







笔记:
标题
招标方:供应商
中标方:发布机构
成交时间 = 中标时间:发布日期
中标金额:成交金额
只要“结果公告、结果公示”
项目背景
政府的采购意向一向是许多中大型公司的主营业务之一,因此,实时动态的掌握政府的采购信息能够更有效的帮助企业盈利,这次我们的目标是商洛市政府网下面的招标与中标公告两个板块,主要通过中标公告所提供的信息,我们将会从中抽取相关的实体:招标方、中标方、中标时间、中标金额、成交时间等并将其保存在mysql数据库中。

网页分析
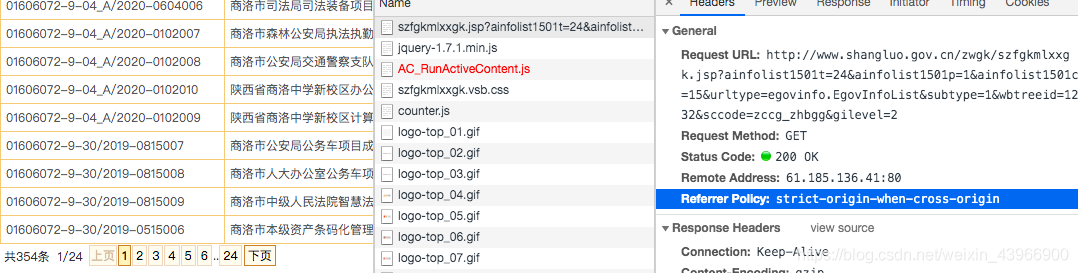
分析主页面,获取网页url,找到控制页数的参数:
控制台截图:
查询字符串截图:
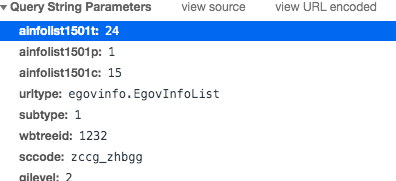
猜想参数"p"控制页数。
验证:http://www.shangluo.gov.cn/zwgk/szfgkmlxxgk.jsp?ainfolist1501t=24&ainfolist1501p=2&ainfolist1501c=15&urltype=egovinfo.EgovInfoList&subtype=2&wbtreeid=1232&sccode=zccg_zhbgg&gilevel=2
发现确实是第二页:

基础网页分析到此结束,关于内容网页的分析会在“技术实现”中说明
技术流程图
技术实现
历史数据爬取
一开始的技术方案是使用串行的方式爬取所有的历史数据,但是发现速度慢如乌龟,于是决定使用并行的方式进行爬取,所使用的模块为
“concurrent.futures.ThreadPoolExecutor”,即使用多线程技术来进行爬取,中间有一段阻塞的时间,正好可以作为一种规避反爬虫的手段,因为在实际试验中发现,此网站的反爬手段非常单一,即封禁访问频繁的IP,那么在产生大量访问之前,根据试验发现,休息一下可以产生一定的迷惑效果,减少被封的次数,此外我也在其他方面做了改进以应对这种策略,这部分放在“技术优势”来讲。数据库采用了mysql,所有爬取到的数据经过实体抽取以后将以字符创的形式存入。
爬虫主体
def spider(url, headers):
success = False
while not success:
try:
res = requests.get(url, headers=headers)
success = True
except:
num = time.sleep(random.randint(5,20))
print("糟糕,你的爬虫被发现了!!但是别担心,{}秒后我们就会重启!嘿嘿".format(num))
# requests默认的编码是‘ISO-8859-1’,会出现乱码,这里重编码为utf-8
res.encoding = 'utf-8'
return res.text
spider函数负责处理请求与响应,将requests经过简单的封装以后,它拥有了一项新的功能,那就是不间断对某个链接尝试访问,如果出错,就间隔5到20s再发起请求。
获取网页url
在用并行处理这个问题的时候,受限于mapreduce框架,我只能获取到全部的url再进行请求处理,所以一共会有两段并发请求过程。
# 爬取历史数据
# 打开数据库连接
info = {
"host": "localhost",
"user": "root",
"password": "haizeiwang",
"db": "TESTDB",
"charset": "utf8" # 一定要加上负责中文无法显示
}
db = database(info)
# 创建数据表,如果存在则删除
db.create_table()
st = time.time()
# 定义原始页面url
page_url = "http://www.shangluo.gov.cn/zwgk/szfgkmlxxgk.jsp?ainfolist1501t=24&ainfolist1501p={}&ainfolist1501c=15&urltype=egovinfo.EgovInfoList&subtype=2&wbtreeid=1232&sccode=zccg_zhbgg&gilevel=2"
# 定义拼接字符串
content_url = "http://www.shangluo.gov.cn"
"""并行方案: 用两遍多线程,一遍获得所有的url,一遍过得所有的实体列表"""
# 生成所有页面url
urls = [page_url.format(i) for i in range(1, 25)]
"""开启页面线程池子"""
executer = ThreadPoolExecutor(max_workers=8)
# 生成map对象
concent_concurrent_url_list = executer.map(get_all_content_url, urls)
# 实例化map对象,获得所有内容url
_concent_concurrent_url_list_maped = list(concent_concurrent_url_list)
# 将列表展开
concent_concurrent_url_list_maped = []
for j in _concent_concurrent_url_list_maped:
for k in j:
concent_concurrent_url_list_maped.append(content_url + k)
# # ---阻塞---
print("页面线程已全部结束,进入10秒睡眠")
time.sleep(10)
print("睡眠结束,进入内容线程阶段" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









