:语法高亮,代码跳转,解释器,框架和库。
python编程思想:理解功能逻辑
任何的程序设计都包含IPO,即:
- I :Input 输入,程序的输入
- P :Process 处理,程序的主要逻辑过程
- O: Output输出,程序的输出
基本的程序设计模式:
1.确定IPO:明确需要实现功能的输入输出,以及主要的实现逻辑
2.编写程序:将计算求解的逻辑过程通过变成语言设计展示
3.调试程序:对编写的程序按照逻辑过程进行调试,确保程序按照正确逻辑执行获得想要的效果。
参考:https://edu.youkuaiyun.com/skill/python/python-3-1?category=1
一切数据皆对象!
注意事项:
1.严格区分大小写
2.首行靠左,不能有空格
3.可以空行,不能空格
引用
在python中,值是靠引用来传递的
id()用来检测变量的id值(即值在内存中的十进制值)。同时也可以判断两个变量是否为同一个值的引用。
a,b=1,3
#数据互换
a,b=b,a
print(id(a))
print(id(b))
2318699790640
2318699790576
注释
三种注释方式:
1.使用#进行单行注释
2.使用单引号‘’,或者双引号“ ” 进行注释。不能用于多行注释。
3.多行注释使用三引号‘’‘ ’‘’
变量
变量:
变量是一个存储数据的时候当前数据所在的内存地址名字
变量定义:变量名=值
可以同时定义多个变量:a=b=c=1
标识符规则:
1.由数字,字母,下划线组成
2.不能数字开头
3.不能使用内置关键字
4.严格区分大小写
5.见名知意
数据类型
数值:int(整型),float(浮点型)
布尔型:true(真),false(假)
str:字符串
list列表
tuple元组
set集合
dict字典
格式化输出:
%s:字符串
%d:有符号的十进制整数
%f :浮点数
age=23
name="pengq"
weight=55.5
id=124
print("我的年龄是%d岁" % age)
print("我的名字是%s" % name)
# %.2f 保留2为小数位
print("my weight is %.2f kg" % weight)
# id为6为,不足的以0补齐
print("my id is %06d" % id)
print("my name %s ,年龄是%d岁" % (name,age))
# f'{表达式}' 格式化字符串的语法
print(f'my name{name} ,my age {age}岁')
转义字符
\n :换行
\t : 制表符,一个tab键的距离,就是4个空格。
#两个print会输出成一行,print默认带有end=“\n”
print(“我的名字是%s,” % name,end=“”)
print(“my weight is %.2f kg” % weight)
#\n 换行显示,会显示为两行
print(“my name %s \n,年龄是%d岁” % (name,age+1))
'''
input输入
特点:
1.遇到input,等待用户输入
2.接受input存变量
3.input接收到的数据类型都当作字符串处理
'''
username=input('请输入name:')
print(username)
'''
数据类型转换
将接收到的数据转换成int型:int()
其他:str();list();tuple();eval()[表示计算在字符串中的有效python表达式,并返回一个对象。即输入是什么类型就会返回什么类型]
'''
num=int(input('请输入一个数字:'))
print(num)
print(type(num))
运算符
混合运算符优先级顺序:()高于**高于*/ // % 高于±
c=10
c*=1+2
先算赋值运算符右边的表达式,再算复合赋值运算。
即先算1+2,再算c*=1+2---->c=c*(1+2)
多重判断:
if a>1:
print("执行语句1")
elif (a>0)and (a<1):
print("执行语句2")
...
else :
print("xxx")
# 出拳游戏:
import random
player=int(input("请出拳:0-石头,1-剪刀,2-布:"))
computer=random.randint(0,2)
if player==computer:
print("平手")
elif (player==0 and computer==2) or (player==1 and computer==0) or (player==2 and computer==1):
print("你输啦")
else :
print("你赢啦")
print(f'玩家{player},电脑{computer}')
三目运算符:
c=a if a>b else b
如果条件成立则c=a,否则c=b
九九乘法表:
i=1
while i<=9:
j=1
while j<=i:
print(f'{j}*{i}={j*i}',end="\t")
j+=1
print()
i+=1
方法二:
i=1
while i<=9:
j=1
while j<=i:
print(f'{j}*{i}={j*i}',end=" ")
if j==i:
print("\t")
j+=1
for循环:
for 临时变量 in 序列:
重复执行的代码
while 跟else结合使用:
a =1
while a<5:
print(a)
a+=1
else :
print("....")
