







目录
MVCC(Multiversion Concurrency Control),即多版本并发控制,其最大的好处是读不加锁,有效地提高了并发性,同时还保障了事务的隔离性。
InnoDB中利用MVCC解决了幻读问题。
一、MVCC的实现原理
- MVCC 的实现基于 两个隐藏字段 、 undo log 和 Read View 。
MVCC与undo log的关系
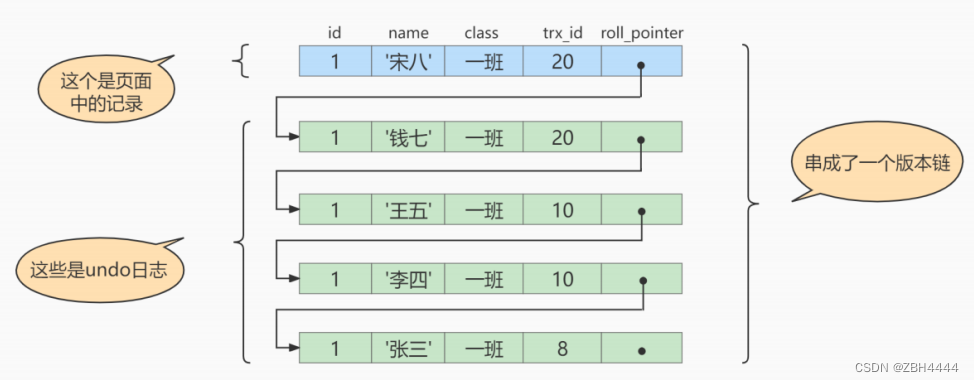
对记录每次更新后,都会将旧值放到一条 undo 日志中,成为该记录的一个旧版本,所有的版本被 roll_pointer 属性连接成一个链表,称为版本链。
Read View
Read View的构成
- creator_trx_id: 创建该 Read View 的事务的 ID(只有涉及改动的事务才会记录 ID,只读的事务的 ID 默认为0)。
- trx_ids: 在生成该 Read View 时系统中活跃的读写事务的事务 ID 列表。
- up_limit_id: 活跃的事务列表中最小的事务的 ID。
- low_limit_id: 表示生成该 Read View 时系统中应该分配给下一个事务的 ID 值,即系统中现在最大的事务 ID。
Read View相当于是给当前的系统拍了一张“快照”。
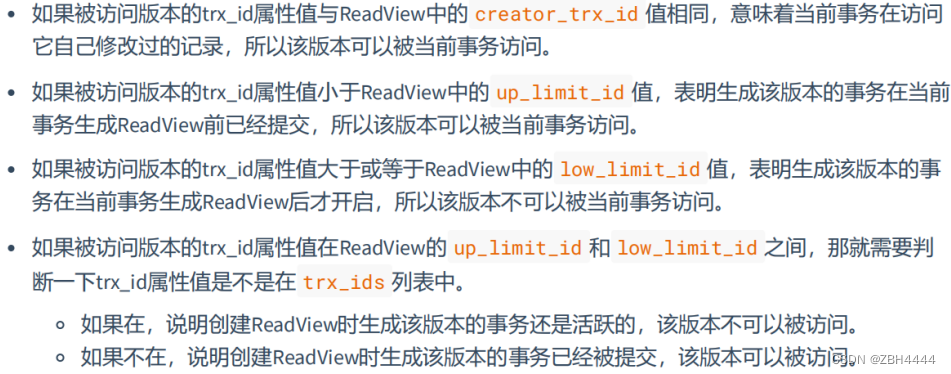
Read View的规则
MVCC的整体流程
MVCC 查询一条记录的流程:
- 首先获取事务自己的版本号,即事务 ID。
- 获取 Read View。
- 查询数据,然后与 Read View 进行比较。
- 如果不符合 Read View 的规则,则从 undo log 中获取历史快照。
- 最后返回符合规则的数据。
二、MVCC解决脏读、不可重复读与幻读
脏读
当隔离级别为读已提交(Read Committed) 时,一个事务中的每一次SELECT查询都会重新获取一次 Read View。
所以可以避免脏读,但是若 2 个SELECT的 Read View 不同,就会产生不可重复读或幻读。
不可重复读与幻读
当隔离级别为可重复读(Repeatable Read) 时,一个事务只在第一次SELECT时获取一次 Read View,后面所有的SELECT都用这个 Read View。
所以可以避免不可重复读;同时SELECT查出的数据需要依次与 Read View 进行比较,如果后面的SELECT查出的数据中有新插入的记录,那么在根据 Read View 比较的时候就会发现其 trx_id 在 trx_ids 列表中或大于等于 low_limit_id ,进而会被丢弃,所以可以避免幻读。


















 2540
2540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











