






抽时间断断续续完成代码的片段画图解析
代码片段解析1
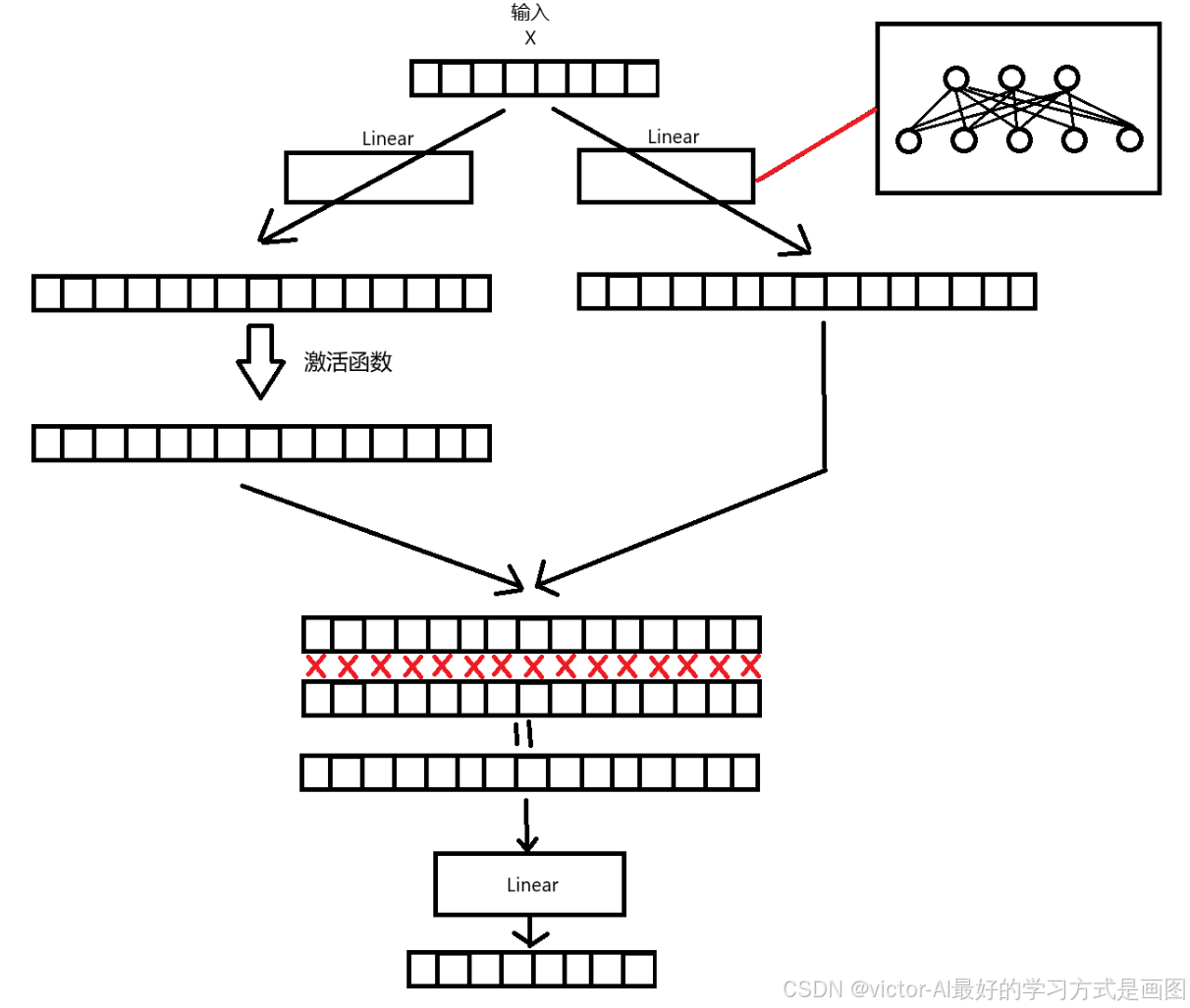
class Expert(nn.Module):
"""
Expert layer for Mixture-of-Experts (MoE) models.
Attributes:
w1 (nn.Module): Linear layer for input-to-hidden transformation.
w2 (nn.Module): Linear layer for hidden-to-output transformation.
w3 (nn.Module): Additional linear layer for feature transformation.