只有程序正常结束,才会打印else的语句
总结:
- break 停止运行,跳出本层循环
- continue退出本次循环,继续执行下一次循环
- else:
1)while和for都可以配合使用
2)else下方缩进的代码含义:当循环正常结束后执行的代码
3)break终止循环不会执行else下方缩进的代码
4)continue退出循环的方式执行else下方缩进的代码
运算符操作
+号(合并)和 * (复制)适用于字符串,列表,元组
例:
str1='dec'
str2='xwcec'
print(str1+str2) #decxwcec
list1=[1,2,3]
print(list1*3) #[1, 2, 3, 1, 2, 3, 1, 2, 3]
t1=(1,2,3)
print(t1*2) #(1, 2, 3, 1, 2, 3)
字符串
字符串切片:对操作对象截取其中一部分的操作。
序列[start:end : step]
其中step表示的是start 和end的选取间隔,默认是为1
str1='12345678'
print(str1[2:5]) #345 左含右不含
print(str1[2:5:2]) #35开始位置+结束位置的数值
print(str1[2:5:4]) #3
print(str1[2:5:5]) #3 2-5的数应该是345,但是这两个数的最大步长才2,所以大于2的步长都不存在,只显示开始的数值。
print(str1[:2]) #从0开始,选取2个数
print(str1[2:]) #从下标第二位开始,,一直到结尾数据
print(str1[::]) #显示所有的数据
print(str1[::-1]) #,步长为负数时,字符串倒序显示
print(str1[::-2]) #8642
print(str1[-4:-1]) #567,下标-1表示最后一个数字,依次向前倒推。
1.字符串常用方法
字符串查找:
find()函数
#检查某个字串是否包含在这个字符串中,如果有则返回这个字符串开始的位置下标,否则则返回-1
#find(字串,[开始位置,结束位置])
strf='qwewq'
print(strf.find("wew")) # 1
print(strf.find("q",2)) # 4
print(strf.find("sjdjs")) # -1
#index(),若字串不存在,则会报错
print(strf.index("we")) # 1
#count()
print(strf.count("we")) # 4,一共字符串中有出现几次该字符串
print(strf.count("cdscdsvsdvds")) #0,表示不存在该子串
2.字符串修改
#字符串序列.replace(旧子串,新子串,替换次数)
#字符串是不可变数据类型
strf='qwewqwewewevfvfvfvfbb'
print(strf.replace("we","sss",20))
print(strf.split("we"))
new_str="~~".join("abd")
print(new_str) # a~~b~~d
str2=' ss fw ww '
print(str2.strip()) #strip()删除左右两侧的空白
#ljust():返回元字符串左对齐,并使用指定的字符填充至对应长度的新字符串,默认以空格填充
leg_ = 'i want to eat check leg!'
str3= leg_
print(len(str3))
print(str3.ljust(30,'q') # i want to eat check leg!qqqqqq
#startswith()判断字符串是否以某个子串开头 ; endswith() 判断是否以xxx为结尾
#字符串.startswith(子串,开始位置下标,结束位置下标)
str4='as2cew3'
print(str4.startswith('as')) #true
print(str4.endswith('qwq')) #false
#isalpha() 若字符串是否都是字母组成
# isdigit() 判断字符串是否都是数字
# isspace() 判断字符串是否都是空格
# isalnum() 判断字符串是否数字或字母的组合
str5='wdsc213'
print(str5.isalpha()) #false
print(str5.isspace()) #false
print(str5.isalnum()) #true
索引
索引[]
#1.正数从0开始
#2.负数从末尾开始数,-1开始
name=“tony”
print(name[0])
正负索引
正索引:从0开始,0是第一个数;1是第二个数,以此类推
负索引:从-1开始,这是代表最后一个数;-2代表倒数第二个数。
例子:
myList=[1,2,3,4,5]
#正索引取值
print(myList) #[1, 2, 3, 4, 5]
print(myList[0]) #1
#负索引取值
print(myList[:-1]) #[1, 2, 3, 4]
print(myList[::-1]) #[5, 4, 3, 2, 1]
元素类型
可变和不可变类型
数据能够直接进行修改,是可变,否则是不可变
可变类型:列表,字典,集合
不可变类型:整型,浮点型,字符串,元组
1.列表
可以一次性存多个数据,并且可以为不同数据类型
#①空列表 list1=[]
#②只有一个元素的列表
list1=[12]
#列表的追加
list1.append(5)
print(list1)
增加操作:append() 、extend() 、insert()
#append() 追加数据到列表的结尾,若该增加的数据是整个列表,则是将整个列表增加到数据中
name_list=['wec','wedc']
name_list.append('xiaohong')
print(name_list) #['wec', 'wedc', 'xiaohong']
#extend是将数据拆开后逐一追加到列表
name_list1=['sxsa','as']
name_list1.extend('pengq')
print(name_list1) #['sxsa', 'as', 'p', 'e', 'n', 'g', 'q']
插入一个新的数据:
guest_list.insert(0,'GURR')
获取某个数的位置:index()
获取出现的次数:count()
mylist=[1,2,3,4,1,2,3]
# 获取列表中的值在列表中一共出现了几次
x=mylist.count(1)
print(x)
# 获取值在列表中的位置,从左到右的顺序,删除一个则显示后一个的位置
print(mylist.index(3)) #2
mylist.remove(3)
print((mylist.index(3))) #删除前一个数值3后重新排列【1,2,4,1,2,3】,从这个新的列表中获取3的位置
删除数据
del(name_list)
可以删除指定下标的数据
del( company_list[0] ) 或者del name_list[0]— del函数后面要跟序号;
company_list.pop() — 删除列表最后一个元素,也可以删除指定位置的元素,如company_list.pop(1)删除下标未1的元素;
company_list.remove(‘Tencent’) — 删除列表指定值元素;
修改数据:
guest_list[0]=‘qq’
查找
1.以下标方式查找
name_list=['qw','eww','ewwf','scc']
print(name_list[0]) #qw
#函数 index(),count(),len()
print(len(name_list)) #4
#in /not in
print('qw' in name_list) #true
列表排序:
num_list=[1,2,7,4,8,3,6]
num_list.reverse()
print(num_list) #[6, 3, 8, 4, 7, 2, 1]
