




 本文深入探讨了聚类算法,特别是K-MEANS和DBSCAN算法的原理与应用。介绍了K-MEANS算法的工作流程,包括质心的概念、距离度量方式、优化目标以及图像压缩的应用。同时,提到了DBSCAN算法作为密度基聚类方法的特点。
本文深入探讨了聚类算法,特别是K-MEANS和DBSCAN算法的原理与应用。介绍了K-MEANS算法的工作流程,包括质心的概念、距离度量方式、优化目标以及图像压缩的应用。同时,提到了DBSCAN算法作为密度基聚类方法的特点。
聚类属于无监督学习算法,将相似的数据分到一组,其难点是:如何评估聚类效果,如何调参。
K-MEANS算法
-
聚类前需要指定簇的个数:K值。
-
质心:每个簇的均值点,对向量各维取平均。
-
距离的度量:需要求样本点到质心的距离,常用欧式距离和余弦相似度(先标准化)。
-
优化目标:min∑i=1k∑xϵCidist(ci,x)2min\sum_{i=1}^{k} \sum_{x\epsilon C_{i}}dist(c_{i},x)^{2}min∑i=1k∑xϵCidist(ci,x)2 ,其中cic_{i}ci为第iii簇的质心。
-
工作流程:
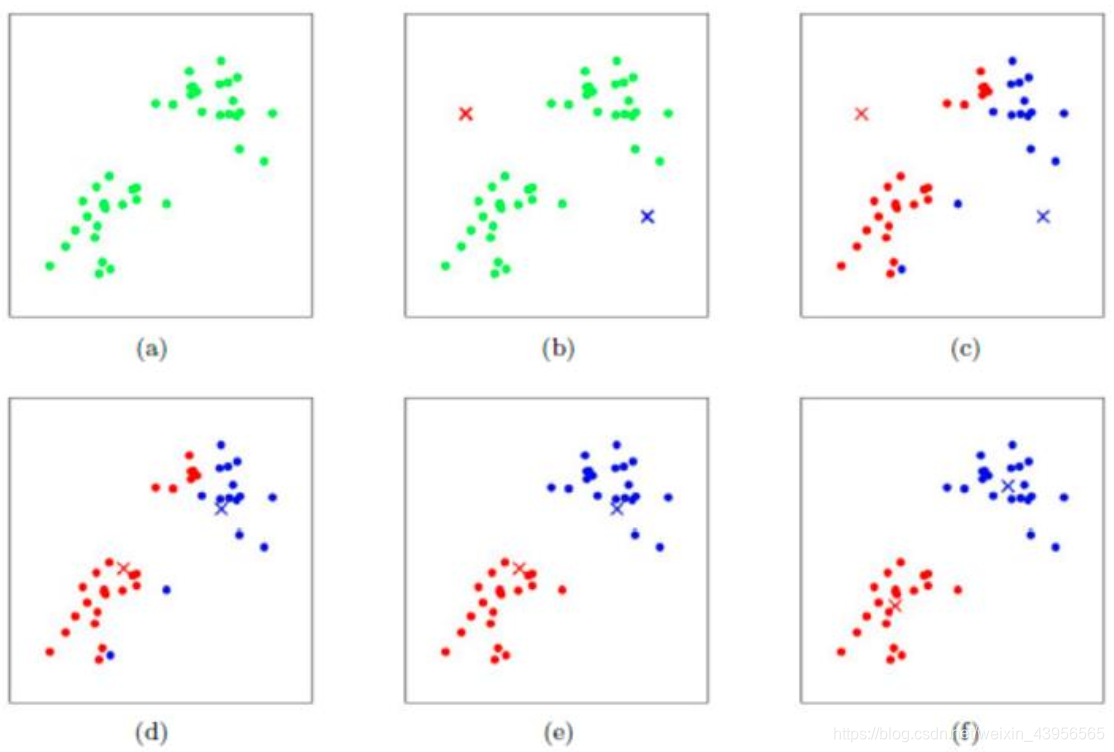
-
(a)样本点,令K=2;(b)初始化两个质心;(c)遍历样本点,求其到两个质心的距离,哪个距离小,样本点则归为那类;(d)更新簇的质心;(e)重复c,d,直到质心不再变化;(f)聚类结果。
-
K-MEANS算法 优势:简单、快速、适合常规数据集。
-
K-MEANS算法 劣势:K值难确定;计算复杂度与样本呈线性关系;难以发现任意形状的簇(如环绕形的数据)。注:初始点的选择对聚类结果影响较大。
-
使用K-MEANS算法进行图像压缩:
- 将像素值范围[0, 255]的三通道图像压缩为像素值范围[0, 127]的单通道图像。
from skimage import io
from sklearn.cluster import KMeans
import numpy as np
image = io.imread('test.jpg')
# io.imshow(image)
# io.show()
rows = image.shape[0]
cols = image.shape[1]
image = image.reshape(rows*cols, 3)
kmeans = KMeans(n_clusters= 256, n_init=10, max_iter=1)
kmeans.fit(image)
clusters = np.asarray(kmeans.cluster_centers_,dtype=np.uint8)
labels = np.asarray(kmeans.labels_, dtype=np.uint8)
print(labels.shape)
labels = labels.reshape(rows, cols)
np.save('codebook.npy', clusters)
io.imsave('compressed.jpg', labels)
DBSCAN算法
- Density-Based Spatial Clustering of Applications with Noise

















 2240
2240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