"""
def __init__(self, dim: int, inter_dim: int):
"""
Initializes the Expert layer.
Args:
dim (int): Input and output dimensionality.
inter_dim (int): Hidden layer dimensionality.
"""
super().__init__()
self.w1 = Linear(dim, inter_dim)
self.w2 = Linear(inter_dim, dim)
self.w3 = Linear(dim, inter_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Forward pass for the Expert layer.
Args:
x (torch.Tensor): Input tensor.
Returns:
torch.Tensor: Output tensor after expert computation.
"""
return self.w2(F.silu(self.w1(x)) * self.w3(x))
Gate门控网络
# 这段代码定义了一个名为 Gate 的 PyTorch 模块,通常用于混合专家模型(Mixture-of-Experts,MoE)中的路由机制。该模块的作用是根据输入的特征来路由到多个“专家”,并且通过一定的门控机制来决定哪些专家会被激活。下面逐行解析代码:
class Gate(nn.Module):
"""
super().__init__():调用父类 nn.Module 的构造函数,以确保正常初始化 PyTorch 的模块。
self.dim:输入特征的维度。
self.topk:每个输入激活的专家数量。
self.n_groups:用于路由的专家组数量。
self.topk_groups:用于路由的“有限组”数量。
self.score_func:选择评分函数,可以是 softmax 或 sigmoid,决定了路由机制的计算方式。
self.route_scale:路由权重的缩放因子。
"""
def __init__(self, args: ModelArgs):
"""
Initializes the Gate module.
Args:
args (ModelArgs): Model arguments containing gating parameters.
"""
super().__init__()
self.dim = args.dim
self.topk = args.n_activated_experts
self.n_groups = args.n_expert_groups
self.topk_groups = args.n_limited_groups
self.score_func = args.score_func
self.route_scale = args.route_scale