num_list.sort()
print(num_list) #[1, 2, 3, 4, 6, 7, 8]
#复制数据
print(num_list.copy())
sorted(my_list) --- 正序排列;
sorted(my_list,reverse = True) --- 倒叙排列;
my_list.sort() --- 正序排列;
my_list.sort(reverse = True) --- 倒叙排列;
my_list.reverse() --- 反转排列;
reversed(my_list) --- 反转排列;
例:
my_list=['P','y','t','h','o','n']
print("Here is the original list:")
print(my_list)
print()
print('The result of a temporary reverse order:')
print(sorted(my_list,reverse=True))
print()
print('Here is the original list again:')
print(my_list)
print()
my_list.sort(reverse=True)
print('The list was changed to:')
print(my_list)
print()
my_list.reverse()
print('The list was changed to:')
print(my_list)
result:
Here is the original list:
['P', 'y', 't', 'h', 'o', 'n']
The result of a temporary reverse order:
['y', 't', 'o', 'n', 'h', 'P']
Here is the original list again:
['P', 'y', 't', 'h', 'o', 'n']
The list was changed to:
['y', 't', 'o', 'n', 'h', 'P']
The list was changed to:
['P', 'h', 'n', 'o', 't', 'y']
练习:
#将5个老师随机分配到3个班级
#1.首先准备数据;2.然后将老师分配到班级;3.验证是否分配成功
teachers=['xiaohong','xiaozhang','xiaoqi','zhangqu','guohe']
classment=[[],[],[]]
for teacher in teachers:
num=random.randint(0,2)
classment[num].append(teacher)
i=1
for c_count in classment:
if len(c_count)==0:
print("该班级暂时还没有老师~" ,end ='')
else :
print(f'班级{i}有{len(c_count)}个老师.老师名字分别是',end=" ")
for c in c_count:
print(c,end =',')
print()
i+=1
结果打印:
该班级暂时还没有老师~
班级2有5个老师.老师名字分别是 xiaohong,xiaozhang,xiaoqi,zhangqu,guohe,
该班级暂时还没有老师~
2.元组
一个元组可以存储多个数据,元组内的数据是不能修改的。
# 如果单个数据的元组,需要加个小逗号
t1=(2,)
print(type(t1))
t2=(1) # 是int类型
print(type(t2))
#元组数据只能查找数据,不支持修改。删除只能和删除整个元组
t3=('qw',12,'eds')
print(t3[2]) #结果:eds
print(t3.index('qw')) # index为0
#若元组中的数据有列表,此时是可以修改的
t4=([1,2,3],'w')
t4[0][1]='qwe'
print(t4 #([1, 'qwe', 3], 'w')
3.字典
特点:
1,符号为大括号
2,数据以键值对形式存储
3,各个键值对之间用逗号隔开
4,keyname 不能重复
字典的方法:d.setdefault(i,0) 若存在默认值则不变,若没有默认值则默认为0
dict1={'name':'peng','age':25}
print(dict1['name']) # peng
#创建空字典的两种方法
dict2={}
print(dict2)
dict3=dict()
print(type(dict3))
print(dict3)
#修改数据
dict1={'name':'peng','age':23}
dict1['name']='qi'
dict1['age']=25
print(dict1) #{'name': 'qi', 'age': 25}
dict1['id']=100
print(dict1) #{'name': 'qi', 'age': 25, 'id': 100}
#删除数据del() \ del
#del(dict1)
del dict1['age']
print(dict1) # {'name': 'qi', 'id': 100}
dict1.clear()
print(dict1) #空字典: {}
字典的查找操作:
#如果key存在,则修改这个值,否则新增键值对
#查找函数
#get() : 字典序列.get(key,默认值)
dict1={'name':'百变小樱','age':3}
print(dict1.get('name')) #若存在则返回值,若不存在,则返回none
print(dict1.get('names','haha')) #key不存在,返回设置的默认值haha
#keys() 查看当前字典的所有key
print(dict1.keys()) #dict_keys(['name', 'age'])
#values() 查看当前字典的所有value值
print(dict1.values()) #dict_values(['百变小樱', 3])
# items() 查找字典中所有的键值对,返回可迭代对象。
print(dict1.items()) #dict_items([('name', '百变小樱'), ('age', 3)])
字典的数据获取操作:
dict1={'name':'xixi','age':23}
#1.遍历字典的key
for key in dict1.keys():
print(key)
#2.遍历字典的value
for value in dict1.values():
print(value)
#3.遍历字典中的所有数据,以键值对显示
for a in dict1.items():
print(a)
#4.遍历键值对拆包
for key,value in dict1.items():
print(f'{key}={value}') #name=xixi age=23
4.集合
创建集合用{},或者set(),但是如果要创建空集合只能用set(),因为{}用来创建空字典
#集合数据不能重复,会自动去重
#集合没有顺序,所以也没有下标
s2={1,3,2,4,2,50,60,40,50}
print(s2) #{1, 2, 3, 4, 50, 40, 60}
s3=set()
print(s3) #set()
print(type(s3))
s4=set('abdncnjrk232')
print(s4) #{'a', 'n', 'b', 'k', 'j', '2', 'r', '3', 'c', 'd'}
#集合中增加数据的方法
#1.add() 若集合中已有数据,则不做任何改变.因为集合有去重功能
s2.add(50)
print(s2)
#update() 增加的数据是序列,不能是int等常规类型
s3.update([12,10,30])
print(s3) #{10, 12, 30}
删除数据:
#remove() 若数据不存在会报错
s1={10,20,3,40,50,30}
s1.remove(10)
print(s1)
#discard() 如果数据不存在不报错
s1.discard(20)
print(s1)
#pop() 随机删除集合中的某个数据,并返回这个数据
delnum=s1.pop()
print(s1)
集合中数据的查找操作
in:判断数据在集合序列
not in : 判断数据不在集合序列
s1={10,20,3,40,50,30}
print(10 in s1) #true
print(10 not in s1) #false
Python3 的六个标准数据类型中:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
公共方法
len(): 计算容器中元素的个数
del() \ del: 删除数据
max() :返回容器中元素最大值
min() :返回容器中元素最小值
range(start , end ,step ):生生成从start到end的数字,步长为step,供for循环使用
enumerate() : 用于将一个遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在for循环中。
#enumerate(可遍历对象,start=0)
s1={12,12,23,43,5,4}
for i in enumerate(s1):
print(i)
#结果:
(0, 4)
(1, 5)
(2, 23)
(3, 43)
(4, 12)
切片 [start : end] 左含右不含
print(name[0:3])
print(name[-3:-1])
print(name[1:])
容器类型转换
注意:
1.集合可以完成列表去重
2.集合不支持下标
list2=[12,43,56,7]
s1={'qw','wed','rfd'}
t1=('qq','qww','cdc')
#tuple() 转换成元组
print(tuple(list2))
#list() 转换成列表
print(list(s1))
#set()转换成集合
print(set(t1))
拆包和交换变量值
拆包:元组
def chaibao():
return 100,200
num1,num2=chaibao()
print(num1)
print(num2)
结果:
100
200
拆包:字典
dict1={'name':'Ashley','age':23}
a,b=dict1.items()
print(a)
print(b)
结果:
('name', 'Ashley')
('age', 23)
数据交换
a,b=1,2
print(a)
print(b)
#数据互换 ---------简易代码
a,b=b,a
print(a)
print(b)
三、推导式
1.列表推导式
作用:用一个表达式创建一个有规律的列表或控制一个有规律列表
#for循环举例:
list1=[]
for i in range(10):
list1.append(i)
print(list1)
#列表推导式实现
list2=[i for i in range(10)]
print(list2)
# 取0-10的偶数列表
list1=[i for i in range(0,10,2)]
print(list1)
#用if实现
list2=[i for i in range(10) if i%2==0]
print(list2)
for嵌套列表推导式:
#需求显示如下:[(1,0),(1,1),(1,2),(2,0),(2,1),(2,3)]
list1=[]
#循环嵌套即可,看成两个嵌套循环
for i in range(1,3):
for j in range(3):
list1.append((i,j))
print(list1)
#列表推导式
list2=[(i,j) for i in range(1,3) for j in range(3)]
print(list2)
result:[(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
字典推导式练习:
#创建一个字典:字典key是1-5,value是这个数的平方
dict1={}
dict1={i:i**2 for i in range(1,5)}
print(dict1) #{1: 1, 2: 4, 3: 9, 4: 16}
#将两个列表合并为一个字典
list1=[1,2,3]
list2=['qw','ed','tghrgt']
dict2={list1[i]:list2[i] for i in range(len(list2)) }
print(dict2) #{1: 'qw', 2: 'ed', 3: 'tghrgt'}
提取字典中目标数据
count1={'name':'hh','age':23}
count2={key:value for key,value in count1.items() if value==23}
print(count2) #{'age': 23}
四、函数、类、包
函数就是将一段具有独立功能的代码块整合到一个整体并命名,在需要的位置调用这个名称即可完成对应的需求。有初始化的类,调用的时候一定要每个对象都要跟初始化函数一样。
作用:封装代码,高效的实现代码重用
函数定义:
def 函数名(参数):
代码
…
'''
1.函数需要先定义再调用
2.如果没有函数调用,函数体不会执行
3.函数执行流程:调用函数---函数体--调用函数
'''
x=int(input())
y=int(input())
def func_add(a,b):
result=a+b
print(result)
func_add(x,y)
注意点:
1.函数的定义:def
2.函数需要调用才会执行
3.形参:定义函数使用的参数;实参:调用函数的时候使用的值
4.函数的参数不限制
5.函数的return返回值是tuple元组类型。
函数返回值作用:返回结果;退出当前函数
return 要返回多个值得时候,可以通过列表,元祖,字典形式返回。默认是元组类型。
全局变量:
在函数外可以不需要global标志;但是若在函数内定义全局变量,那么必须要有global做标志
#定义全局变量glo_num
def func_test():
global glo_num
glo_num=100
return glo_num
print(glo_num)
result:100
局部变量:
局部变量定义在函数体内部的变量,只在函数内部生效。
作用:在函数体内部,临时保存数据,即当调用完成后,则销毁局部变量。
注意:当已经定义了一个全局变量后,在函数体内定义一个相同的变量名称,这时候相当于函数内定义了一个局部变量,此时内部访问都是局部变量的值。
多函数执行流程:
glo_num=0
def test1():
global glo_num
glo_num=100
print(glo_num)
def test2():
print(glo_num)
print(glo_num) #0此时还未调用函数test1所以取到的是最初的变量值
test2()#0
test1()#100 因为此时已经调用test1了,所以使用test1赋值的全局变量,后面所有都是用这个全局变量
test2()#100
print(glo_num)#100
c='i like you'
d=c.split('i') #str.split('i' , -1) :-1切割的次数,表示全部切割。1表示顺切割1个
print(d) # ['', ' l', 'ke you']
以i为切点,在最前面和最后面切的时候,有单独一个空格
a.replace('原来的值', ' 要替换的值') c.strip().replace(' ','') 删除所有的空格
a.insert(插入位置 , 插入值) list操作:索引,切片,插入:append作为一个元素插入,insert:位置插入(同append一样:[1, 2, [4, 5]]) 删除:del a , a.pop(要删除的元素的位置) , a.remove(位置)