# torch.empty():这个函数创建一个指定形状的张量,但并不对其进行初始化。返回的张量的值是未初始化的,因此它们的内容是随机的,依赖于内存中原始的数据。通常,在后续训练过程中,PyTorch 会自动将这些张量初始化为适当的值。
# args.n_routed_experts :这个参数表示“路由到的专家数量”。在 MoE(Mixture of Experts)模型中,每个输入会选择多个专家来进行处理。因此,这个维度的大小对应了每个输入将路由到的专家的数量(即输出的专家数量)。
self.weight = nn.Parameter(torch.empty(args.n_routed_experts, args.dim))
self.bias = nn.Parameter(torch.empty(args.n_routed_experts)) if self.dim == 7168 else None
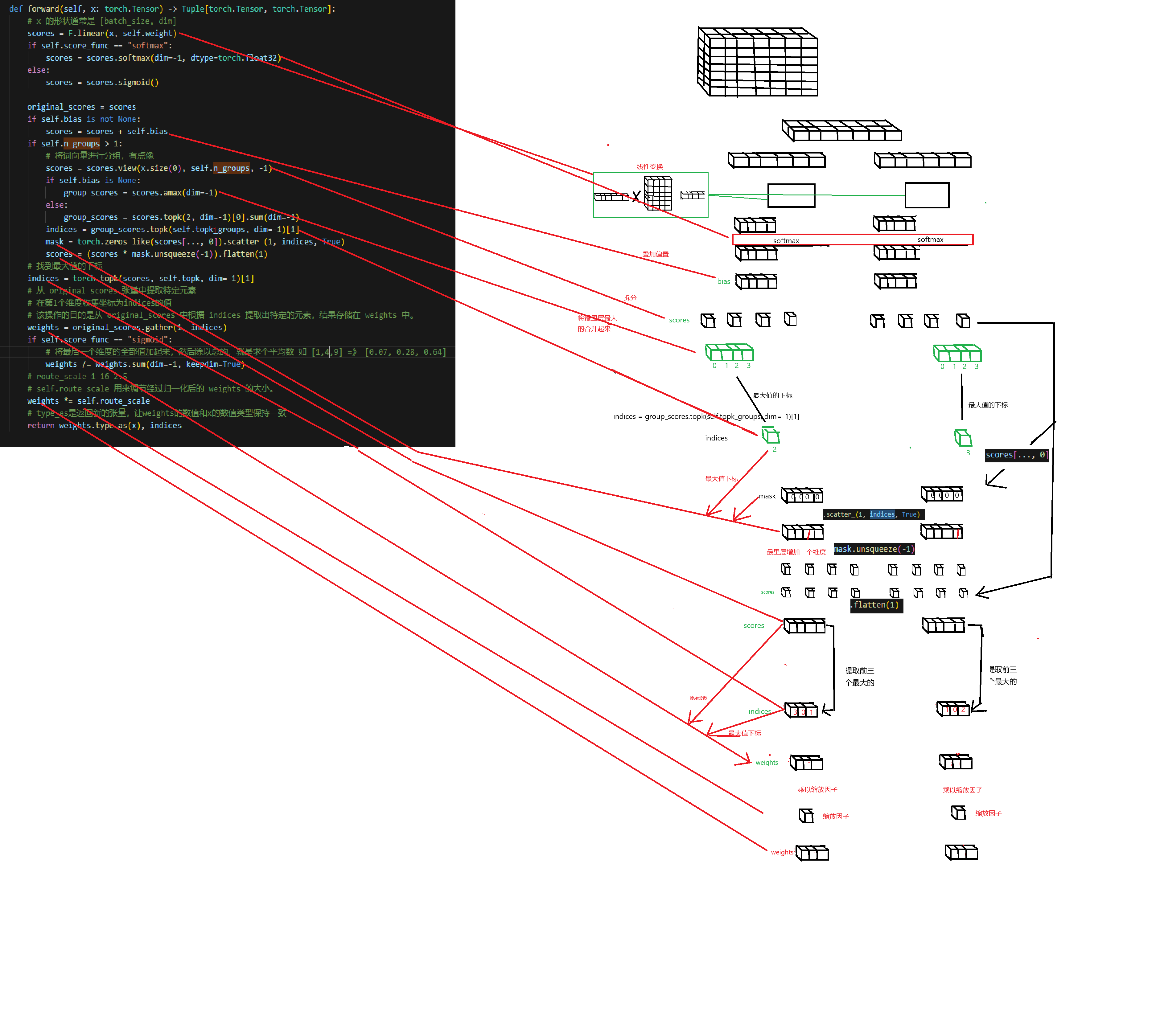
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
# x 的形状通常是 [batch_size, dim]
scores = linear(x, self.weight)
if self.score_func == "softmax":
scores = scores.softmax(dim=-1, dtype=torch.float32)
else:
scores = scores.sigmoid()
original_scores = scores
if self.bias is not None:
scores = scores + self.bias
if self.n_groups > 1:
# 将词向量进行分组,有点像
scores = scores.view(x.size(0), self.n_groups, -1)
if self.bias is None:
# amax 是 PyTorch 中的一个张量方法,用于在指定维度上找到张量的最大值,舍弃一个维度
group_scores = scores.amax(dim=-1)
else:
# 提取最里维度的前两个最大值并加起来
group_scores = scores.topk(2, dim=-1)[0].sum(dim=-1)
# 记录最里维度的前两个最大值的下标
indices = group_scores.topk(self.topk_groups, dim=-1)[1]
# zeros_like 用于创建一个与给定张量形状相同、但所有元素都为 零 的新张量。
# scores[..., 0] 分别提取最里维度第一个值组合成一个维度,最终减少了一个维度
# tensor.scatter_(dim, index, src) dim=0 表示沿着行操作,dim=1 表示沿着列操作。 index是坐标, True是填充的值
mask = torch.zeros_like(scores[..., 0]).scatter_(1, indices, True)