a=[4,5] b=[1,2]
b.insert(2,a) 或者 b+a 或 b.extend(a)
条件表达式(三元操作符)
x,y=1,2;
#三元操作符语法:x if x<y else y
small=x if x<y else y;
print(small)
assert 断言 关键字后面的条件为假时,程序自动崩溃并抛出AssertionError异常=
#assert 1<2
list2=[1,25,4,56]
str=input();
list1=str.split(",");
list1.sort() #排序函数
list1.reverse(); #倒叙函数
#替换成以下
list1.sort(reverse=True)
list2.sort() #对数字进行排序
print(list2)
函数的参数
1.位置参数
调用函数时根据函数定义的参数位置来传递参数
注意:传递和定义参数的顺序及个数必须一致
def func_aa(a,b):
print('hhhhaahaha')
result=func_aa(1,2)
2.关键字参数
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数前面,但是关键字参数之间不存在先后顺序。
#关键字参数
#函数调用通过”key=值“形式加以指定。可以让函数更加清晰,容易使用。提示也清除了参数顺序需求。
def fun_info(name,age,gender):
print(f'my name is {name}, my age is {age} , my gender is {gender}')
fun_info('peng',gender="girl",age=23)
fun_info(age=12,gender='boy',name='xiaongyang')
运行结果:
my name is peng, my age is 23 , my gender is girl
my name is xiaongyang, my age is 12 , my gender is boy
1.3缺省参数
也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认值参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
注意:函数调用时,如果为缺省参数传值,则修改默认参数值,否则使用这个默认值。
def fun_info(name,age,gender='girl'):
print(f'my name is {name}, my age is {age} , my gender is {gender}')
fun_info('peng',age=23)
fun_info(age=12,gender='boy',name='xiaongyang')
1.4不定长参数
用于不确定调用的时候会传递多少个参数。可以用包裹(packing)位置参数,或者包裹关键字参数进行传参。
包裹位置传递
def user_info(*args):
print(args)
user_info('tto')
user_info('cs',23,'sc')
执行结果:
('tto',)
('cs', 23, 'sc')
注意:所有传递的数据都会被args变量收集,会根据传递的参数为值合并为一个元组,args是元组类型
#包裹关键字传递
def user_info1(**kwargs):
print(kwargs)
user_info1(name="tom",age=11,id=1)
#{'name': 'tom', 'age': 11, 'id': 1}
注意:通过关键字传递的结果是字典
函数返回值作为参数传递:
def test1():
a=100
return a
def test2(num):
print(num)
test2(test1)#返回的值是内存地址:<function test1 at 0x012B8420>
test2(test1())#100
一个函数想要返回多个返回值的定义:
def test1():
return 1,2
def test2(num):
print(num)
res=test1()
print(res)#(1, 2)注意返回的是一个元组
注意:
1.return a,b 返回多个数据。数据类型默认是元组
2.return后可连接元组,字典列表等数据形式,达到一次返回多个数据
递归函数和匿名函数
特点:
1.函数内部自己调用自己
2.必须有出口
lambda函数
如果一个函数有一个返回值,并且只有一句代码,可以使用lambda简化
语法:lambda 参数列表:表达式
注意事项:
1.lambda表达式的参数可有可无,函数的参数在lambda表达式中完全适用;
2.lambda表达式能接受任何数量的参数但只能返回一个表达式的值。
fn1=lambda :1
print(fn1) #<function <lambda> at 0x0000019E48DA3E20> 函数在内存中分配的地址
print(fn1()) #1
计算两个数值的累加
fn2=lambda a,b:a+b
print(fn2(1,2))
#一个参数
fn2=lambda a:a
print(fn2('ghh')) #ghh
#默认参数
fn3=lambda a,b,c=100:a+b+c
print(fn3(1,2)) #103
#不确定参数个数 返回的结果是元组
fn4=lambda *args:args
print(fn4(1,2,3,4,5,6,7,8,9)) #元组(1, 2, 3, 4, 5, 6, 7, 8, 9)
#可变参数:**kwargs 返回的结果是字典
fn5=lambda **kwargs:kwargs
print(fn5(name='qiqi',age=12,gender='girl'))
#{'name': 'qiqi', 'age': 12, 'gender': 'girl'}
#lambda判断
fn6=lambda a,b:a if a>b else b
print(fn6(100,40)) #100
Lambda的实际运用:
#列表里的数据按字典key的值排序
students=[
{'name':'tom','age':12},
{'name':'qq','age':35},
{'name':'qwwqe','age':34}
]
#按name值升序排序
students.sort(key=lambda x:x['name'])
print(students)
#按age升序排序
students.sort(key=lambda x:x['age'])
print(students)
#按age降序排序
students.sort(key=lambda x:x['age'],reverse=True)
print(students)
运行结果:
[{'name': 'qq', 'age': 35}, {'name': 'qwwqe', 'age': 34}, {'name': 'tom', 'age': 12}]
[{'name': 'tom', 'age': 12}, {'name': 'qwwqe', 'age': 34}, {'name': 'qq', 'age': 35}]
[{'name': 'qq', 'age': 35}, {'name': 'qwwqe', 'age': 34}, {'name': 'tom', 'age': 12}]
range函数
range()的用法
1.range(start,end) 左含右不含
for i in range(10) 遍历1-9的数字,默认从0开始
print(i)
2.range(start,end) 左含右不含
for i in range(1,10) 遍历1-9的数字,默认每次加1
print(i)
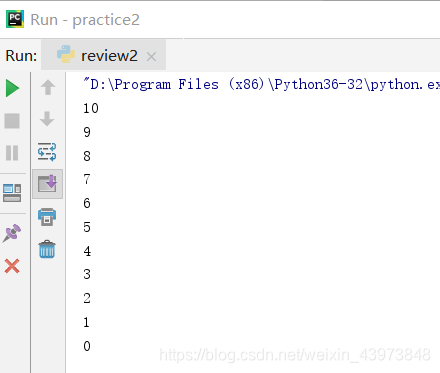
3.range(start,end step) 倒序输出
for i in range(10,-1,-1)
print(i)
此时的结束值为-1,而-1取不到,因此取到0,长是-1,相当于每次-1。
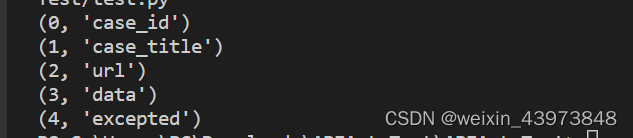
内置函数enumerate
将可遍历的数据类型组合为一个索引序列。以字典形式输出。
title=['case_id', 'case_title', 'url', 'data', 'excepted']
for data in enumerate(title):
print(data)
高阶函数
含义:把一个函数作为参数传入
优势:函数式编程大量使用函数,减少了代码的重复,代码更简洁
def sum_num(a,d,f):
return f(a)+f(d)
res=sum_num(1,-2.222,abs)
res1=sum_num(1,2.3,round)
print(res) #3.22
print(res1) #3
1.高阶函数map
map(func,list列表)将传入的函数变量func功能作用到列表变量list的每个元素中,并将结果组成虚拟的迭代器返回
#1.准备数据
list1=[1,2,3,4,5]
#2.定义函数
def func(x):
return x**2
#3.调用函数
res=map(func,list1)
print(res) #<map object at 0x00000264E7856D40>
print(list(res)) #[1, 4, 9, 16, 25]
2.高阶函数reduce
reduce(func,lst)其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累计计算
#注意:reduce传入的参数func必须接受2个参数
#题目:计算list1序列的各个数字累加和
#1.导入模块
#2.制造数据
import functools
list1=[1,2,3,4]
#3.定义函数
def func(a,b):
return a+b
res=functools.reduce(func,list1)
print(res) #10
3.高阶函数filter
filter(func,list)过滤掉list列表中不符合func函数功能条件的元素,返回一个filter对象。如果要将其转换为列表,用list()即可
list1=[1,2,3,4,5,6,7,8,9]
def func(x):
return x%2==0
res=filter(func,list1)
print(res) #<filter object at 0x000002972E296D70>
print(list(res)) #[2, 4, 6, 8]
类的定义
类是面向对象编程(OOP)中的核心概念,用于封装数据和行为。以下是类的优缺点:
优点
- 封装性:类将数据和方法封装在一起,隐藏内部实现,只暴露必要的接口,增强了代码的安全性和可维护性。
- 代码复用:通过继承,子类可以复用父类的代码,减少重复编写,提升开发效率。
- 模块化:类将代码划分为独立的模块,便于管理和维护,降低了代码的复杂性。
- 可扩展性:通过继承和多态,类可以轻松扩展功能,适应新需求。
- 多态性:多态允许不同类的对象对同一消息做出不同响应,增强了代码的灵活性和可扩展性。
- 抽象性:类可以定义抽象方法或接口,强制子类实现特定功能,确保设计的一致性。
- 易于维护:类的封装性和模块化使得代码更易维护和调试。
缺点
- 复杂性:类的设计可能增加代码的复杂性,尤其是多重继承和复杂层次结构时。
- 性能开销:类的实例化和方法调用可能带来额外的性能开销,尤其在需要频繁创建和销毁对象的场景中。
- 过度设计:过度使用类可能导致设计过于复杂,增加不必要的抽象层次。
- 学习曲线:面向对象编程的概念(如继承、多态)对初学者可能较难掌握。
- 内存占用:每个对象实例都会占用内存,大量对象可能导致内存消耗增加。
- 紧耦合:如果类设计不当,可能导致类之间过度依赖,增加代码的耦合性,影响灵活性和可维护性。
类的定义:
class People:
classname="hh" #静态属性
p=People()
print(p.classname)
class People:
classname="hh" #静态属性
def __init__(self,name): #实例属性定义(初始化函数),self调用自己的参数
self.myname=name
#静态方法
@staticmethod
def bellow():
print("name") #静态方法所有实例都会用,以@staticmethod修饰
def tell(self): #实例方法
print(f 'hallo...{self.myname}')
p=People(215) #只要有实例属性定义,都要实例化(带参数)
print("我是",p.classname)
p.bellow()
p.tell()
p2=People("xcsc")
print("我是",p2.myname)
p2.bellow()
p2.tell()
代码:学生信息管理:
```php
def ui_func():
print('请选择功能--------')
print('1.添加学员')
print('2.删除学员')
print('3.修改学员')
print('4.查询学员信息')
print('5.退出系统exit')
print('*'*15)
info_dict={'name':'zz','id':21,'phone':12345}
info=[]
def add_stu():
'''添加学员函数'''
global info
#输入的数据:
new_name=input('请输入姓名:')
id_stu=int(input('请输id:'))
phone=input('请输入您的电话:')
#如果重名,则不再重复添加
for i in info:
#print(i['name'])
if new_name==i['name']:
print('该名字已存在。')
return
info_dict['id']=id_stu
info_dict['name']=new_name
info_dict['phone']=phone
#列表追加字典
info.append(info_dict)
#print(info_dict)
print(info)
def del_stu():
del_name=input('请输入需要删除的学员名字')
#判断输入的学员名称是否有存在,不存在则报错
for i in info:
if del_name==i['name']:
print(i)
info.remove(i)
print('删除成功')
break
else:
print('该用户不存在,操作错误')
#print(info)
def update_stu():
inp_name=input("请输入要修改原的名字:")
new_name=input("请输入要修改的新名字:")
# new_id=input('请输入新的id:')
# new_phone=input('请输入新的phone:')
for i in info:
if inp_name==i['name']:
i['name']=new_name
print(info)
break
else:
print('输入的名字不存在,请重新输入。。。')
def stu_info():
print(info)
#按用户输入的功能执行不同的操作
while True:
ui_func()
user_num = int(input('请输入功能序号:'))
if user_num==1:
#print('添加学员')
add_stu()
elif user_num==2:
#print('删除')
del_stu()
elif user_num==3:
#print('修改')
update_stu()
elif user_num==4:
#print('显示学员')
stu_info()
elif user_num==5:
print('退出系统!')