# unsqueeze指定维度插入一个维度
# flatten的作用是将张量展平(flatten)为一维张量
scores = (scores * mask.unsqueeze(-1)).flatten(1)
# 找到最大值的下标
indices = torch.topk(scores, self.topk, dim=-1)[1]
# 从 original_scores 张量中提取特定元素
# 在第1个维度收集坐标为indices的值
# 该操作的目的是从 original_scores 中根据 indices 提取出特定的元素,结果存储在 weights 中。
weights = original_scores.gather(1, indices)
if self.score_func == "sigmoid":
# 将最后一个维度的全部值加起来,然后除以总的,就是求个平均数 如 [1,4,9] =》 [0.07, 0.28, 0.64]
weights /= weights.sum(dim=-1, keepdim=True)
# route_scale 1 16 2.5
# self.route_scale 用来调节经过归一化后的 weights 的大小。
weights *= self.route_scale
# type_as是返回新的张量,让weights的数值和x的数值类型保持一致
return weights.type_as(x), indices
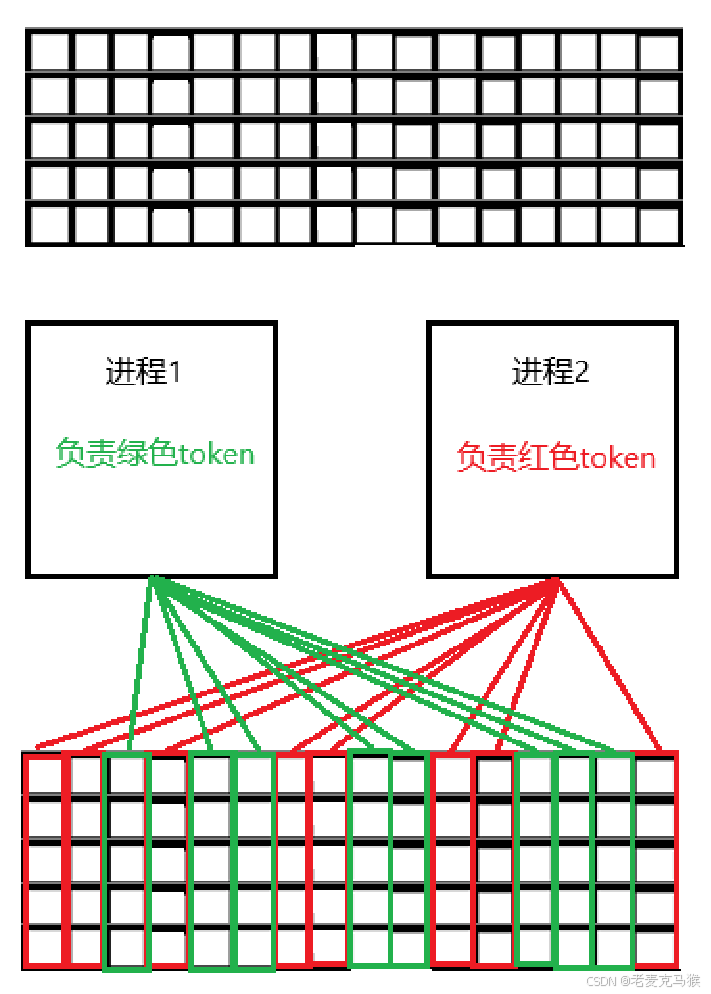
并发 Embedding 层
class ParallelEmbedding(nn.Module):
"""
Embedding layer with parallelism support across distributed processes.
Args:
vocab_size (int): Vocabulary size.
dim (int): Embedding dimension.
"""
def __init__(self, vocab_size: int, dim: int):
super().__init__()
self.vocab_size = vocab_size
self.dim = dim
assert vocab_size % world_size == 0, f"Vocabulary size must be divisible by world size (world_size={world_size})"
self.part_vocab_size = (vocab_size // world_size)
self.vocab_start_idx = rank * self.part_vocab_size
self.vocab_end_idx = self.vocab_start_idx + self.part_vocab_size
self.weight = nn.Parameter(torch.empty(self.part_vocab_size, self.dim))
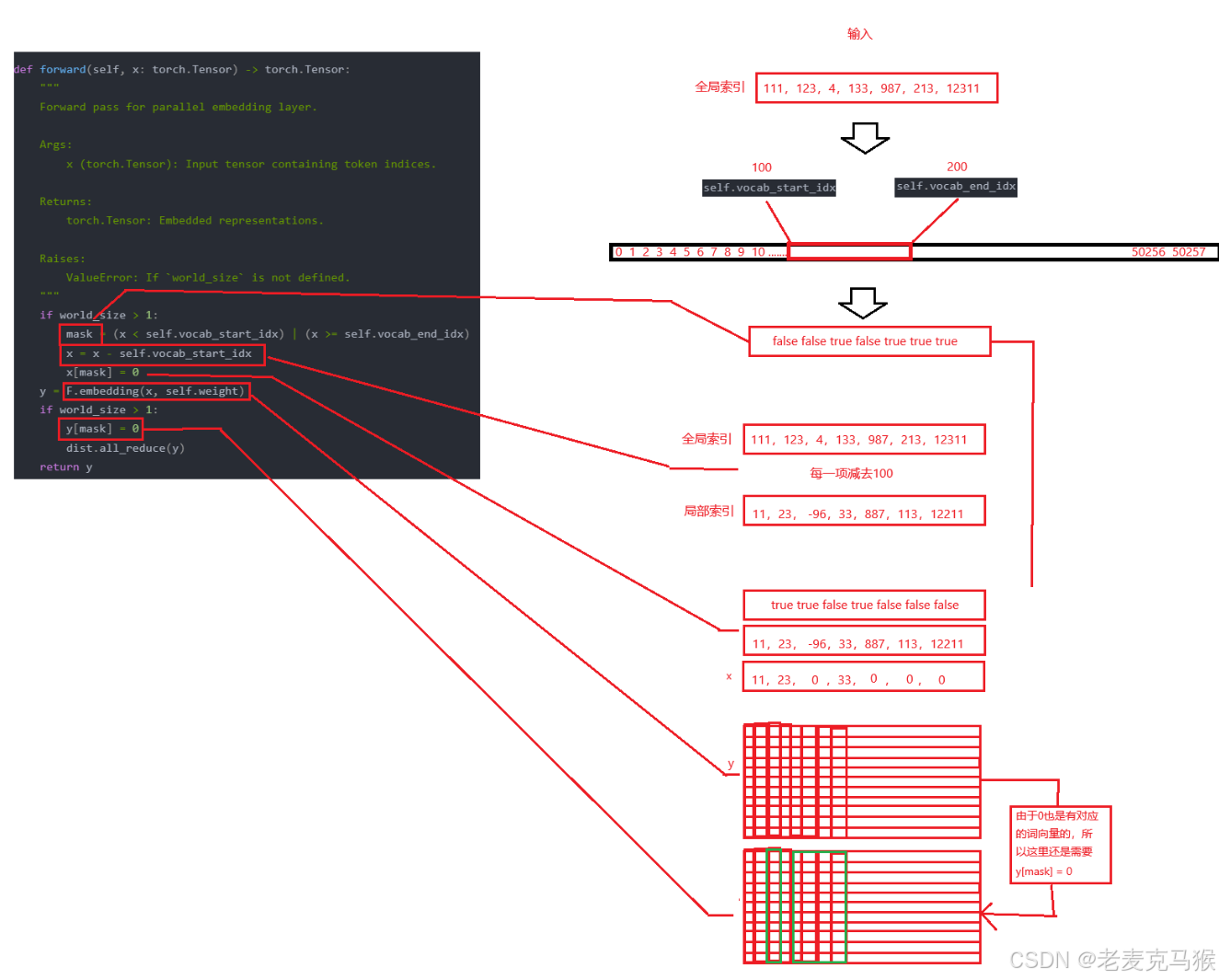