break
else :
print("输入的数字有误,请重新输入。。。")
模块,包,库
模块modules是包含python函数和变量的文件,名称符合python标识符要求,并使用.py为后缀。
包package是包含其他模块、包的文件夹,名称符合python标识符要求,并且必须有一个__init__.py文件。(有了init文件才叫做包,才能被别的类找到调用。)
库library模块、包的集合。
1.导入本包中的模块
import 文件名
文件名.方法(参数)
例如:
import hahaha
hahaha.get_xiao()
2.从不同的包中导入不同的模块
from 包 import 文件名
文件名.方法(参数)
3.从不同包中导入相同模块
方法1:
from 包1 import 文件名1(new_文件夹)
from 包2 import 文件名2(new1_文件夹)
文件名.方法() //以最近的包中文件名调用
new_文件夹.方法()
方法2:通过导入包名.模块名
from 包名.模块名 import 方法名 【as new_name 别名】
不同的包中导入多个模块
from 包名 import 模块,模块,模块等等
总结:
1.从自己包中导入模块,直接用import 模块名
2.从不同的包中导入模块用from 包名 import 模块名
3.从不同的包中导入相同的模块时,用as别名
4.同个包中一次性导入多个模块时用逗号隔开
注意:导入数据中,只有import后面的内容可以直接使用。
五、文件操作
文件操作步骤:
1.打开文件
2.读写等操作
3.关闭文件
#open(name,mode) 可以打开一个已存在的文件,或创建一个新文件
#name:是要打开的目标文件名的字符串(包含文件所在的具体路径)
#mode:设置打开文件的模式:只读,写入,追加等
#1.打开文件open()
f=open('test.txt','w')
#2.读写操作write,read
f.write('abd')
#3关闭
f.close()
文件的访问模式:

- r 模式下:若文件不存在,则会直接报错。r表示只读
文件读取
文件对象.read(num):num表示要从文件读取的数据的长度,单位是字节,若没有传入num,则表示读取文件中所有的数据
f=open('test.txt')
res=f.read(8)
print(res)
结果:
abd (此行有个换行符\N占一个字节)
111,
readlines() :按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
readline():依次读取一行内容
f=open('test.txt')
res1=f.readlines()
print(res1) #['abd\n', '111,222\n', '333\n', '444']
f=open('test.txt')
res1=f.readline()
print(res1)
res2=f.readline()
print(res2)
运行结果:
abd
111,222
seek函数
作用:用来移动文件指针
语法:文件对象.seek(偏移量,起始位置)
起始位置:
0:开始开头
1:当前位置
2:文件结尾
实践使用:
1.以 r 模式打开文件时,用来改变读取文件指标的位置或者把文件指针放结尾(无法读取数据)
2.以 a 模式打开文件时,做到可以读取数据
f=open('test.txt','r+')
# c=f.read()
# print(c) # 读取的是文件中的所有数据
#改变文件指针位置参数
f.seek(2,0)
c1=f.read()
print(c1) #从文件开头开始读取,数据偏移两个位置,即从文件第三个数据开始读取
文件备份
#1.接受用户输入的文件名
old_name=input("请输入要备份的文件名:")
#2.先提取文件名,然后组织新的名字
#通过rfind查找某子串
index=old_name.rfind('.')
print(index)
#获取源文件名:
print(old_name[:index])
#获取后缀名:
print(old_name[index:])
#组织新的文件名:
print(old_name[:index]+'备份'+old_name[index:])
new_name=old_name[:index]+'备份'+old_name[index:]
#3.打开源文件和备份文件
old_file=open(old_name,'rb')
new_file=open(new_name,'wb')
#4.源文件读取,备份文件写入
#如果不确定目标文件大小,循环读取写入,当读取出来的数据美誉了再终止循环
while True:
con=old_file.read()
if len(con)==0:
break
new_file.write(con)
#关闭文件
old_file.close()
new_file.close()
思考:若文件是无效文件,如何处理,如.txt
有效文件才备份
if index>0:
postfix=old_name[index:]
new_name=old_name[:index]+‘备份’+postfix
文件和文件夹的操作
python中文件和文件夹的操作要借助os模块里面的相关功能,具体步骤如下:
#1.导入模块
#2.使用模块内功能
import os
#重命名 rename(old_name,new_name)
os.rename('1.con','1.txt.con')
#remove删除文件
os.remove('1.txt.con')
#1.导入模块
#2.使用模块内功能
import os
#创建文件夹
#os.mkdir('dir')
#删除文件夹
#os.rmdir('dir')
#获取当前目录
path=os.getcwd()
print(path) #C:\Users\PD\PycharmProjects\marchine_test
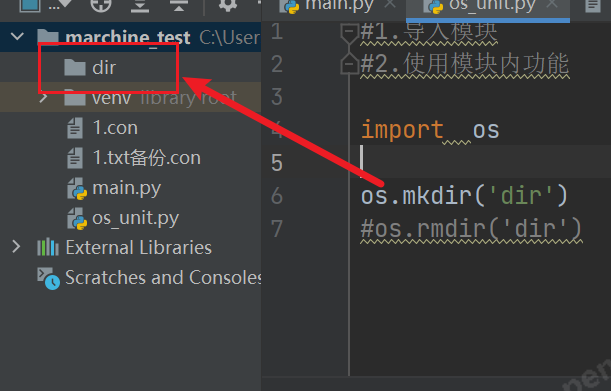
#改变当前默认目录
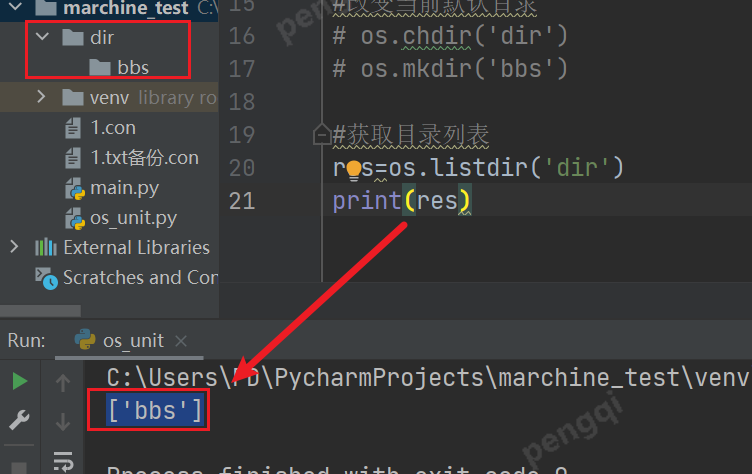
# os.chdir('dir')
# os.mkdir('bbs')
#获取目录列表
res=os.listdir('dir')
print(res)
#需求:把code文件夹的所有文件重命名为python_xxx
#1.找到所有文件:获取code文件夹目录列表
import os
file_list=os.listdir()
print(file_list)
#2.构造名字
for i in file_list:
new_name='python'+i
#3.重命名
os.rename(i,new_name)
#需求:删除python-重命名 flag=1重命名为python_XXX;flag=2时返回为原来的名称
#1.构造条件的数据
import os
flag=1
#2.书写if
file_list=os.listdir()
print(file_list)
for i in file_list:
if flag==1:
new_name='python_'+i
elif flag==2:
num=len('python_')
new_name=i[num:]
os.rename(i,new_name)
编码与解码
编码:通过编码方式将字符编码成计算机才能识别的二进制字节,比如:utf-8,gbk,gbk2312等。这样计算机才能正常运行所写的代码。
解码:解码就是将机器可识别的字节码转化成人类可识别的字符。按照编码的方式来进行解码,对于不同的编码方式有自己对应的字符表。所以编码和解码操作需要时同一种方式,否则无法正常解码。
Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
因此若要解决该问题,就必须先将编码格式修改为utf-8
Unicode字符串可以与任意字符编码的字节串相互转换,所以python2中的字符串时进行字符编码转换的过程是先按照原来的方式解码为unicode,然后再编码解码:
字节串(Python2的str默认是字节串)–>decode(‘原来的字解码’)–>Unicode字符串–>encode(‘新的字符编码’)–>字节串
由于python3中定义的字符串默认就是unicode,因此不需要先解码,直接编码成新的字符编码。
字符串(str就是Unicode字符串)–>encode(‘新的字符编码’)–>字节串
import sys
s='你好呀'
a=s.encode('gbk')
print(a) #b'\xc4\xe3\xba\xc3\xd1\xbd'
b=a.decode('gbk')
print(b) #你好呀
异常处理
顾名思义:就是对程序代码运行过程中产生的异常问题进行捕获处理,防止程序终止执行。
异常是Python对象,表示一个错误。
try/except/else语法:
try:
x=1/0
except ZeroDivisionError:
print("被除数不能为0")
else:
print(x)
#result:被除数不能为0
try里面的内容是我们认为可能出现异常的代码语句,except下是捕获到异常,对异常进行的处理;else是try中的语句没有发生异常时执行的下一步代码。
参考:https://www.runoob.com/python/python-exceptions.html
触发异常raise
我们可以使用raise语句自己触发异常,格式如下:
def funerror(level):
if level<0:
raise Exception("Invalid level :",level)
print("hahahaha")#触发异常后该语句不会执行
print(funerror(-1))
#result:Exception: ('Invalid level :', -1)
六、标准库
python的标准库是内置的、可以直接使用的库。
标准库非常丰富,提供了广泛的功能,比如操作系统概念的数据解决,数学计算,文件管理等等。
主要介绍:
- csv
- time
- random
- turtle
时间的起点:1970年1月1日 00:00:00(UTC时间)
strftime()将时间格式化展示
print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()))
#2023-07-20 11:50:44
print(time.strptime("2020-01-01 11:11:11","%Y-%m-%d %H:%M:%S"))
#time.struct_time(tm_year=2020, tm_mon=1, tm_mday=1, tm_hour=11, tm_min=11, tm_sec=11, tm_wday=2, tm_yday=1, tm_isdst=-1)
random伪随机数
print(random.random())
#0.3563162487715491
print(random.randrange(0,100,1))
#97
print(random.randint(1,20))
#3
turtle
海龟画图
from turtle import *
color('red','yellow')
begin_fill()
while True:
forward(200)
left(170)
if abs(pos())<1:
break
end_fill()
done()

第三方库
第三方库是指非python内置的其他库,一般托管在PyPI上,使用前需要安装。
pip(Package Installer for Python)python内置的包管理工具,用来从pypi安装、更新、卸载第三方库。
pip install 库名
pip install 库名 -U
pip uninstall 库名
为了更好的使用pip安装第三方库,可以先配置好pypi国内源环境。
第三方库:
- jieba
- wordcloud
- requests
- pyinstall
jieba
s=‘我来到深圳南山恒大天璟’
jieba.cut(s)
wordcloud
text=‘qq rr wd ff fgg’
wc=WordCloud()
wc.generate(text)
wc.to_file(“1.png”)
import numpy as np
mask=np.array(Image.open(‘xxx.png’))
加蒙层:WordCloud(mask=mask)
以图片内容作为背景轮廓,然后文字填充图形。
pyinstall
将程序需要的依赖包自动安装,减少不同电脑之间使用的复杂度。
pyinstaller xxx.py -F
生成一个exe文件,双击文件就可以自动去寻找依赖包。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