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Forward pass for parallel embedding layer.
Args:
x (torch.Tensor): Input tensor containing token indices.
Returns:
torch.Tensor: Embedded representations.
Raises:
ValueError: If `world_size` is not defined.
"""
if world_size > 1:
mask = (x < self.vocab_start_idx) | (x >= self.vocab_end_idx)
x = x - self.vocab_start_idx
x[mask] = 0
y = F.embedding(x, self.weight)
if world_size > 1:
y[mask] = 0
dist.all_reduce(y)
return y
多进程
# 关键点在于:代码本身不会自动变成多进程,而是需要你主动启动多个进程。这通常由 torch.multiprocessing.spawn
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import os
# World Size:进程总数。
# Rank:当前进程的编号。
def run(rank, world_size):
# 设置主节点地址和端口
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
# dist.init_process_group 是 PyTorch 分布式模块中的一个函数
# 有多少个进程在干活(world_size),自己是第几个进程(rank)。
dist.init_process_group(backend='gloo', rank=rank, world_size=world_size)
# 进程 0 发送数据,进程 1 接收数据
if rank == 0:
tensor = torch.tensor([42])
dist.send(tensor, dst=1) # 发送给进程 1
print(f"进程 {rank} 发送了: {tensor}")
elif rank == 1:
tensor = torch.zeros(1, dtype=torch.long)
dist.recv(tensor, src=0) # 从进程 0 接收
print(f"进程 {rank} 接收到: {tensor}")
# 清理
dist.destroy_process_group()
if __name__ == "__main__":
world_size = 2
mp.spawn(run, args=(world_size,), nprocs=world_size, join=True)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









